







文章目录
- 1. 批归一化(Batch Normalization,BN)
- 2. 组归一化(Group Normalization,GN):
- 3. 实例归一化(Instance Normalization,IN):
- 4. 层归一化(Layer Normalization,LN):
- 5. 权重归一化(Weight Normalization,WN):
- 6. 局部响应归一化(Local Response Normalization,LRN):
- 7. 通道间归一化(Cross-Channel Normalization,CCN):
- 8. 跨通道局部响应归一化(Cross-Map Local Response Normalization,CrossMapLRN):
1. 批归一化(Batch Normalization,BN)
BN层在训练时对每个mini-batch的输入数据进行归一化操作,使得每个神经元的激活值在数据分布上更加稳定。BN可以提高网络训练速度和效果,并具有正则化作用,能够一定程度上防止过拟合。其数学公式如下:
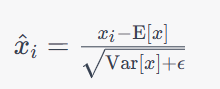
其中,
x
i
x_i
xi表示mini-batch中第
i
i
i个样本的输入数据,
E
[
x
]
\mathrm{E}[x]
E[x]表示mini-batch的均值,
V
a
r
[
x
]
\mathrm{Var}[x]
Var[x]表示mini-batch的方差,
ϵ
\epsilon
ϵ是一个非常小的常数(如
1
0
−
5
10^{-5}
10−5),以防止方差为零的情况。
在训练时,BN层还需要维护一个移动平均值和移动方差,用于在推理时对输入数据进行归一化操作。
torch.nn.BatchNorm1d()、torch.nn.BatchNorm2d()、torch.nn.BatchNorm3d()
2. 组归一化(Group Normalization,GN):
GN层将每个通道分成若干个组,然后对每个组内的数据进行归一化,从而使得每个组内的激活值相对独立。GN适用于较小的批量大小或通道数较少的情况,并且在训练和测试时具有相同的效果。其数学公式如下:
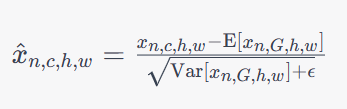
其中,
x
n
,
c
,
h
,
w
x_{n,c,h,w}
xn,c,h,w表示输入数据的第
n
n
n个样本的第
c
c
c个通道、第
h
h
h行、第
w
w
w列的值,
G
G
G表示组数,
E
[
x
n
,
G
,
h
,
w
]
\mathrm{E}[x_{n,G,h,w}]
E[xn,G,h,w]和
V
a
r
[
x
n
,
G
,
h
,
w
]
\mathrm{Var}[x_{n,G,h,w}]
Var[xn,G,h,w]分别表示第
n
n
n个样本在第
G
G
G个组内的均值和方差。
torch.nn.GroupNorm()
3. 实例归一化(Instance Normalization,IN):
IN层在每个样本的每个通道上进行归一化,从而增强了特征之间的独立性。IN通常用于图像风格迁移等任务中,可以减少模型的过拟合风险。其数学公式如下:
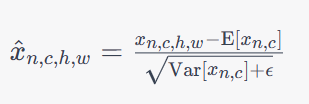
其中,
x
n
,
c
,
h
,
w
x_{n,c,h,w}
xn,c,h,w表示输入数据的第
n
n
n个样本的第
c
c
c个通道、第
h
h
h行、第
w
w
w列的值,
E
[
x
n
,
c
]
\mathrm{E}[x_{n,c}]
E[xn,c]和
V
a
r
[
x
n
,
c
]
\mathrm{Var}[x_{n,c}]
Var[xn,c]分别表示第
n
n
n个样本在第
c
c
c个通道上的均值和方差。
torch.nn.InstanceNorm1d()、torch.nn.InstanceNorm2d()、torch.nn.InstanceNorm3d()
4. 层归一化(Layer Normalization,LN):
LN层在每个样本的每个特征维度上进行归一化,从而增强了特征之间的独立性,使得模型对输入数据的小扰动更加鲁棒。LN通常用于自然语言处理等任务中,可以缓解梯度消失问题,并且在训练和测试时具有相同的效果。其数学公式如下:
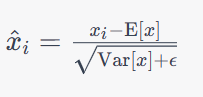
其中,
x
i
x_i
xi表示输入数据在第
i
i
i个特征维度上的值,
E
[
x
]
\mathrm{E}[x]
E[x]表示在该特征维度上的均值,
V
a
r
[
x
]
\mathrm{Var}[x]
Var[x]表示在该特征维度上的方差,
ϵ
\epsilon
ϵ是一个非常小的常数(如
1
0
−
5
10^{-5}
10−5),以防止方差为零的情况。
torch.nn.LayerNorm()
5. 权重归一化(Weight Normalization,WN):
WN是一种对网络参数进行归一化的方法,可以将网络中的权重矩阵分解为模和方向两个部分,从而增强模型对输入数据的平移不变性和旋转不变性。WN通常用于循环神经网络等模型中,可以加速模型收敛速度并减少过拟合风险。其数学公式如下:
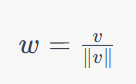
其中,
v
v
v表示网络的权重向量,
∣
v
∣
|v|
∣v∣表示该向量的模长。WN层的归一化操作在每个迭代步骤中都会进行,因此可以看作是对网络的参数进行动态的归一化操作。
torch.nn.utils.weight_norm()
6. 局部响应归一化(Local Response Normalization,LRN):
LRN层在每个位置的通道上进行归一化,对输入数据在局部邻域内进行响应归一化,使得在相邻的特征图(Feature Map)上得到的响应可以被归一化,而不仅仅是在单个特征图上进行归一化。这样可以增强模型对输入数据中不同特征之间的区分度,并防止激活值过大或过小的情况。,其数学公式如下:
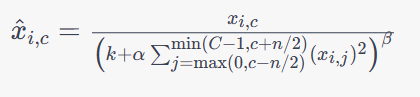
其中,
x
i
,
c
x_{i,c}
xi,c表示输入数据在第
i
i
i个位置的第
c
c
c个通道上的值,
C
C
C表示通道数,
n
n
n表示归一化的范围,
k
,
α
,
β
k,\alpha,\beta
k,α,β是超参数,用于控制归一化的强度和范围。可以看出,LRN层通过将输入数据在一个局部邻域内进行平方和计算和除法操作,实现了对输入数据在不同通道上的归一化操作。
torch.nn.LocalResponseNorm()
7. 通道间归一化(Cross-Channel Normalization,CCN):
CCN层在每个位置的所有通道上进行归一化,其数学公式如下:
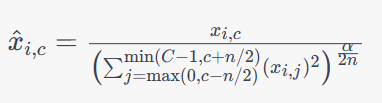
其中,
x
i
,
c
x_{i,c}
xi,c表示输入数据在第
i
i
i个位置的第
c
c
c个通道上的值,
C
C
C表示通道数,
n
n
n表示归一化的范围,
α
\alpha
α是一个超参数,用于控制归一化的强度和范围。
torch.nn.CrossChannelNorm()
8. 跨通道局部响应归一化(Cross-Map Local Response Normalization,CrossMapLRN):
CrossMapLRN层在每个位置的所有通道上进行归一化,CrossMapLRN层将每个特征映射上的值除以一个局部响应归一化的因子,同时还会将不同特征映射之间的值进行交叉通道归一化,以此来增强模型的泛化性能和鲁棒性。其数学公式如下:
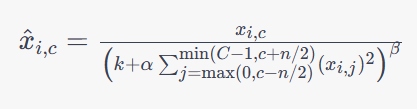
其中,
x
i
,
c
x_{i,c}
xi,c表示输入数据在第
i
i
i个位置的第
c
c
c个通道上的值,
C
C
C表示通道数,
n
n
n表示归一化的范围,
k
,
α
,
β
k,\alpha,\beta
k,α,β是超参数,用于控制归一化的强度和范围。CrossMapLRN与LRN的区别在于,CrossMapLRN在归一化时只考虑同一位置的不同通道间的响应,而不考虑不同位置的响应。
torch.nn.CrossMapLRN2d()














 6711
6711











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









