






使用注意力和差异机制的基于外观的注视估计
前言
本文为翻译搬砖和总结一些自己的心得体会。
作者:
发布于2021年
摘要
基于外观的注视估计问题在过去几年中受到了广泛的关注。尽管基于模型的方法存在得更早,但大数据集的可用性和新颖的深度学习技术使得基于外观的方法比基于模型的方式实现了更高的准确性。在本文中,我们提出了两种提高视线估计精度的新技术。我们的第一种方法,I2D Net使用差异层来消除参与者左眼和右眼中与注视估计任务无关的任何共同特征。我们的第二种方法AGE Net采用了注意力机制的思想,并为从眼睛图像中提取的特征分配权重。I2D Net的性能与现有的最先进方法相当,而AGE Net报告的最先进精度为4.09° 和7.44° MPI-IGaze和RT基因数据集上的错误。我们进行了消融研究,以了解所提出的方法的有效性,然后分析了与MPIIGaze数据集的各种因素有关的注视误差分布。
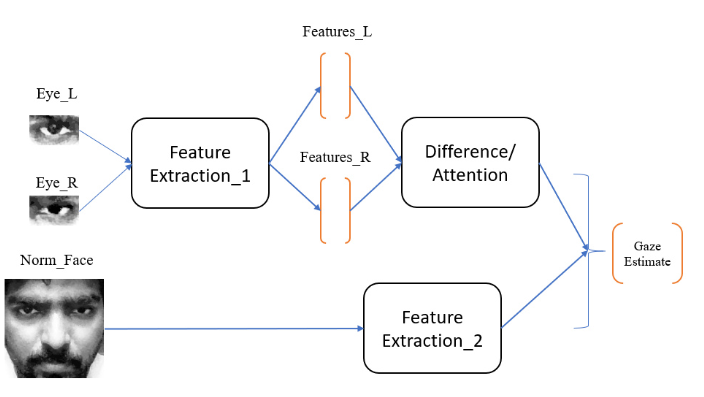
图1.所提出方法的说明。对从左眼和右眼图像中提取的特征进行特征操作
1. 介绍
估计一个人在看什么的能力会带来很多机会。一些例子包括理解人类视觉,如视觉扫描路径分析[15]、阅读分析[7]和阅读障碍筛查[27]。该技术还使我们能够在汽车[29]、航空[26]和无障碍[30,8]等各个领域开发人机交互的新应用。尽管早期出现了眼电描记术等各种技术[6],但成像技术和先进的计算机视觉技术的使用使我们能够以非侵入性的方式估计注视。商业眼睛注视跟踪器依靠基于红外的成像来获得眼睛图像,以规避环境照明的影响。这些商用注视跟踪器声称,在真实使用条件下,95%的人群的注视精度误差小于1.9°[2] 并且已经使用这种注视跟踪系统来部署应用程序,以控制Windows PC上的光标移动[3]。
最近的视线估计研究集中于利用商品硬件,如网络摄像头或随处可见的手机和平板电脑设备中的前置摄像头。由于这种方法不需要额外的硬件(如红外照明器),因此在这一方向上的进步使得视线跟踪能够覆盖更广泛的用户群体。
凝视估计文献可分为基于特征、基于模型和基于外观的方法[19]。针对3D和2D凝视估计问题,提出了许多基于模型和外观的方法,最近的研究[40]表明,基于外观的方法比基于模型的方法获得了更好的凝视估计精度。这是因为有大量数据集和新颖的深度学习技术。在本文中,我们提出了两种特征融合方法,即I2D网和AGE网,以提高视线估计精度。第一种方法,I2D Net基于这样一种直觉,即省略从眼睛图像中提取的任何与人相关的特征,将有助于深度神经网络模型更好地概括不可见的用户。该方法假设这些与人相关的外观相关的特征存在于左眼和右眼图像中,因此获得左眼和左眼特征的差异应允许我们省略此类特定于人的信息,仅保留与人无关的凝视估计相关的特征。
我们的第二种特征操作方法AGE Net是受注意力机制的启发,最初是为神经机器翻译任务提出的。注意机制使模型能够搜索源句中最相关信息集中的一组位置[4]。我们采用这种软选择特征的思想来执行注视估计,而不是使用从眼睛图像中提取的所有特征。我们认为,在输入图像包含外观、照明和头部姿势变化的情况下,这尤其重要。我们提出的方法有两个分支,一个是特征提取分支,另一个是注意力分支,它们分别产生相同维度的特征向量和权重向量。权重向量为特征向量的每个特征分配权重,以指示它们与给定图像的相关性。
我们在MPIIGaze[42]和RT Gene[16]数据集上使用这两种方法进行了实验。我们证明,所提出的特征操纵技术在标准评估协议下实现了最先进的结果。我们使用消融研究分析了所提出方法的有效性。我们还比较了AGE-Net和I2D Net在照明、头部姿势变化等因素下的性能。
我们将本文的贡献总结如下:
• 我们提出了使用差异层和AGE-Net自适应注意力机制进行注视估计的I2D网络。
• I2D-Net在使用较少参数的同时,与现有最先进的方法实现了不相上下的性能(∼87M)。
• 建议的AGE网络达到了4.09的最先进性能◦ 和7.4◦ MPIIGaze和RT Gene数据集错误,使用∼105M参数。
在下一节2中,我们将回顾现有的视线估计方法。在第3节中,我们提出了与网络架构相关的详细方法。我们在第4节中介绍了在MPI-IGaze和RT基因数据集上进行的实验,以及结果和消融研究。我们在第5节中对两种建议的方法进行了分析。第6节包含对所提出工作的讨论,第7节中给出了结论。
2. 相关工作
2.1. 基于特征和模型的方法
像Tobii X系列[2]这样的商业注视跟踪器是基于特征的系统。使用亮瞳或暗瞳方法[1]的外部IR光源用于获得眼睛特征,如角膜反射[18],以进行凝视估计。另一方面,基于模型的方法从眼睛图像中提取视觉特征,如瞳孔中心、虹膜轮廓和眼角,以拟合几何3D眼睛模型来执行凝视估计。早期的基于模型的方法使用红外照明器和高分辨率相机[20,37],但最近的方法[33,28,5]通过从网络摄像头图像中提取特征来克服这些要求。他们还使用机器学习方法增强其特征检测器,以获得关于照明变化的鲁棒性。
2.2. 基于外观的方法
与前面提到的方法不同,基于外观的方法尝试将使用商品相机捕获的图像直接映射到凝视方向向量,而不需要任何手工制作的特征。这些基于外观的方法得到了大型数据集[17,42,16,21]的创建和深度学习技术的进步的有力支持。我们可以将目前提出的基于外观的方法分为单通道和多通道方法。
基于外观的凝视估计的第一次尝试之一是GazeNet[42],这是一种单通道方法,其中使用单眼图像作为基于16层VGG CNN的架构的输入。头部姿势信息在卷积层之后连接到第一个完全连接的层。GazeNet报告了MPIIGaze评估子集的5.4°平均角度误差,称为MPIIGaze+。这项工作之后是空间权重CNN,这是另一种单通道方法[41],其中提供全脸图像作为输入,而不是眼睛裁剪。他们使用空间权重技术来给出与视线估计相关的面部区域的重要性。
作为单通道方法的替代方案,提出了许多多通道方法。iTracker[23]是第一个使用左眼图像、右眼图像、面部裁剪图像和面部网格信息作为输入的多通道架构之一。Chen和Shi[9]提出的多区域扩张网络在他们提出的模型中使用了扩张卷积,并使用两个眼睛图像和面部图像作为输入。该方法也报告了4.8°的相同结果。交叉参与者评估中MPIIGaze+的平均角度误差[41]。此外,他们通过提出GEDDNet[10]扩展了他们的工作,该网络使用凝视去合成和扩张卷积,并报告了MPIIGaze+的4.5°误差。基于多通道架构的最新工作是FAR*-Net[12],其提出利用同一个人双眼之间的不对称性来获得注视估计。在这项工作中,他们为从两眼图像中获得的凝视估计值生成了置信度分数,以选择更准确的预测。
Wang等人[34]提出使用贝叶斯框架比基于外观的方法更好地概括视线估计性能。他们建议使用一个基于CNN的凝视估计器和一个通用组件来学习可概括的凝视响应特征。
上述大多数工作都直接使用从眼睛和面部图像中提取的特征进行凝视向量回归。我们观察到,只有空间权重CNN[41]和贝叶斯方法[34]建议采用专注于获得与凝视估计相关的特征的特征提取。由于除了固有的特定于人的变化之外,照明和头部姿势变化方面的巨大变化,我们相信特定于人或特定于图像的特征操纵可以导致获得更准确的注视估计。
在下一节中,我们介绍了我们提出的基于差异和注意力机制的特征操纵方法。
3. 建议的方法
3.1. I2D网络
使用扩展和差分层网络(I2D Net)的I-Gaze估计主要依赖于两个模块。Chen和Shi[9]表明,使用扩张卷积而不是规则卷积来提取特征可以提高视线估计的准确性。他们认为,一系列的最大化层可能无法捕捉到眼睛图像中的更精细的细节,而这些细节对视线估计很重要。他们还认为,扩张卷积保留了特征图的分辨率,同时获得了更大的感受野,这与使用最大池层相反,在最大池层中,以特征图分辨率为代价获得了更高的感受野。
第二模块是差分层,其获得使用扩张卷积提取的左眼和右眼特征的绝对差。Zeiler和Fergus[38]证明,较浅的神经网络层包含低级别信息,如边缘和低级别图像,而较深层的神经网络试图学习更高级别的特征,如具有显著姿态变化的物体部分。在一个具体的例子中,他们表明,当AlexNet[24]第4层的特征图被可视化时,狗的眼睛和鼻子已经被观察到。基于这一观察,我们提出了以下方法。
我们使用共享卷积层从归一化的右眼和左眼图像中提取特征。该特征提取网络如图2c所示,其中我们使用了扩展卷积层。我们从基线[9]改变了每层特征图的数量和扩张率,并向面部通道添加了扩张卷积(图2e)。
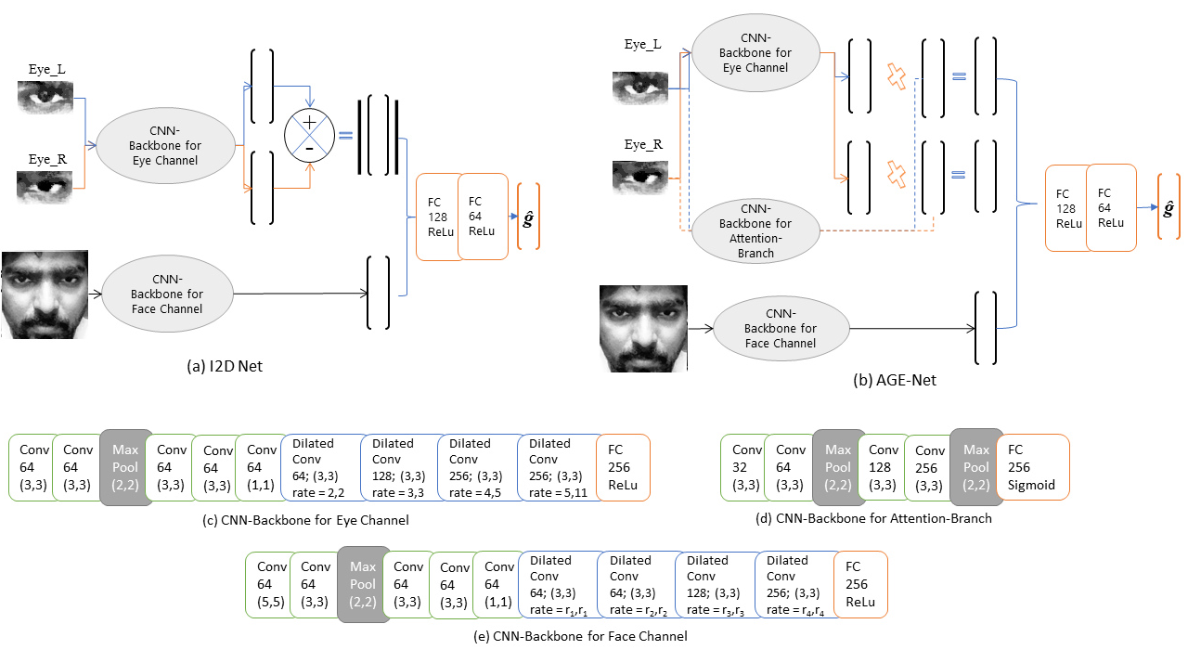
图2. 所提出方法的网络架构。(2a)I2D网络架构(2b)AGE网络架构(2c)CNN眼睛频道主干(2d)CNN注意力分支主干(2e)CNN面部频道主干。
这些获得的特征图可能包含更高级别的特征,这些特征编码关于眼睛图像的各个部分(如眼球、巩膜区域或眉毛区域)的信息。这种更精细的细节因人而异,并且存在于左眼和右眼图像中。我们认为,从左眼和右眼图像中获取这些提取的特征的绝对差异会去除常见的、冗余的外观相关信息,因此只保留双眼的相关特征。我们假设,与来自双眼的特征被连接用于随后的完全连接层的情况相比,合成的特征向量充当更好的特征变换。I2D网络的整个网络架构如图2a所示。
读者可能会注意到,该方法与Diff NN[25]在本质上不同。我们专注于改进独立于人的注视估计任务,我们不像[25]那样依赖于任何特定于人的校准样本。此外,Diff NN建议使用属于同一只眼睛(左或右)的图像,并训练模型以学习注视差异。我们建议获得从同一个人的左眼和右眼提取的特征之间的差异,以避免依赖于人的特征。
3.2.AGE-Net
基于注意力的注视估计网络(AGE-Net)建议调整自然语言处理(NLP)、计算机视觉[36]任务、语音系统[13]、推荐系统[32]中使用的注意力机制,并预测自动驾驶汽车的转向角[22]。在神经机器翻译任务中,编码器为给定的输入句子生成注释,然后由解码器使用注释生成不同语言的输出句子。Bahdanau等人提出了注意机制[4],以从输入句子中选择对翻译任务有意义的特定单词。他们建议使用加权注释序列,而不是按原样使用它们来生成输出序列。
将此思想应用于凝视估计任务,我们建议为从眼睛图像中提取的特征分配权重。我们建议在特征提取分支的同时添加一个注意分支,以执行预期的特征操作。特征提取分支和注意力分支都包含以眼睛图像为输入的共享卷积层。图2c所示的特征提取分支从左眼和右眼图像中产生特征向量,而注意力分支为左眼和左眼特征提供必要的权重向量。我们对注意力分支的最后一层使用了S形激活函数,如图2d所示,以获得值在(0-1)范围内的权重向量。从双眼获得的特征向量与相应的权重向量相乘,以获得加权特征,该加权特征将进一步通过网络进行回归任务。AGE-Net架构如图2b所示。
图2c、2d和2e表示各种参数值对于架构的每一层,如特征图大小、卷积核大小和全连接层的激活函数。我们对所有卷积和扩张卷积层使用ReLu激活函数。面部通道的扩张率参数r1、r2、r3和r4(图2e)假设AGE Net和I2D Net的值不同。我们对AGE Net的r1、r2、r3和r4分别使用了3、5、7和11。在I2D Net的情况下,这些参数取2、3、5和11个值作为膨胀率。标准化的面部图像首先通过在ImageNet数据集[14]上预训练的VGG Net[31]的前六层,然后将其馈送到面部频道的CNN主干(图2e)。我们提出的架构中的每一层之后都是批处理规范化。
4. 实验 - I2D-Net和AGE Net
4.1. 数据集
MPIIGaze
我们在MPIIGaze上进行了实验,这是在真实世界条件下收集的,具有照明和头部姿势变化。数据集收集了来自不同种族背景的15人,包括戴眼镜等外观变化。我们使用地标注释[41]对来自MPI-IGaze[42]评估子集的面部和眼部图像进行了标准化。数据集的评估子集总共包含45000个样本,每个人有3000个样本。
我们使用[39]中提到的方法对图像和地面真实凝视标签进行归一化。总之,正常化过程消除了捕获图像中头部姿态的滚动分量,并将图像定位在距虚拟相机的期望距离dv处,焦距为fv。除了图像归一化,我们还将地面真实凝视标签从相机坐标系转换为具有角度表示的归一化空间。我们使用dv作为眼睛图像标准化的600,面部图像的1000。我们选择标准化眼睛图像的分辨率为36x60,而标准化面部图像为120x120。此外,我们选择眼睛和面部标准化的fv为960。我们对结果图像应用直方图均衡,以获得将用于后续阶段的标准化眼睛和面部图像。
RT-Gene
RT Gene[16]数据集包含122531张使用可佩戴眼动眼镜的15名参与者的图像。与MPIIGaze数据集不同,参与者坐在电脑附近,他们位于距离在此数据集创建过程中的相机0.5到2.9米的距离。该数据集在头部姿势和注视角度方面也具有较高的变化。由于RT Gene数据集中捕获的图像包含与人一起使用的眼动眼镜,因此他们使用语义内画来绘制带有皮肤纹理的眼动眼镜覆盖的区域。因此,作者在对图像进行标准化后,提供了图像的原始版本和绘画版本。归一化的眼睛和面部图像的分辨率分别为36x60和224x224。除了将面部图像调整为120x120之外,我们没有对这些图像进行任何进一步处理。我们观察到[12]报道的绘制集中的噪声,因此仅使用原始数据集进行实验。我们在两个数据集上的所有实验都使用了灰度图像。
4.2. 训练及结果
我们使用两个提出的模型对MPI-IGaze进行了省略一个交叉验证,如其他工作[41,12,9]中所述。我们将一名参与者排除在外进行测试,并考虑其他14名参与者进行培训。我们使用Tensorflow和Keras实现了所提出的模型。我们使用了15%的训练数据进行验证分割。由于大多数注视标签小于1,我们将它们放大100,并使用均方误差作为损失函数。我们对每个模型进行了30个时期的训练,批量大小为32,我们使用了Adam优化器。
我们根据数据集提供的评估协议在RT Gene数据集上进行了实验。我们将原始数据集分成3个折叠,并进行了3个折叠交叉验证。我们遵循了与MPIIGaze数据集类似的训练过程,但由于训练样本数量较多,我们对模型进行了50个时期的训练。
我们在MPIIGaze和RT Gene数据集上展示了所提出方法的实验结果,并将其与表1中使用面部或多通道方法的各种注视估计方法进行了比较。所提出的I2D Net在MPIIGaze和RT Gene上实现了4.3±0.97和8.44±1.08度的平均角误差数据集。在两个数据集上,I2D Net与FAR*Net[12]和贝叶斯高级学习方法[34]等现有技术方法不相上下。由于我们在特征提取阶段使用了扩张卷积,我们将扩张网络[9]视为我们的基线,因此I2D网络中提出的差分特征变换比基线提高了10%。Diff NN[25]在使用9个参考样本和4.64个默认参数设置应用自适应方法后报告了4.59°平均误差。因此,所提出的具有提取的特征的差异层的I2D网络报告了比Diff NN更好的性能,Diff NN建议使用人的两个相同眼睛图像来学习注视差异。
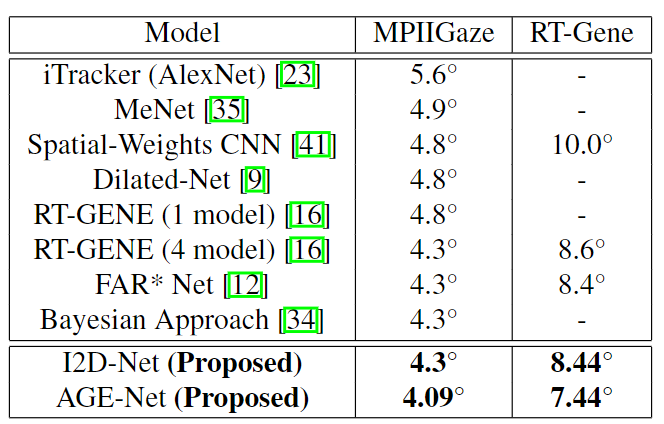
表1.与现有Gaze估计模型的比较。
另一种提出的方法,AGE Net在MPIIGaze和RT Gene数据集上分别实现了4.09±0.9度和7.44±1.59度的平均角度误差。我们推断,所提出的为提取的特征分配权重的注意力分支在基线上将总体平均角误差提高了14.8%。与现有技术相比,AGE Net在MPIIGaze和RT Gene数据集上分别实现了约5%和11.5%的改进。
除此之外,所提出的方法I2D Net(∼87M)和AGE Net(∼105M)比FAR*Net等同类产品使用更少的参数[12](∼848M),空间权重CNN[41](∼196M),基因[16](∼122M)和GEDD净值[10](∼107M),因此这些方法导致较低的存储器占用。
4.3. 消融研究
我们通过使用MPIIGaze数据集进行消融研究,研究了形成所提出架构的各种模块的重要性。
AGE Net表2总结了AGE Net的消融研究结果。首先,如图2c和图2e所示,我们在没有建议的注意力分支的情况下单独使用面部和眼睛通道的CNN主干进行实验,并观察到4.54°的误差。我们已经从基线[9]改变了每个层中使用的特征数量和膨胀率,并形成了这些CNN主干。然而,其性能与GEDDNet[10]不相上下,GEDDNet利用了扩张卷积和注视分解技术。接下来,我们在不使用面部信息的情况下,使用CNN主干和注意力分支进行眼睛通道实验,并观察到4.64°的误差。
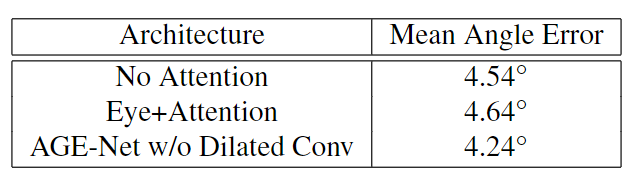
表2.MPIIGaze上AGE Net的消融研究结果
然后,我们尝试调查所提出的AGE网络架构中的扩张卷积的重要性。我们重新设计了架构,以实现90%的输入大小作为接收场,而不使用扩张卷积。首先,将面部和眼部通道中的所有扩张卷积层替换为规则卷积层。我们在眼睛通道中又增加了两个最大池层,分别在第七和第八卷积层之后。此外,我们在人脸通道中又添加了三个最大池层,分别在第四、第六和第八卷积层之后添加了一个。我们使用该方法获得了4.24°的误差,这表明扩张卷积确实有助于所提出的网络实现更好的性能。总之,注意力分支到CNN主干的存在将视线估计精度提高了10%,而扩张卷积的存在将精度提高了3.5%。
I2D Net我们研究了I2D Net的差异层和面通道的意义。我们首先使用图2a中所示的CNN主干进行了实验,其中包括眼睛通道和面部通道,并没有差异层。该模型记录了4.6°的误差,与AGE Net使用的CNN主干线相比略有下降,可能是由于不同的膨胀率。这表明,差异层的存在将性能提高了6.5%。
从拟议的I2D网络中排除面部通道导致5.08°误差。我们观察到,从两种提出的架构中省略面信息会导致性能显著下降。然而,与其他仅用眼睛的方法相比,没有面部通道的AGE-Net获得了更好的注视误差。如表3所示,基于眼睛图像的方法,如Gaze Net[42]、AR Net和ARE Net[11],分别报告了5.4、5.65和5.02度的误差,而AGE Net和I2D Net在没有面部信息的情况下分别实现了4.64和5.08度的误差。
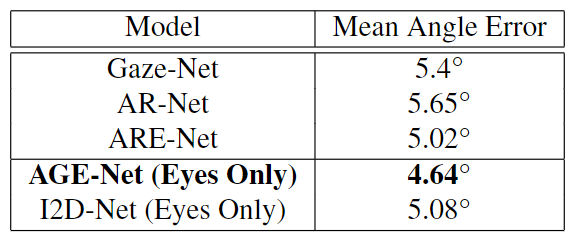
表3.比较MPIIGaze上基于眼睛图像的方法。
5. 分析
在本节中,我们分析了MPIIGaze中关于个体参与者、照度水平、平均照度水平差异、注视点和头部姿势的建议方法,因为RT Gene没有报道照度变化等因素。我们还对AGE Net和I2D Net进行了比较分析,以了解AGE Net比I2D Net表现更好的领域。
5.1. MPIIGaze的参与者分析
我们分析了MPIIGaz数据集的每个参与者的各种注视估计方法的性能。我们观察到,除了p03、p07和p09之外,这两种方法的性能都优于基线。此外,在图3中,我们将我们提出的方法与FARE Net进行了比较[12]。在15名参与者中,AGE Net在11名参与者中表现更好,而I2D Net在9名参与者中比FARE Net表现更好。我们进行了配对t检验,结果表明,I2D网络(t[14]=2.17,p=0.047,Cohen’s d=0.5)和AGE网络(t[24]=2.84,p=0.01,Cohen‘s d=0.7)在统计学上均优于基线[9]。此外,据观察,与另一种基于眼睛图像的方法ARE Net[12]相比,无面部通道的AGE Net在统计学上表现得更好(t[14]=2.72,p=0.016,Cohen的d=0.36)。
我们还分析了每个参与者的偏航和俯仰误差。我们观察到AGE Net和I2D Net的绝对平均偏航误差分别为2.66和3.042度,绝对平均俯仰误差分别为2.56和2.98度。
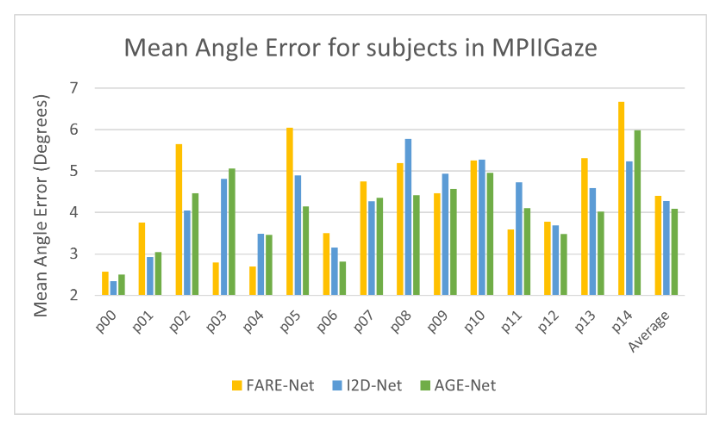
图3.MPIIGaze的参与者准确性
5.2. 照明的影响
我们分析了MPIIGaze数据集上跨参与者评估期间获得的关于面部图像的平均强度的注视误差。为此,我们将平均强度值分组到宽度为5的箱中,并相应地对图像进行分组。我们获得了每个仓对应的平均注视误差,并在图4中绘制了I2D Net和AGE Net的相同图,我们省略了第一个仓的平均注视误差[0-5),因为I2D Net和AGE Net分别报告了23.9和18.9度的误差。我们观察到,对于60到210之间的平均强度,I2D Net的注视误差和AGE Net的注视误差分别在3.96±0.4和3.85±0.33度的范围内,表明模型在宽范围的光照变化中的泛化性能当平均强度超过(5-200)范围时,亮度增加。这可能是由于数据集特征中报告的上述范围内的训练样本数量较少[42]。
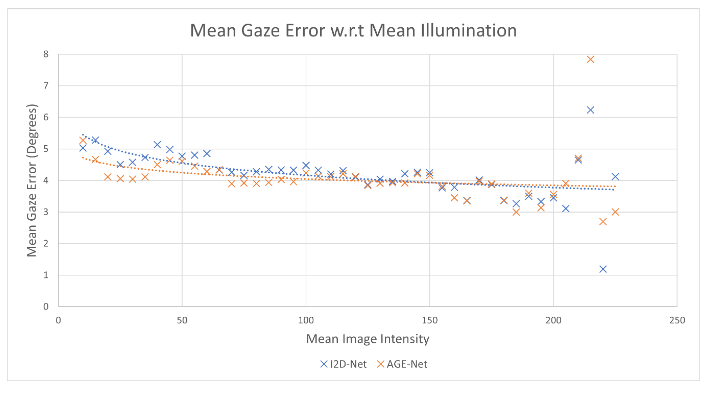
图4.相对照度下的凝视误差分布
5.3. 照明水平差异的影响
MPIIGaze数据集捕获的一个具有挑战性的场景是整个面部图像的照明水平差异。我们分析了在这种情况下提出的方法的性能。我们使用了第5.2节中描述的类似方法,并将结果绘制在图5中。我们无法从图4中直观地检查两种建议方法的趋势线之间的差异,但在图5,很明显AGE Net报告的平均注视误差低于I2D Net。我们观察到AGE Net报告的注视误差在[-135,-50]和[80,135]范围内低于I2D Net。两种提出的方法的平均注视误差在水平强度差上的趋势线接近于一条平坦线,反映了模型在水平照度差范围内的泛化能力。
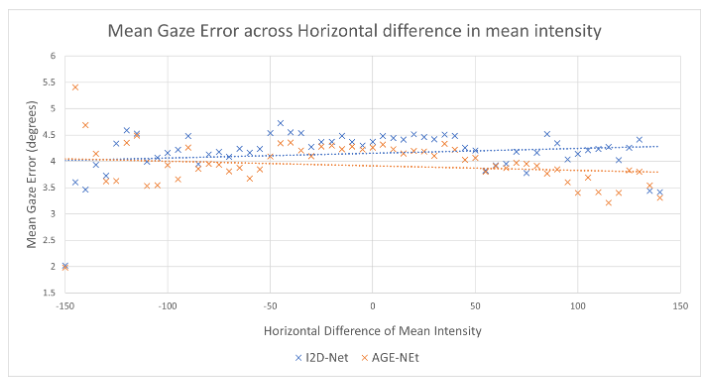
图5.相对于平均强度差的凝视误差分布
5.4. 注视方向的影响
注视估计系统的性能也可能会根据人注视的位置而变化。我们基于地面真实凝视方向研究了我们提出的模型的注视误差。我们将地面真实注视俯仰和偏航分量分成5个单元,因此我们将整个归一化注视空间分成25个单元的网格。我们将落在这25个单元格中的输入图像分组,并获得每个单元格的平均注视误差。在图6和图7中,我们分别通过AGE Net和I2D Net显示了所有25个格子的平均注视误差。我们可以在图6中观察到AGE-Net的注视误差随着俯仰角的增加而明显单调增加,但是在图7中没有观察到I2D Net的这种模式。两种提出的方法都报告了与偏航角变化相关的平均注视误差的相似趋势,并报告了沿中心柱的最佳精度。
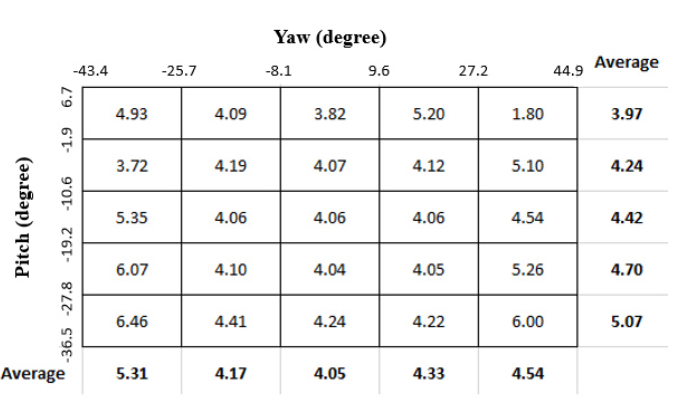
图6.凝视区域AGE Net的凝视误差分析
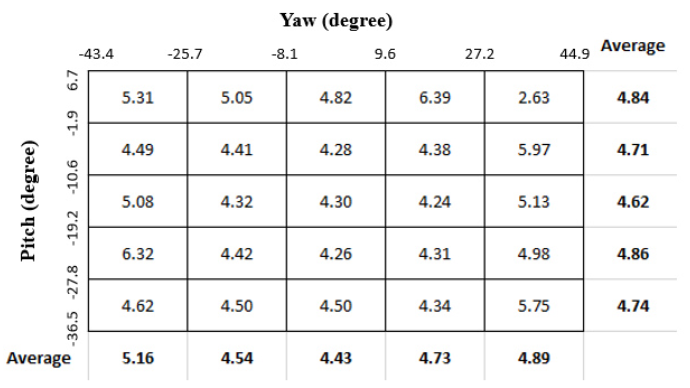
图7.凝视区域的凝视误差分析-I2D Net
5.5. 头部姿势的影响
我们研究了所提出的模型在参与者头部姿势方面的表现,这是数据集中的一个重要变量。与5.4中给出的基于注视位置的分析类似,我们将头部方位的整个偏航和俯仰范围划分为50个单元,因此标准化头部姿态空间被划分为总共2500个单元。我们对这些格子的图像进行了聚类,我们认为这些细胞至少有三张图像。我们从AGE Net和I2D-Net每个单元格的净值获得了平均注视误差,分别在图8和图9中绘制。相比之下,AGE-Net在头部姿态方面的注视误差分布比I2D-Net更均匀。此外,具有高平均注视误差的簇只能位于头部姿态分布的边界上,这表明极端的头部姿态会导致高注视预失真误差。对于AGE Net,这意味着识别了头部姿态变化的清晰区域,如图8中的黑线所示,这将导致视线误差几乎均匀分布。当为实时使用而部署此模型时,这些区域有助于定义操作范围。
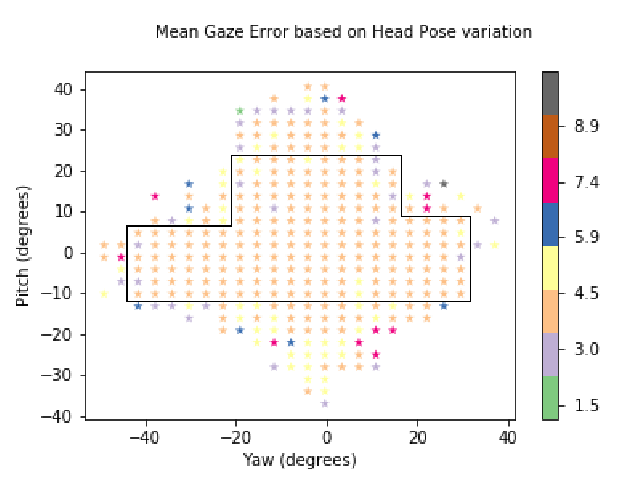
图8.头部姿势AGE Net的凝视误差
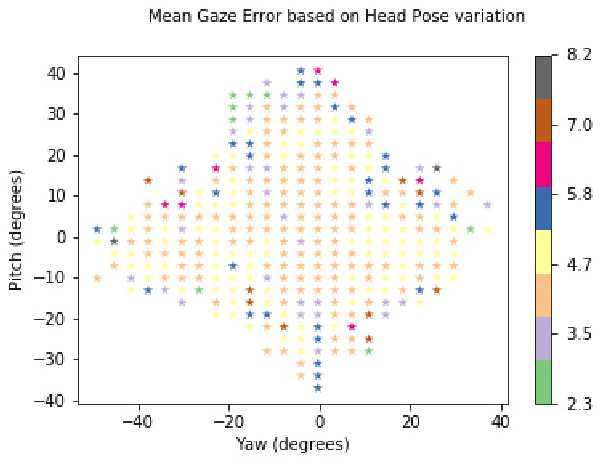
图9.头部姿势-I2D-Net的凝视误差
6. 讨论
我们的第一种特征操纵方法I2D Net在MPIIGaze和RT Gene数据集上与FAR*Net等现有最先进的方法具有同等性能,而另一种特征操纵方式AGE Net在这两个数据集上都报告了最先进的性能。除此之外,基于第5节中的分析,AGE Net还发现其比I2D Net具有更好的泛化性能。两种方法都报告了在水平照明差异范围内的注视误差的平坦趋势,以及在平均照明范围内的线性趋势。此外,使用AGE Net对头部姿势的视线误差分布提供了一个具有均匀误差的清晰界限,这在定义实时交互时的操作范围时非常有用。AGENet还报告了随着注视方向的音高分量增加,误差增加的明显趋势。这可能是由于当注视向量的间距分量较高时,眼睑遮挡了眼球区域。由于大多数现有的笔记本电脑和平板电脑都将摄像头放置在屏幕上方,因此需要克服这一限制,以在整个观看范围内获得一致的注视误差。
我们使用∼27M参数,与AGE Net的4.09相比,误差为4.24∼105M参数。这种方法可以进一步研究我们是否可以用较少的参数来改善注视误差。这种较小的内存占用模型可用于实现对实时注视估计的高端GPU的较低延迟和较不严格的要求。当前AGE Net系统的实时演示可在https://youtu.be/2pyX6O2xTFw.另一方面,在我们提出的架构中,我们没有将注意力分支用于面部通道,这是另一种探索途径。
在第5节中,我们比较并分析了所提出的方法在MPIIGaze数据集中的各种参数方面的性能。我们对注视误差进行了聚类分析,而不是单个图像分析。尽管我们获得了每个参数的注视误差的宏观趋势,但仍需要进一步研究,以了解报告高误差的图像背后的因素。这种故障模式分析有助于理解固有视觉-光轴偏移的影响以及模型在观测到的注视误差中的缺点,从而建立鲁棒的注视估计模型。
7. 结论
在本文中,我们提出了基于差分特征向量和注意力机制的特征操作技术,用于基于外观的注视估计任务。与MPIIGaze和RT-Gene数据集上现有的最先进方法相比,所提出的I2D Net报告了同等性能,AGE-Net报告了优异的性能。我们的方法还显示了对各种因素的鲁棒性,如照度、头部姿势和平均强度的水平差异。此外,我们还通过消融研究证明了所提出技术的重要性。最后,我们讨论了我们提出的方法的含义和前景扩展,以进一步提高视线估计的准确性。
参考文献
[1] Dark and bright pupil tracking. https://www.tobiipro.com/learn-and-support/learn/eye-tracking-essentials/what-is-dark-and-bright-pupil-tracking/.Accessed: 2021-03-27.
[2] Tobii dynavox pceye mini. http://tdvox.webdownloads.s3.amazonaws.com/PCEye/documents/TobiiDynavox_PCEyeMini_UserManual_v1-2_en-US_WEB.pdf.Accessed:2021-03-08.
[3] Windows control - tobii dynavox.https://www.tobiidynavox.com/software/windows-software/windows-control-software/. Accessed: 2021-03-19.
[4] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio.Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473, 2014.
[5] Tadas Baltrusaitis, Amir Zadeh, Yao Chong Lim, and Louis-Philippe Morency. Openface 2.0: Facial behavior analysis toolkit. In 2018 13th IEEE International Conference on Au-tomatic Face & Gesture Recognition (FG 2018), pages 59–66. IEEE, 2018.
[6] Rafael Barea, Luciano Boquete, Manuel Mazo, and ElenaL ́opez. System for assisted mobility using eye movements based on electrooculography. IEEE transactions on neural systems and rehabilitation engineering, 10(4):209–218,2002.
[7] David Beymer and Daniel M Russell. Webgazeanalyzer: a system for capturing and analyzing web reading behavior using eye gaze. In CHI’05 extended abstracts on Human factors in computing systems, pages 1913–1916, 2005.
[8] Maria Borgestig, Jan Sandqvist, Gunnar Ahlsten, Torbj ̈orn Falkmer, and Helena Hemmingsson. Gaze-based assistive technology in daily activities in children with severe physical impairments–an intervention study. Developmental Neurorehabilitation, 20(3):129–141, 2017.
[9] Zhaokang Chen and Bertram E Shi. Appearance-based gaze estimation using dilated-convolutions. In Asian Conference on Computer Vision, pages 309–324. Springer, 2018.
[10] Zhaokang Chen and Bertram E Shi. Geddnet: A network for gaze estimation with dilation and decomposition. arXiv preprint arXiv:2001.09284, 2020.
[11] Yihua Cheng, Feng Lu, and Xucong Zhang. Appearance-based gaze estimation via evaluation-guided asymmetric regression. In Proceedings of the European Conference on Computer Vision (ECCV), pages 100–115, 2018.
[12] Yihua Cheng, Xucong Zhang, Feng Lu, and Yoichi Sato.Gaze estimation by exploring two-eye asymmetry. IEEE Transactions on Image Processing, 29:5259–5272, 2020.
[13] Jan Chorowski, Dzmitry Bahdanau, Dmitriy Serdyuk, Kyunghyun Cho, and Yoshua Bengio. Attention-based models for speech recognition. arXiv preprint arXiv:1506.07503, 2015.
[14] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
[15] Sukru Eraslan, Yeliz Yesilada, and Simon Harper. Eye tracking scanpath analysis techniques on web pages: A survey, evaluation and comparison. Journal of Eye Movement Research, 9(1), 2016.
[16] Tobias Fischer, Hyung Jin Chang, and Yiannis Demiris. Rtgene: Real-time eye gaze estimation in natural environments.In Proceedings of the European Conference on Computer Vision (ECCV), pages 334–352, 2018.
[17] Kenneth Alberto Funes Mora, Florent Monay, and JeanMarc Odobez. Eyediap: A database for the development and evaluation of gaze estimation algorithms from rgb and rgb-d cameras. In Proceedings of the Symposium on Eye Tracking Research and Applications, pages 255–258, 2014.
[18] Elias Daniel Guestrin and Moshe Eizenman. General theory of remote gaze estimation using the pupil center and corneal reflections. IEEE Transactions on biomedical engineering,
53(6):1124–1133, 2006.
[19] Dan Witzner Hansen and Qiang Ji. In the eye of the beholder: A survey of models for eyes and gaze. IEEE transactions on pattern analysis and machine intelligence, 32(3):478–500, 2009.
[20] Takahiro Ishikawa. Passive driver gaze tracking with active appearance models. 2004.
[21] Petr Kellnhofer, Adria Recasens, Simon Stent, Wojciech Matusik, and Antonio Torralba. Gaze360: Physically unconstrained gaze estimation in the wild. In Proceedings of the IEEE International Conference on Computer Vision, pages 6912–6921, 2019.
[22] Jinkyu Kim and John Canny. Interpretable learning for selfdriving cars by visualizing causal attention. In Proceedings of the IEEE international conference on computer vision, pages 2942–2950, 2017.
[23] Kyle Krafka, Aditya Khosla, Petr Kellnhofer, Harini Kannan, Suchendra Bhandarkar, Wojciech Matusik, and Antonio Torralba. Eye tracking for everyone. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2176–2184, 2016.
[24] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25:1097–1105, 2012.
[25] Gang Liu, Yu Yu, Kenneth Alberto Funes Mora, and JeanMarc Odobez. A differential approach for gaze estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019.
[26] LRD Murthy, Abhishek Mukhopadhyay, Varshit Yellheti,Somnath Arjun, Peter Thomas, M Dilli Babu, Kamal Preet Singh Saluja, DV JeevithaShree, and Pradipta Biswas. Evaluating accuracy of eye gaze controlled interface in military aviation environment. In 2020 IEEE Aerospace Conference, pages 1–12. IEEE, 2020.
[27] Mattias Nilsson Benfatto, Gustaf ̈Oqvist Seimyr, Jan Ygge,Tony Pansell, Agneta Rydberg, and Christer Jacobson.Screening for dyslexia using eye tracking during reading.PloS one, 11(12):e0165508, 2016.
[28] Seonwook Park, Xucong Zhang, Andreas Bulling, and Otmar Hilliges. Learning to find eye region landmarks for remote gaze estimation in unconstrained settings. In Proceedings of the 2018 ACM Symposium on Eye Tracking Research & Applications, pages 1–10, 2018.
[29] Gowdham Prabhakar, Aparna Ramakrishnan, Modiksha Madan, LRD Murthy, Vinay Krishna Sharma, Sachin Deshmukh, and Pradipta Biswas. Interactive gaze and finger controlled hud for cars. Journal on Multimodal User Interfaces, 14(1):101–121, 2020.
[30] Vinay Krishna Sharma, LRD Murthy, KamalPreet Singh Saluja, Vimal Mollyn, Gourav Sharma, and Pradipta Biswas. Webcam controlled robotic arm for persons with ssmi. Technology and Disability, 32(3):1–19, 2020.
[31] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
[32] Yi Tay, Anh Tuan Luu, and Siu Cheung Hui. Multi-pointer co-attention networks for recommendation. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 2309–2318, 2018.
[33] Roberto Valenti, Nicu Sebe, and Theo Gevers. Combining head pose and eye location information for gaze estimation. IEEE Transactions on Image Processing, 21(2):802–815, 2011.
[34] Kang Wang, Rui Zhao, Hui Su, and Qiang Ji. Generalizing eye tracking with bayesian adversarial learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11907–11916, 2019.
[35] Yunyang Xiong, Hyunwoo J Kim, and Vikas Singh. Mixed effects neural networks (menets) with applications to gaze estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7743–7752, 2019.
[36] Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, and Yoshua Bengio. Show, attend and tell: Neural image caption generation with visual attention. In International conference on machine learning, pages 2048–2057. PMLR, 2015.
[37] Hirotake Yamazoe, Akira Utsumi, Tomoko Yonezawa, and Shinji Abe. Remote gaze estimation with a single camera based on facial-feature tracking without special calibration actions. In Proceedings of the 2008 symposium on Eye tracking research & applications, pages 245–250, 2008.
[38] Matthew D Zeiler and Rob Fergus. Visualizing and understanding convolutional networks. In European conference on computer vision, pages 818–833. Springer, 2014.
[39] Xucong Zhang, Yusuke Sugano, and Andreas Bulling. Revisiting data normalization for appearance-based gaze estimation. In Proc. International Symposium on Eye Tracking Research and Applications (ETRA), pages 12:1–12:9, 2018.
[40] Xucong Zhang, Yusuke Sugano, and Andreas Bulling. Evaluation of appearance-based methods and implications for gaze-based applications. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, pages1–13, 2019.
[41] Xucong Zhang, Yusuke Sugano, Mario Fritz, and Andreas Bulling. It’s written all over your face: Full-face appearance-based gaze estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Work-shops, pages 51–60, 2017.
[42] Xucong Zhang, Yusuke Sugano, Mario Fritz, and Andreas Bulling. Mpiigaze: Real-world dataset and deep appearance-based gaze estimation. IEEE transactions on pattern analysis and machine intelligence, 41(1):162–175, 2017.
博主总结
2021CVPR Workshop(Gaze Estimation and Prediction in the Wild)的一篇文章,文章中提出了使用扩张卷积和基于注意力的两种特征融合预估凝视点位置的一种方法,并且该文章做了有关两种方法的消融研究实验,且对比了特征信息(参与者、光照、注视方向、头部姿势)对注视误差的影响。总体来看是一篇中规中矩的文章,不失为一种科研论文的模板。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









