









本文要解决的问题:
本文主要说明作业提交的的具体运行环境,通过学习,对作业的运行有更加深入的理解。
基本流程
这里从SparkContext中的runJob方法开始跟踪它的源码过程。下面的图简要的描述了Job运行的过程
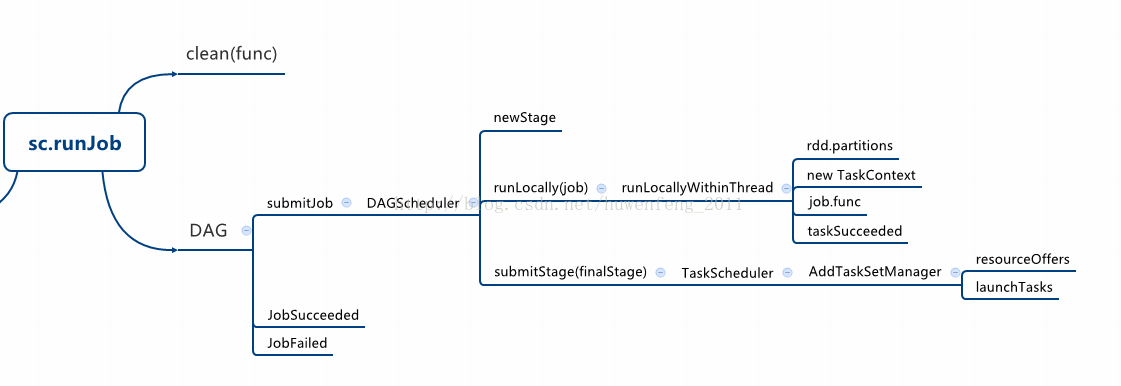
runJob的源码如下:
在org.apache.spark.SparkContext.scala目录下,找到runJob方法,
/**
* Run a function on a given set of partitions in an RDD and pass the results to the given
* handler function. This is the main entry point for all actions in Spark.
*/
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
if (stopped.get()) {
throw new IllegalStateException("SparkContext has been shutdown")
}
val callSite = getCallSite
val cleanedFunc = clean(func)
logInfo("Starting job: " + callSite.shortForm)
if (conf.getBoolean("spark.logLineage", false)) {
logInfo("RDD's recursive dependencies:\n" + rdd.toDebugString)
}
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
rdd.doCheckpoint()
}这里主要有三个函数:
Clean(func):主要是清理关闭一些内容,比如序列化。
runJob(…):将任务提交给DagScheduler。
doCheckpoint():保存当前RDD,在Job完成之后调用父rdd。
这里主要看runJob方法。
def runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit = {
val start = System.nanoTime
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
// Note: Do not call Await.ready(future) because that calls `scala.concurrent.blocking`,
// which causes concurrent SQL executions to fail if a fork-join pool is used. Note that
// due to idiosyncrasies in Scala, `awaitPermission` is not actually used anywhere so it's
// safe to pass in null here. For more detail, see SPARK-13747.
val awaitPermission = null.asInstanceOf[scala.concurrent.CanAwait]
waiter.completionFuture.ready(Duration.Inf)(awaitPermission)
waiter.completionFuture.value.get match {
case scala.util.Success(_) =>
logInfo("Job %d finished: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
case scala.util.Failure(exception) =>
logInfo("Job %d failed: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
// SPARK-8644: Include user stack trace in exceptions coming from DAGScheduler.
val callerStackTrace = Thread.currentThread().getStackTrace.tail
exception.setStackTrace(exception.getStackTrace ++ callerStackTrace)
throw exception
}
}DagScheduler
跟踪源码,进入了DagScheduler的runJob方法。在这里方法中会直接提交Job,然后等待返回结果。成功时JobSucceeded什么都不做,失败则抛出异常。
进去源码submitJob方法,这方法提交作业到调度器,源码如下:
def submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
// Check to make sure we are not launching a task on a partition that does not exist.
//检查以确保我们不发动不存在的分区任务
val maxPartitions = rdd.partitions.length
partitions.find(p => p >= maxPartitions || p < 0).foreach { p =>
throw new IllegalArgumentException(
"Attempting to access a non-existent partition: " + p + ". " +
"Total number of partitions: " + maxPartitions)
}
val jobId = nextJobId.getAndIncrement()
if (partitions.size == 0) {
// Return immediately if the job is running 0 tasks
return new JobWaiter[U](this, jobId, 0, resultHandler)
}
assert(partitions.size > 0)
val func2 = func.asInstanceOf[(TaskContext, Iterator[_]) => _]
val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler)
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
waiter
}跟踪源码:eventProcessLoop是DagScheduler的事件驱动也是一个Actor。这里发送了一个消息eventProcessLoop JobSubmitted:
case MapStageSubmitted(jobId, dependency, callSite, listener, properties) =>
dagScheduler.handleMapStageSubmitted(jobId, dependency, callSite, listener, properties)程序中调用了handleJobSubmitted方法
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
try {
// New stage creation may throw an exception if, for example, jobs are run on a
// HadoopRDD whose underlying HDFS files have been deleted.
finalStage = newResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
clearCacheLocs()
logInfo("Got job %s (%s) with %d output partitions".format(
job.jobId, callSite.shortForm, partitions.length))
logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")")
logInfo("Parents of final stage: " + finalStage.parents)
logInfo("Missing parents: " + getMissingParentStages(finalStage))
val jobSubmissionTime = clock.getTimeMillis()
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
submitStage(finalStage)
}上面源码中:
1)newStage 实例化一个Stage。Stage就是一组Tasks。
2)创建ActiveJob,是跟踪DAGScheduler中正在活动的Job
3)判断是否在本地运行。
TaskScheduler
接下来再看一看TaskScheduler,TaskScheduler有很多实现类。
这里进入到了TaskSchedulerImpl这个实现类。OK,看看它如何实现submitTasks这个方法的:
override def submitTasks(taskSet: TaskSet) {
val tasks = taskSet.tasks
logInfo("Adding task set " + taskSet.id + " with " + tasks.length + " tasks")
this.synchronized {
val manager = createTaskSetManager(taskSet, maxTaskFailures)
val stage = taskSet.stageId
val stageTaskSets =
taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager])
stageTaskSets(taskSet.stageAttemptId) = manager
val conflictingTaskSet = stageTaskSets.exists { case (_, ts) =>
ts.taskSet != taskSet && !ts.isZombie
}
if (conflictingTaskSet) {
throw new IllegalStateException(s"more than one active taskSet for stage $stage:" +
s" ${stageTaskSets.toSeq.map{_._2.taskSet.id}.mkString(",")}")
}
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
if (!isLocal && !hasReceivedTask) {
starvationTimer.scheduleAtFixedRate(new TimerTask() {
override def run() {
if (!hasLaunchedTask) {
logWarning("Initial job has not accepted any resources; " +
"check your cluster UI to ensure that workers are registered " +
"and have sufficient resources")
} else {
this.cancel()
}
}
}, STARVATION_TIMEOUT_MS, STARVATION_TIMEOUT_MS)
}
hasReceivedTask = true
}
backend.reviveOffers()
}1)首先new了一个createTaskSetManager。createTaskSetManager管理和跟踪TaskSet。失败的任务他会重新启动他,当然重启的次数是有限。这个有createTaskSetManager的构造参数maxTaskFailures决定。
2)添加任务调度模式。Spark中提供了两种调度模式FIFO和FAIR,默认是FIFO。
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)具体来看看这个调度方法。
override def addSchedulable(schedulable: Schedulable) {
require(schedulable != null)
schedulableQueue.add(schedulable)
schedulableNameToSchedulable.put(schedulable.name, schedulable)
schedulable.parent = this
}FIFO是先进先出,这里将作业集添加到调度队列中去了。
3)backend.reviveOffers()。这个backen是
CoarseGrainedSchedulerBackend。这是一个调度器接口,他会等待Executors通过AKKA来连接他。
override def reviveOffers() {
driverEndpoint.send(ReviveOffers)
}接着进入DriverActor的事件处理方法中去receiveWithLogging,ReviveOffers消息调用了makeOffers()。源码如下:
private def makeOffers() {
// Filter out executors under killing
val activeExecutors = executorDataMap.filterKeys(executorIsAlive)
val workOffers = activeExecutors.map { case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores)
}.toSeq
launchTasks(scheduler.resourceOffers(workOffers))
}源码中有两个方法一个是resourceOffers。然后是launchTasks。
resourceOffers方法会从workers中随机抽出一些来执行任务,然后通过TaskSetManager找出和Worker在一起的Task,最后打包成TaskDescription返回源码如下:
/**
* Called by cluster manager to offer resources on slaves. We respond by asking our active task
* sets for tasks in order of priority. We fill each node with tasks in a round-robin manner so
* that tasks are balanced across the cluster.
* 被集群管理者称为提供资源的从节点。我们要求我们的活动任务集来完成任务的优先级。我们把每个节点以循环的方式工作,在整个集群中,任务是平衡的
*/
def resourceOffers(offers: Seq[WorkerOffer]): Seq[Seq[TaskDescription]] = synchronized {
// Mark each slave as alive and remember its hostname
// Also track if new executor is added
//如果有新的任务执行,记录他的主机名
var newExecAvail = false
for (o <- offers) {
//如果这个slave不在executorIdToHost中,则添加
executorIdToHost(o.executorId) = o.host
executorIdToTaskCount.getOrElseUpdate(o.executorId, 0)
if (!executorsByHost.contains(o.host)) {
executorsByHost(o.host) = new HashSet[String]()
executorAdded(o.executorId, o.host)
newExecAvail = true
}
for (rack <- getRackForHost(o.host)) {
hostsByRack.getOrElseUpdate(rack, new HashSet[String]()) += o.host
}
}
// Randomly shuffle offers to avoid always placing tasks on the same set of workers.
//随机shuffle报告,以避免将任务总是分配给同一个worker中
val shuffledOffers = Random.shuffle(offers)
// Build a list of tasks to assign to each worker.
//构建任务列表,分配给每个worker。
val tasks = shuffledOffers.map(o => new ArrayBuffer[TaskDescription](o.cores))
val availableCpus = shuffledOffers.map(o => o.cores).toArray
val sortedTaskSets = rootPool.getSortedTaskSetQueue
for (taskSet <- sortedTaskSets) {
logDebug("parentName: %s, name: %s, runningTasks: %s".format(
taskSet.parent.name, taskSet.name, taskSet.runningTasks))
if (newExecAvail) {
taskSet.executorAdded()
}
}
// Take each TaskSet in our scheduling order, and then offer it each node in increasing order
// of locality levels so that it gets a chance to launch local tasks on all of them.
// NOTE: the preferredLocality order: PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY
var launchedTask = false
for (taskSet <- sortedTaskSets; maxLocality <- taskSet.myLocalityLevels) {
do {
launchedTask = resourceOfferSingleTaskSet(
taskSet, maxLocality, shuffledOffers, availableCpus, tasks)
} while (launchedTask)
}
if (tasks.size > 0) {
hasLaunchedTask = true
}
return tasks
}接下来看launchTasks方法了。该方法中最重要的一句就是:
executorActor(task.executorId) !LaunchTask(new SerializableBuffer(serializedTask))
excutorActor是在CoarseGrainedExecutorBackend的RegisteredExecutor注册事件中,通过SparkDeploySchedulerBackend启动的AppClient。
而在AppClient内部启动了一个AppActor,AppActor想Master发送注册APP信息。
private def tryRegisterAllMasters(): Array[JFuture[_]] = {
masterRpcAddresses.map { masterAddress =>
registerMasterThreadPool.submit(new Runnable {
override def run(): Unit = {
try {
logInfo("Connecting to master " + masterAddress + "...")
val masterEndpoint = rpcEnv.setupEndpointRef(masterAddress, Master.ENDPOINT_NAME)
registerWithMaster(masterEndpoint)
} catch {
case ie: InterruptedException => // Cancelled
case NonFatal(e) => logWarning(s"Failed to connect to master $masterAddress", e)
}
}
})
}
}而在Master中对RegisterApolication事件是这样处理的:
case RegisterApplication(description, driver) =>
// TODO Prevent repeated registrations from some driver
if (state == RecoveryState.STANDBY) {
// ignore, don't send response
} else {
logInfo("Registering app " + description.name)
val app = createApplication(description, driver)
//注册该Application,更新相应的映射关系,添加到等待队列里面
registerApplication(app)
logInfo("Registered app " + description.name + " with ID " + app.id)
//用persistenceEngine持久化Application信息
//默认是不保存的,另外还有两种方式,保存在文件或者ZooKeeper中
persistenceEngine.addApplication(app)
//返回注册成功信息
driver.send(RegisteredApplication(app.id, self))
//作业调度
schedule()
}Worker
LaunchExecutor
任务最终会发送到Worker中去处理,而接收处理的事件就是LauchExecutor了。处理过程如下面源码:
case LaunchExecutor(masterUrl, appId, execId, appDesc, cores_, memory_) =>
if (masterUrl != activeMasterUrl) {
logWarning("Invalid Master (" + masterUrl + ") attempted to launch executor.")
} else {
try {
logInfo("Asked to launch executor %s/%d for %s".format(appId, execId, appDesc.name))
// Create the executor's working directory
val executorDir = new File(workDir, appId + "/" + execId)
if (!executorDir.mkdirs()) {
throw new IOException("Failed to create directory " + executorDir)
}
// Create local dirs for the executor. These are passed to the executor via the
// SPARK_EXECUTOR_DIRS environment variable, and deleted by the Worker when the
// application finishes.
val appLocalDirs = appDirectories.getOrElse(appId,
Utils.getOrCreateLocalRootDirs(conf).map { dir =>
val appDir = Utils.createDirectory(dir, namePrefix = "executor")
Utils.chmod700(appDir)
appDir.getAbsolutePath()
}.toSeq)
appDirectories(appId) = appLocalDirs
val manager = new ExecutorRunner(
appId,
execId,
appDesc.copy(command = Worker.maybeUpdateSSLSettings(appDesc.command, conf)),
cores_,
memory_,
self,
workerId,
host,
webUi.boundPort,
publicAddress,
sparkHome,
executorDir,
workerUri,
conf,
appLocalDirs, ExecutorState.RUNNING)
executors(appId + "/" + execId) = manager
manager.start()
coresUsed += cores_
memoryUsed += memory_
sendToMaster(ExecutorStateChanged(appId, execId, manager.state, None, None))
} catch {
case e: Exception =>
logError(s"Failed to launch executor $appId/$execId for ${appDesc.name}.", e)
if (executors.contains(appId + "/" + execId)) {
executors(appId + "/" + execId).kill()
executors -= appId + "/" + execId
}
sendToMaster(ExecutorStateChanged(appId, execId, ExecutorState.FAILED,
Some(e.toString), None))
}
}源码最后又向Master发送了ExecutorStateChanged
Master将时间转发给Driver,如果果是Executor运行结束,从相应的映射关系里面删除。
CoarseGrainedExecutorBackend
最后发布任务是CoarseGrainedExecutorBackend中的LaunchTask事件。源码如下:
case LaunchTask(data) =>
if (executor == null) {
logError("Received LaunchTask command but executor was null")
exitExecutor(1)
} else {
//获得TaskDescription
val taskDesc = ser.deserialize[TaskDescription](data.value)
logInfo("Got assigned task " + taskDesc.taskId)
//将Task放入Executor队列中
executor.launchTask(this, taskId = taskDesc.taskId, attemptNumber = taskDesc.attemptNumber,
taskDesc.name, taskDesc.serializedTask)
}Executor
最后的任务执行Executor
def launchTask(
context: ExecutorBackend,
taskId: Long,
attemptNumber: Int,
taskName: String,
serializedTask: ByteBuffer): Unit = {
val tr = new TaskRunner(context, taskId = taskId, attemptNumber = attemptNumber, taskName,
serializedTask)
runningTasks.put(taskId, tr)
threadPool.execute(tr)
}进入Executor的run源码过程。
override def run(): Unit = {
val taskMemoryManager = new TaskMemoryManager(env.memoryManager, taskId)
val deserializeStartTime = System.currentTimeMillis()
Thread.currentThread.setContextClassLoader(replClassLoader)
val ser = env.closureSerializer.newInstance()
logInfo(s"Running $taskName (TID $taskId)")
execBackend.statusUpdate(taskId, TaskState.RUNNING, EMPTY_BYTE_BUFFER)
var taskStart: Long = 0
startGCTime = computeTotalGcTime()
try {
val (taskFiles, taskJars, taskProps, taskBytes) =
Task.deserializeWithDependencies(serializedTask)
// Must be set before updateDependencies() is called, in case fetching dependencies
// requires access to properties contained within (e.g. for access control).
Executor.taskDeserializationProps.set(taskProps)
updateDependencies(taskFiles, taskJars)
task = ser.deserialize[Task[Any]](taskBytes, Thread.currentThread.getContextClassLoader)
task.localProperties = taskProps
task.setTaskMemoryManager(taskMemoryManager)
// If this task has been killed before we deserialized it, let's quit now. Otherwise,
// continue executing the task.
if (killed) {
// Throw an exception rather than returning, because returning within a try{} block
// causes a NonLocalReturnControl exception to be thrown. The NonLocalReturnControl
// exception will be caught by the catch block, leading to an incorrect ExceptionFailure
// for the task.
throw new TaskKilledException
}
logDebug("Task " + taskId + "'s epoch is " + task.epoch)
env.mapOutputTracker.updateEpoch(task.epoch)
// Run the actual task and measure its runtime.
taskStart = System.currentTimeMillis()
var threwException = true
val value = try {
val res = task.run(
taskAttemptId = taskId,
attemptNumber = attemptNumber,
metricsSystem = env.metricsSystem)
threwException = false
res
} finally {
val releasedLocks = env.blockManager.releaseAllLocksForTask(taskId)
val freedMemory = taskMemoryManager.cleanUpAllAllocatedMemory()
if (freedMemory > 0 && !threwException) {
val errMsg = s"Managed memory leak detected; size = $freedMemory bytes, TID = $taskId"
if (conf.getBoolean("spark.unsafe.exceptionOnMemoryLeak", false)) {
throw new SparkException(errMsg)
} else {
logWarning(errMsg)
}
}
if (releasedLocks.nonEmpty && !threwException) {
val errMsg =
s"${releasedLocks.size} block locks were not released by TID = $taskId:\n" +
releasedLocks.mkString("[", ", ", "]")
if (conf.getBoolean("spark.storage.exceptionOnPinLeak", false)) {
throw new SparkException(errMsg)
} else {
logWarning(errMsg)
}
}
}
val taskFinish = System.currentTimeMillis()
// If the task has been killed, let's fail it.
if (task.killed) {
throw new TaskKilledException
}
val resultSer = env.serializer.newInstance()
val beforeSerialization = System.currentTimeMillis()
val valueBytes = resultSer.serialize(value)
val afterSerialization = System.currentTimeMillis()
// Deserialization happens in two parts: first, we deserialize a Task object, which
// includes the Partition. Second, Task.run() deserializes the RDD and function to be run.
task.metrics.setExecutorDeserializeTime(
(taskStart - deserializeStartTime) + task.executorDeserializeTime)
// We need to subtract Task.run()'s deserialization time to avoid double-counting
task.metrics.setExecutorRunTime((taskFinish - taskStart) - task.executorDeserializeTime)
task.metrics.setJvmGCTime(computeTotalGcTime() - startGCTime)
task.metrics.setResultSerializationTime(afterSerialization - beforeSerialization)
// Note: accumulator updates must be collected after TaskMetrics is updated
val accumUpdates = task.collectAccumulatorUpdates()
// TODO: do not serialize value twice
val directResult = new DirectTaskResult(valueBytes, accumUpdates)
val serializedDirectResult = ser.serialize(directResult)
val resultSize = serializedDirectResult.limit
// directSend = sending directly back to the driver
val serializedResult: ByteBuffer = {
if (maxResultSize > 0 && resultSize > maxResultSize) {
logWarning(s"Finished $taskName (TID $taskId). Result is larger than maxResultSize " +
s"(${Utils.bytesToString(resultSize)} > ${Utils.bytesToString(maxResultSize)}), " +
s"dropping it.")
ser.serialize(new IndirectTaskResult[Any](TaskResultBlockId(taskId), resultSize))
} else if (resultSize > maxDirectResultSize) {
val blockId = TaskResultBlockId(taskId)
env.blockManager.putBytes(
blockId,
new ChunkedByteBuffer(serializedDirectResult.duplicate()),
StorageLevel.MEMORY_AND_DISK_SER)
logInfo(
s"Finished $taskName (TID $taskId). $resultSize bytes result sent via BlockManager)")
ser.serialize(new IndirectTaskResult[Any](blockId, resultSize))
} else {
logInfo(s"Finished $taskName (TID $taskId). $resultSize bytes result sent to driver")
serializedDirectResult
}
}
execBackend.statusUpdate(taskId, TaskState.FINISHED, serializedResult)
} catch {
case ffe: FetchFailedException =>
val reason = ffe.toTaskEndReason
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.FAILED, ser.serialize(reason))
case _: TaskKilledException | _: InterruptedException if task.killed =>
logInfo(s"Executor killed $taskName (TID $taskId)")
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.KILLED, ser.serialize(TaskKilled))
case CausedBy(cDE: CommitDeniedException) =>
val reason = cDE.toTaskEndReason
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.FAILED, ser.serialize(reason))
case t: Throwable =>
// Attempt to exit cleanly by informing the driver of our failure.
// If anything goes wrong (or this was a fatal exception), we will delegate to
// the default uncaught exception handler, which will terminate the Executor.
logError(s"Exception in $taskName (TID $taskId)", t)
// Collect latest accumulator values to report back to the driver
val accums: Seq[AccumulatorV2[_, _]] =
if (task != null) {
task.metrics.setExecutorRunTime(System.currentTimeMillis() - taskStart)
task.metrics.setJvmGCTime(computeTotalGcTime() - startGCTime)
task.collectAccumulatorUpdates(taskFailed = true)
} else {
Seq.empty
}
val accUpdates = accums.map(acc => acc.toInfo(Some(acc.value), None))
val serializedTaskEndReason = {
try {
ser.serialize(new ExceptionFailure(t, accUpdates).withAccums(accums))
} catch {
case _: NotSerializableException =>
// t is not serializable so just send the stacktrace
ser.serialize(new ExceptionFailure(t, accUpdates, false).withAccums(accums))
}
}
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.FAILED, serializedTaskEndReason)
// Don't forcibly exit unless the exception was inherently fatal, to avoid
// stopping other tasks unnecessarily.
if (Utils.isFatalError(t)) {
SparkUncaughtExceptionHandler.uncaughtException(t)
}
} finally {
runningTasks.remove(taskId)
}
}














 258
258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









