







本文要解决的问题:
通过查看Spark作业提交的源码,对其作业提交过程有更深的理解。
作业提交的基本流程
首先需要找到Spark submit过程的源码。在工程路径的spark.deploy.SparkSubmit下,
submit是一个单独的进程,首先查看它的main方法:
def main(args: Array[String]): Unit = {
val appArgs = new SparkSubmitArguments(args)
if (appArgs.verbose) {
// scalastyle:off println
printStream.println(appArgs)
// scalastyle:on println
}
appArgs.action match {
case SparkSubmitAction.SUBMIT => submit(appArgs)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
}
}作业提交调用了submit()方法,该方法的源码如下:
private def submit(args: SparkSubmitArguments): Unit = {
val (childArgs, childClasspath, sysProps, childMainClass) = prepareSubmitEnvironment(args)
def doRunMain(): Unit = {
if (args.proxyUser != null) {
val proxyUser = UserGroupInformation.createProxyUser(args.proxyUser,
UserGroupInformation.getCurrentUser())
try {
proxyUser.doAs(new PrivilegedExceptionAction[Unit]() {
override def run(): Unit = {
runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)
}
})
} catch {
case e: Exception =>
// Hadoop's AuthorizationException suppresses the exception's stack trace, which
// makes the message printed to the output by the JVM not very helpful. Instead,
// detect exceptions with empty stack traces here, and treat them differently.
if (e.getStackTrace().length == 0) {
// scalastyle:off println
printStream.println(s"ERROR: ${e.getClass().getName()}: ${e.getMessage()}")
// scalastyle:on println
exitFn(1)
} else {
throw e
}
}
} else {
runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)
}
}最后没什么问题的话,会执行
runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)方法,该方法中设置了一些配置参数:如集群模式、运行环境等。这里主要查看Client的集群模式。下面看下作业提交序列图:
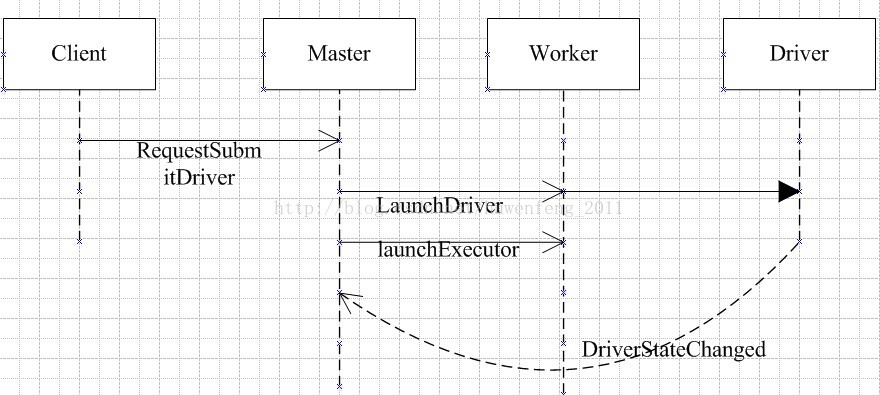
Client
Client的启动方法onStart。
override def onStart(): Unit = {
driverArgs 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1250
1250

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









