







1. Valid Sodoku
Determine if a Sudoku is valid, according to: Sudoku Puzzles - The Rules.
The Sudoku board could be partially filled, where empty cells are filled with the character '.'.

A partially filled sudoku which is valid.
Note:
A valid Sudoku board (partially filled) is not necessarily solvable. Only the filled cells need to be validated.
bool isValidSudoku(vector<vector<char> > &board) {
for(int i=0; i<board.size(); i++){
for(int j=0; j<board[i].size();j++){
for(int k=j+1; k<board[i].size();k++){
if(board[i][j] == board[i][k] && board[i][j]!='.')
return false;
}
for(int k=0; k<board.size(); k++){
if(board[i][j] == board[k][j] && board[i][j]!='.' && i!=k)
return false;
}
}
}
int row[9];
for(int i=0; i<9;i+=3){
for(int j=0; j<9; j+=3){
memset(row,0,9*sizeof(int));
for(int m=0; m<3;m++){
for(int n=0; n<3;n++){
if(board[i+m][j+n] == '.')
continue;
if(row[board[m+i][j+n]-49] == 1)
return false;
row[board[m+i][j+n]-49]++;
}
}
}
}
return true;
}2.Next Permutation
Implement next permutation, which rearranges numbers into the lexicographically next greater permutation of numbers.
If such arrangement is not possible, it must rearrange it as the lowest possible order (ie, sorted in ascending order).
The replacement must be in-place, do not allocate extra memory.
Here are some examples. Inputs are in the left-hand column and its corresponding outputs are in the right-hand column.
1,2,3 → 1,3,2
3,2,1 → 1,2,3
1,1,5 → 1,5,1
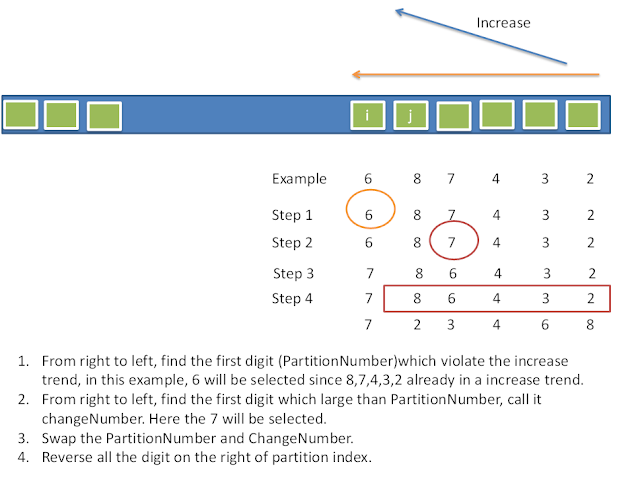
void nextPermutation(vector<int> &num) {
int vioIndex = num.size()-1;
while(vioIndex >0){
if(num[vioIndex]>num[vioIndex-1])
break;
vioIndex--;
}
if(vioIndex>0){
vioIndex--;
int rightIndex = num.size()-1;
while(rightIndex>=0 && num[rightIndex]<=num[vioIndex]){
rightIndex--;
}
int swap = num[vioIndex];
num[vioIndex] = num[rightIndex];
num[rightIndex] = swap;
vioIndex++;
}
int end = num.size()-1;
while(end>vioIndex){
int swap = num[vioIndex];
num[vioIndex] = num[end];
num[end] = swap;
vioIndex++;
end--;
}
}3. ZigZag Conversion
The string "PAYPALISHIRING" is written in a zigzag pattern on a given number of rows like this: (you may want to display this pattern in a fixed font for better legibility)
P A H N A P L S I I G Y I RAnd then read line by line:
"PAHNAPLSIIGYIR"
Write the code that will take a string and make this conversion given a number of rows:
string convert(string text, int nRows);
convert("PAYPALISHIRING", 3)
should return
"PAHNAPLSIIGYIR"
.
关键点是计算出输出的坐标点每行是i 每列是j
主元素的坐标是index = j*nRow + (nRow-2)*j+i
中间元素坐标是index+nRow-i+nRow-2-i
string convert(string s, int nRows) {
if(nRows <=1) return s;
string result;
if(s.size() ==0 ) return result;
for(int i=0; i<nRows;i++){
for(int j=0,index=i; index<s.size();j++, index = (2*nRows-2)*j+i){
result.append(1,s[index]);
if(i==0 || i==nRows-1){
continue;
}
if(index+(nRows-i-1)*2 < s.size())
result.append(1,s[index+(nRows-i-1)*2]);
}
}
return result;
}4.
Wildcard Matching
Implement wildcard pattern matching with support for '?' and '*'.
'?' Matches any single character.
'*' Matches any sequence of characters (including the empty sequence).
The matching should cover the entire input string (not partial).
The function prototype should be:
bool isMatch(const char *s, const char *p)
Some examples:
isMatch("aa","a") → false
isMatch("aa","aa") → true
isMatch("aaa","aa") → false
isMatch("aa", "*") → true
isMatch("aa", "a*") → true
isMatch("ab", "?*") → true
isMatch("aab", "c*a*b") → false
Analysis:
For each element in s
If *s==*p or *p == ? which means this is a match, then goes to next element s++ p++.
If p=='*', this is also a match, but one or many chars may be available, so let us save this *'s position and the matched s position.
If not match, then we check if there is a * previously showed up,
if there is no *, return false;
if there is an *, we set current p to the next element of *, and set current s to the next saved s position.
bool isMatch(const char *s, const char *p) {
const char* star = NULL;
const char* ss = s;
while(*s){
if((*p=='?') || *p==*s){
s++;
p++;
continue;
}
if(*p=='*'){
star = p++;
ss = s;
continue;
}
if(star){
p = star+1;s=++ss;
continue;
}
return false;
}
while(*p=='*'){p++;}
return !*p;
}5. Metge Intervals
Given a collection of intervals, merge all overlapping intervals.
For example,
Given [1,3],[2,6],[8,10],[15,18],
return [1,6],[8,10],[15,18].
The idea is simple. First sort the vector according to the start value. Second, scan every interval, if it can be merged to the previous one, then merge them, else push it into the result vector.
注意在扫描比较之前要根据start排序
Note here:
The use of std::sort to sort the vector, need to define a compare function, which need to be static. (static bool myfunc() ) The sort command should be like this: std::sort(intervals.begin,intervals.end, Solution::myfunc); otherwise, it won't work properly.
/**
* Definition for an interval.
* struct Interval {
* int start;
* int end;
* Interval() : start(0), end(0) {}
* Interval(int s, int e) : start(s), end(e) {}
* };
*/
class Solution {
public:
static bool myfunc(const Interval &a, const Interval &b){
return (a.start < b.start);
}
vector<Interval> merge(vector<Interval> &intervals) {
if(intervals.size()<=1) return intervals;
vector<Interval> result;
sort(intervals.begin(),intervals.end(),myfunc);
result.push_back(intervals[0]);
for(int i=1; i<intervals.size();i++){
if(result.back().end>=intervals[i].start){
result.back().end = max(result.back().end,intervals[i].end);
}else{
result.push_back(intervals[i]);
}
}
return result;
}
};6.Insert Intervals
Given a set of non-overlapping intervals, insert a new interval into the intervals (merge if necessary).
You may assume that the intervals were initially sorted according to their start times.
Example 1:
Given intervals [1,3],[6,9], insert and merge [2,5] in as [1,5],[6,9].
Example 2:
Given [1,2],[3,5],[6,7],[8,10],[12,16], insert and merge [4,9] in as [1,2],[3,10],[12,16].
This is because the new interval [4,9] overlaps with [3,5],[6,7],[8,10].
可以利用merge Intervals 中的代码
In other words, the questions gives a new interval, the task is to insert this new interval into an ordered non-overlapping intervals. Consider the merge case.
Idea to solve this problem is quite straight forward:
1. Insert the new interval according to the start value.
2. Scan the whole intervals, merge two intervals if necessary.
vector<Interval> insert(vector<Interval> &intervals, Interval newInterval) {
vector<Interval> result;
vector<Interval>::iterator it;
for(it = intervals.begin();it!=intervals.end();it++){
if(newInterval.start<(*it).start){
intervals.insert(it,newInterval);
break;
}
}
if(it == intervals.end())
intervals.insert(it,newInterval);
if(intervals.empty()) return result;
result.push_back(*intervals.begin());
for(it = intervals.begin()+1; it!=intervals.end();it++){
if(result.back().end>=(*it).start){
result.back().end = max(result.back().end,(*it).end);
}else{
result.push_back(*it);
}
}
return result;
}7. Simplify Path
Given an absolute path for a file (Unix-style), simplify it.
For example,
path = "/home/", => "/home"
path = "/a/./b/../../c/", => "/c"
- Did you consider the case where path =
"/../"?
In this case, you should return"/". - Another corner case is the path might contain multiple slashes
'/'together, such as"/home//foo/".
In this case, you should ignore redundant slashes and return"/home/foo".
思路:
1.遇到'/'直接寻找下一元素
2. 遇到‘.’do nothing, look for next element
3. 遇到.. pop top in stack
4. 其他的元素,压栈
string simplifyPath(string path) {
assert(path[0]=='/');
vector<string> vec;
int i=0;
while(i<path.size()){
int end = i+1;
while(end<path.size() && path[end]!='/')
end++;
string sub = path.substr(i+1,end-i-1);
if(sub.length()>0){
if(sub == ".."){
if(!vec.empty()) vec.pop_back();
}
else if(sub!=".")
vec.push_back(sub);
}
i=end;
}
if(vec.empty()) return "/";
string res;
for(int i=0;i<vec.size();i++)
res += "/"+vec[i];
return res;
}8. Text Justification
Given an array of words and a length L, format the text such that each line has exactly L characters and is fully (left and right) justified.
You should pack your words in a greedy approach; that is, pack as many words as you can in each line. Pad extra spaces ' ' when necessary so that each line has exactlyL characters.
Extra spaces between words should be distributed as evenly as possible. If the number of spaces on a line do not divide evenly between words, the empty slots on the left will be assigned more spaces than the slots on the right.
For the last line of text, it should be left justified and no extra space is inserted between words.
For example,
words: ["This", "is", "an", "example", "of", "text", "justification."]
L: 16.
Return the formatted lines as:
[ "This is an", "example of text", "justification. " ]
Note: Each word is guaranteed not to exceed L in length.
The idea of my solution is not efficient, but easily understood.Step 1: Find the level number for each word. Assuming that there is at least 1 space between two words.
Step 2: Find the number of word in each level and the total spaces needed in that level.
Step 3: Compute the number of spaces M in each level that is needed between two words. If the spaces are not evenly distributed. Compute the number of words where 1+M spaces is needed, and the between the rest of words there needed M spaces.
Step 4: Write the levels which has only one word to the result.
Step 5: Find the levels that the last word that level ends with '.' (which is the sentence end).
Step 6: Write the levels to the result.
Step 7: Return result.
another one:
1. 找到每行的首位字符 start end
2. 计算每行的间隔数 interval = end-start
3. 计算平均每个间隔的空格数
4. 计算左边间隔的空格数
5. 构建新字符数组
6. 如果长度不够,补充空格
vector<string> result;
if(0==words.size()) return result;
int i=0;
while(i<words.size()){
int start =i;
int sum=0;
while(i<words.size() && sum+words[i].size()<=L){
sum+=words[i].size()+1;
i++;
}
int end = i-1;
int intervalCount = end-start;//interval space between words, "abc 1 bcd 2 def"
int avgSp = 0, leftSp = 0;
if(intervalCount >0){
avgSp = (L-sum+intervalCount+1)/intervalCount;
leftSp = (L-sum+intervalCount+1)%intervalCount;
}
string line;// construct new line
for(int j=start; j<end;j++){
line += words[j];
if(i == words.size())// the last line
line.append(1,' ');
else{
line.append(avgSp,' ');//average space
if(leftSp>0){//extra space
line.append(1,' ');
leftSp--;
}
}
}
line+=words[end];// add last word
if(line.size()<L)
line.append(L-line.size(),' ');
result.push_back(line);
}
return result;9. String to Integer(atoi)
Implement atoi to convert a string to an integer.
Hint: Carefully consider all possible input cases. If you want a challenge, please do not see below and ask yourself what are the possible input cases.
Notes: It is intended for this problem to be specified vaguely (ie, no given input specs). You are responsible to gather all the input requirements up front.
实现细节题。注意几个测试用例:
1. 不规则输入,但是有效
"-3924x8fc", " + 413",
2. 无效格式
" ++c", " ++1"
3. 溢出数据
"2147483648"
int atoi(const char *str){
int num=0;
int sign = 1;//flag for negtive and positive
int len = strlen(str);
int i=0;
while(str[i]==' ' && i<len) i++;//space in the begining
if(str[i] == '+') i++;//find +/-
if(str[i] == '-') {sign =-1; i++;}
for(;i<len;i++){
//if(str[i]==' ') break;
if(str[i]<'0' || str[i] > '9') break;
if(INT_MAX/10 < num || INT_MAX/10 == num && INT_MAX%10 < (str[i]-'0')){//handle the situation that biger int_max
return sign == -1 ? INT_MIN : INT_MAX;
break;
}
num = num*10 + str[i] - '0';
}
return num*sign;
}10 Merge Two Sorted Lists
Merge two sorted linked lists and return it as a new list. The new list should be made by splicing together the nodes of the first two lists.
ListNode *mergeTwoLists(ListNode *l1, ListNode *l2) {
ListNode *head = new ListNode(INT_MIN);
ListNode *pre = head;
while(l1 != NULL && l2 != NULL){
if(l1->val <= l2->val){
pre->next = l1;
l1 = l1->next;
}else{
pre->next = l2;
l2 = l2->next;
}
pre = pre->next;
}
if(l1 != NULL){
pre->next = l1;
}
if(l2 != NULL){
pre->next = l2;
}
pre = head->next;
delete head;
return pre;
}11. Set Matrix Zeros
Given a m x n matrix, if an element is 0, set its entire row and column to 0. Do it in place.
Did you use extra space?
A straight forward solution using O(mn) space is probably a bad idea.
A simple improvement uses O(m + n) space, but still not the best solution.
Could you devise a constant space solution?
设置每行每列的标志位,最后再清空
void setZeroes(vector<vector<int> > &matrix) {
assert(matrix.size() >0);
int row = matrix.size();
int column = matrix[0].size();
bool zeroRow = false, zeroCol = false;
for(int i=0; i<column; i++){
if(matrix[0][i] == 0)
zeroRow = true;
}
for(int i=0; i<row; i++){
if(matrix[i][0] == 0)
zeroCol = true;
}
for(int i=1; i<row; i++){
for(int j=1; j<column; j++){
if(matrix[i][j]==0){
matrix[i][0] = 0;
matrix[0][j] = 0;
}
}
}
for(int i=1; i<row; i++){
for(int j=1; j<column; j++){
if(matrix[i][0]==0 || matrix[0][j]==0)
matrix[i][j] = 0;
}
}
if(zeroRow == true){
for(int i=0; i<column;i++){
matrix[0][i] = 0;
}
}
if(zeroCol == true){
for(int i=0; i<row;i++){
matrix[i][0] = 0;
}
}
}
未完待续















 697
697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









