










本文属原创,转载须标明:https://blog.csdn.net/saw009/article/details/91788671
❶.简介
关键词:图像检索;VGG16;holidays数据集;mAP
运行环境:Windows10,MATLAB R2018b
注:本文重点关注如何计算holidays数据集的mAP,因此,不对其他部分做详细解释。
❷.步骤预览
1.搭建环境
2.特征提取
3.相似性匹配
4.计算性能(mAP)
❸.实施过程
1.搭建环境
a.安装VGG16模型
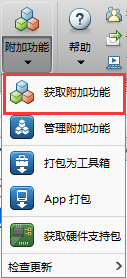
本文利用MATLAB R2018b来使用卷积神经网络VGG16来提取图像特征,因此,需要提前在MATLAB上安装预训练好的VGG16模型。具体步骤如下图所示:首先在附加功能中点击获取附加功能按钮;然后,搜索VGG16;最后,进入相应结果进行安装。


b.设置工作文件夹内容
本文的工作文件夹名设置为images,其中,包含两个子文件夹(jpg,特征),三个实时脚本文件(features_by_VGG16.mlx,Return_result.mlx,holidays_map.mlx)和两个.dat文件(holidays_images.dat,resultfile.dat)。文件夹内容分布及每个文件的作用如下图所示。

c.代码执行顺序
features_by_VGG16.mlx→Return_result.mlx→holidays_map.mlx
2.特征提取
从该部分开始,本文将详细解释上述三个代码的内容,若只需相应的实验结果,通过上述的代码执行顺序即可得出。
该部分可以分为以下几个步骤:
1.加载数据集所有图像,并获取文件数,设置一些需要用到的变量
2.加载VGG16模型,获取模型要求的输入图像大小
3.提取每幅图像的fc7特征
4.保存一些中间变量,避免下次使用时,需要重新提取
5.pca降维
6.按图像名保存特征文件
上述步骤的详细解释将放在代码中,故不再详述。
% dataset -> Holidays Dataset:http://lear.inrialpes.fr/~jegou/data.php
% 下载无速度时,可访问该链接进行下载:https://download.csdn.net/download/saw009/11237703
% 读取holidays所有图像文件
dataset = dir('./jpg/*.jpg');
% 获取图像文件数目
file_num= size(dataset,1);
% 建立图像文件名变量
imgname = cell(file_num,1);
% 建立VGG16特征变量,每行表示一幅图像的特征,fc7共4096维
f_fc7 = zeros(file_num,4096);
% 加载VGG16模型,并获取模型对图像的输入大小要求
net = vgg16;
insz = net.Layers(1).InputSize;
% 提取所有图像的fc7层特征
for i=1:file_num
% 加载图像路径
img_path = dataset(i).folder + "\" + dataset(i).name;
% 获取图片名imgname(不包含文件格式.jpg)
pic_num = split(dataset(i).name,{'.'});
imgname(i) = pic_num(1);
% 读取图像
im = imread(img_path);
% % 判断图像是否为单通道的灰度图像,若是,则将其转换为3通道的图像
% if size(im,3)==1
% rgb=cat(3,im,im,im);
% im = mat2gray(rgb);
% end
% 将读取处理的图像转换成单精度,防止零均值化后,小于零的像素值被丢弃
img = single(im);
% 将输入图像缩放至VGG16模型所要求的大小,默认使用双三次插值的imresize要比默认使用双线性插值的augmentedImageDatastore更好
img_resize = imresize(img, insz(1:2));
% 提取特征
f_fc7(i,:) = activations(net,img_resize,'fc7','OutputAs','rows');
% 显示进度
if mod(i,100) == 0
i
end
end
% 保存中间变量
save('f_fc7.mat','f_fc7');
save('imgname.mat','imgname');
% 对提取出来的特征进行归一化后,能够进一步提高精确度
% normalize比normr精确度更高,即服从标准正态分布的数据比L2标准化要好
% normalize采用标准正态分布
% normr采用L2标准化,其使用方式为:normr(f_fc7)
% pca降维
f_fc7_normalizing = normalize(f_fc7,2);
[f_COEFF7, f_SCORE7, f_latent7]=pca(f_fc7_normalizing);
% 将降维后的特征按序号保存,仅取前64维
for i=1:file_num
feature = f_SCORE7(i,1:64);
dlmwrite(['./特征/',imgname{i},'.txt'],feature);
end
3.相似性匹配
匹配过程中使用L1距离,重点在于如何保存匹配后产生的结果文件。
根据holidays数据集发布页中EVALUATION PACKAGE文件(python代码),结果文件的格式要求为:
每一行为一幅查询图像的返回结果,其格式为:查询图像名 返回结果序号(0) 返回图像名(0) 返回结果序号(1) 返回图像名(1) ...
注:图像名如:123456.jpg,(数字)表示序号从0开始,返回图像对应的返回序号。内容如下图所示:

匹配步骤:
1.读取特征文件,设置一些需要用到的变量
2.将特征文件读入矩阵:行表示特征,列表示维度
3.进行匹配:每幅图像将与holidays数据集中的所有图像进行L1距离计算,然后选出距离最小的前num_return幅图像,最后按照 结果文件的格式要求按行排列。
4.保存匹配后的结果
上述步骤的详细解释将放在代码中,故不再详述。
% 读取特征文件
features_file = dir('./特征/*.txt');
% 建立特征文件数量变量
features_num = size(features_file,1);
% 将特征文件读入矩阵:行表示特征,列表示维度
% 读取特征的维度,方便建立特征矩阵
feature1_path = features_file(1).folder + "\" + features_file(1).name;
features_dim = size(importdata(feature1_path),2);
% 建立特征矩阵
features = zeros(features_num,features_dim);
for i = 1:features_num
features_path = features_file(i).folder + "\" + features_file(i).name;
features(i,:) = importdata(features_path);
end
% 设置返回图像数目:注意原图像也在其中
num_return = 5;
% 建立返回结果文件变量
resultfile = {};
l = 1;
for i=1:features_num
% 计算当前图像与所有图像的L1距离
L1 = zeros(features_num,1);
for j=1:features_num
diff = features(i,:) - features(j,:);
L1(j) = sum(abs(diff));
end
% 对L1距离的结果进行排序
% ****特别注释,sort可以直接返回排好序之后,原来对应的索引index
[L1_sorted, index] = sort(L1);
% 先将查询图像名放在元胞中,然后通过for循环将返回排序号和返回图像依次放在后面,以下是python代码中的定义
% result_line = query_image_name query_result*
% query_result = rank result_image_name
%将文件名从.txt转为.jpg,因为保存的是图片名
query_image_name = split(features_file(i).name,'.');
result_line = [query_image_name{1},'.jpg'];
% 只保存500幅查询图像的返回结果
if mod(str2double(query_image_name{1}),100)==0
% k从2开始取值,因为返回图像不包含查询图像
for k=2:num_return
% 序号rank要从0开始,因此要减2
rank = k-2;
result_image_name = split(features_file(index(k)).name,'.');
query_result = [num2str(rank),' ',result_image_name{1},'.jpg'];
%这个步骤很重要,通过中间变量temp产生新的result_line,可惜MATLAB没有python中.append()那样的功能
temp = [result_line,' ',query_result];
result_line = temp;
end
resultfile{l,1} = result_line;
l=l+1;
end
end
% 保存返回结果文件,保存之前先清空
dlmwrite('resultfile.dat','');
for i=1:size(resultfile,1)
dlmwrite('resultfile.dat',resultfile{i,1},'delimiter', '','newline','pc','-append');
end虽然上述代码中有了详细的注释,但关于如何使用{},[]来建立元胞,矩阵实在是难以表达,因此还望见谅。其实,在写代码的过程中,最重要的是掌握算法的思想和原理,具体需要用到什么语句来实现,不懂的可以百度或者请教老师和同学。
4.计算性能(mAP)
该部分和holidays数据集发布页中EVALUATION PACKAGE文件(python代码)基本相同,可以算是python代码的MATLAB版复现。只要能读懂源代码,此代码的阅读也是小菜一碟。
计算步骤:
1.读取返回结果文件和groundtruth文件
2.获取所有图像的名字(变量:allnames)以及每幅查询图像的groundtruth(变量:gt,该变量中的每一行与返回结果文件相似,首先是查询图像,后面是相关图像(与查询图像相似,或正例图像)),值得注意的是,该数据集包含1491张图像,但其中500张图像用作查询图像,这些图像的名字就能被100整除。
3.计算mAP:这里的mAP是PR曲线下的面积AUC,通过近似积分的形式计算(累加梯形面积),但也有其他的计算方式。
同样,上述步骤的详细解释将放在代码中,故不再详述。
% 查询返回结果文件resultfile.dat格式
% 每一行为一幅图像的查询结果:查询图像 返回序号(0) 返回图像(0) 返回序号(1) 返回图像(1) ...
% 图像格式:123456.jpg
infilename = importdata('resultfile.dat');
groundtruth = importdata('holidays_images.dat');
% get_groundtruth
%%% Read datafile holidays_images.dat and output a dictionary
%%% mapping queries to the set of positive results (plus a list of all
%%% images)
allnames = groundtruth;
% 建立所有图像的groundtruth,没有找到字典的功能,只能用元胞代替了
gt = cell(500,2);
k=0;
for i=1:size(groundtruth,1)
% 单个图像的名字(包含.jpg)
imname = groundtruth{i};
imname_split = split(imname,'.');
% 单个图像的名字(不包含.jpg)
imno = str2double(imname_split(1));
% 查询图像名能被100整除,查询图像后的图像就是其相关图像,这里是if...else...就是这个作用
if mod(imno,100)==0
k = k+1;
gt{k,1} = imname;
gt{k,2} = {};
else
temp = [gt{k,2},{imname}];
gt{k,2} = temp;
end
end
% 建立所有查询图像的AP的和,以及查询图像数
sum_ap = 0;
n = 0;
for i=1:size(infilename,1)
% 提取每一行的查询图像query_name,返回结果和序号results
infilename_line = split(infilename{i},' ');
query_name = infilename_line{1};
query_name_split = split(query_name,'.');
imno = str2double(query_name_split(1));
% 如果不是查询图像则不计算AP
if ~mod(imno,100)==0
continue
end
results = infilename_line(2:end);
% 提取查询图像在gt中所在的位置,方便查找相关图像(由于MATLAB没有字典,所以通过该方式实现)
[row,col] = ind2sub(size(gt),find(cellfun(@(x)strcmp(x,query_name),{gt{:,1}})));
gt_results = gt{row,2};
% tp_ranks是相关图像的序号,rank_shift用于移除查询图像是相关图像的情况
tp_ranks=[];
rank_shift=0;
for j=1:size(results,1)/2
rank = results(j*2-1);
returned_name = results(j*2);
% 返回图像不在数据集中,执行报错
if ~ismember(returned_name,allnames)
error(returned_name + " is not in holidays dataset")
end
if returned_name{1}==query_name
rank_shift=-1;
elseif ismember(returned_name,gt_results)
tp_ranks = [tp_ranks,str2double(rank{1})+rank_shift];
end
end
% score_ap_from_ranks_1,计算ap的函数
% 其中值得注意的是ntp=j-1,由于python中是从0开始,所以参与运算时减1;作为索引时不减
ranks = tp_ranks;
nres = size(gt_results,2);
ap=0;
recall_step=1.0/nres;
for j=1:size(ranks,2)
rank = ranks(j);
ntp = j-1;
if rank==0
precision_0=1.0;
else
precision_0=ntp/rank;
end
precision_1=(ntp+1)/(rank+1);
ap = ap + (precision_1+precision_0)*recall_step/2.0;
end
sum_ap = sum_ap+ap;
n=n+1;
end
map = sum_ap/n最终结果:![]()
5.使用python源文件计算mAP
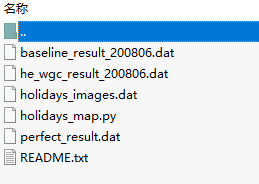
在holidays数据集发布页中下载好EVALUATION PACKAGE文件(python代码)之后,解压可以得到如图文件:
打开holidays_map.py文件,可以看到计算mAP的源代码已经如何使用该代码,使用方式如下图所示:
接下来,讲一下如何使用,首先python的环境要在python2.7;然后,打开Windows命令窗;在其中,跳转到源代码所在的文件夹;然后输入上图黑框圈出的命令,得出结果如下图所示。
















 1095
1095











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









