







前言:
在大型爬虫项目中,使用分布式架构是提高爬取效率的唯一途径。设计一个合理的分布式架构对项目、对个人都有很大的好处,接下来说说分布式架构应该具有的特性:
- 分布式。这是最基本也是最核心的特性,分布式将允许我们通过横向扩展主机资源来提高爬取效率。
- 易扩展、易部署。当我们想要增加要爬取的网站时,只需要专注于爬取规则、解析规则、入库规则部分的代码编写就ok,其他的如日志、异常处理则让底层架构实现。
- 各功能高度模块化。模块化有利于架构的松耦合,以至于以后想要添加新的功能无需进行大的改动;同时也使得整个架构更清晰简明。
- 可监控。通过架构部署启动爬虫之后,可以通过某种方式监控Request队列实时大小、已入库的Item条数,以确认爬虫工作状态。
- 高性能。即使在单机上部署此架构也能充分利用主机CPU、带宽等资源,比较耗时的主要是下载页面和入库两个环节,当Request队列不断增长的时候,消费Request的能力也必须跟上,否则队列会消耗过多内存资源,且爬取效率低。入库同理,这两个环节都是IO密集型任务,所以恰好可以利用python的多线程来提高效率。
- Request队列、去重集合的持久化,实现断点续爬和增量爬取。
详细说明:
架构图如下:
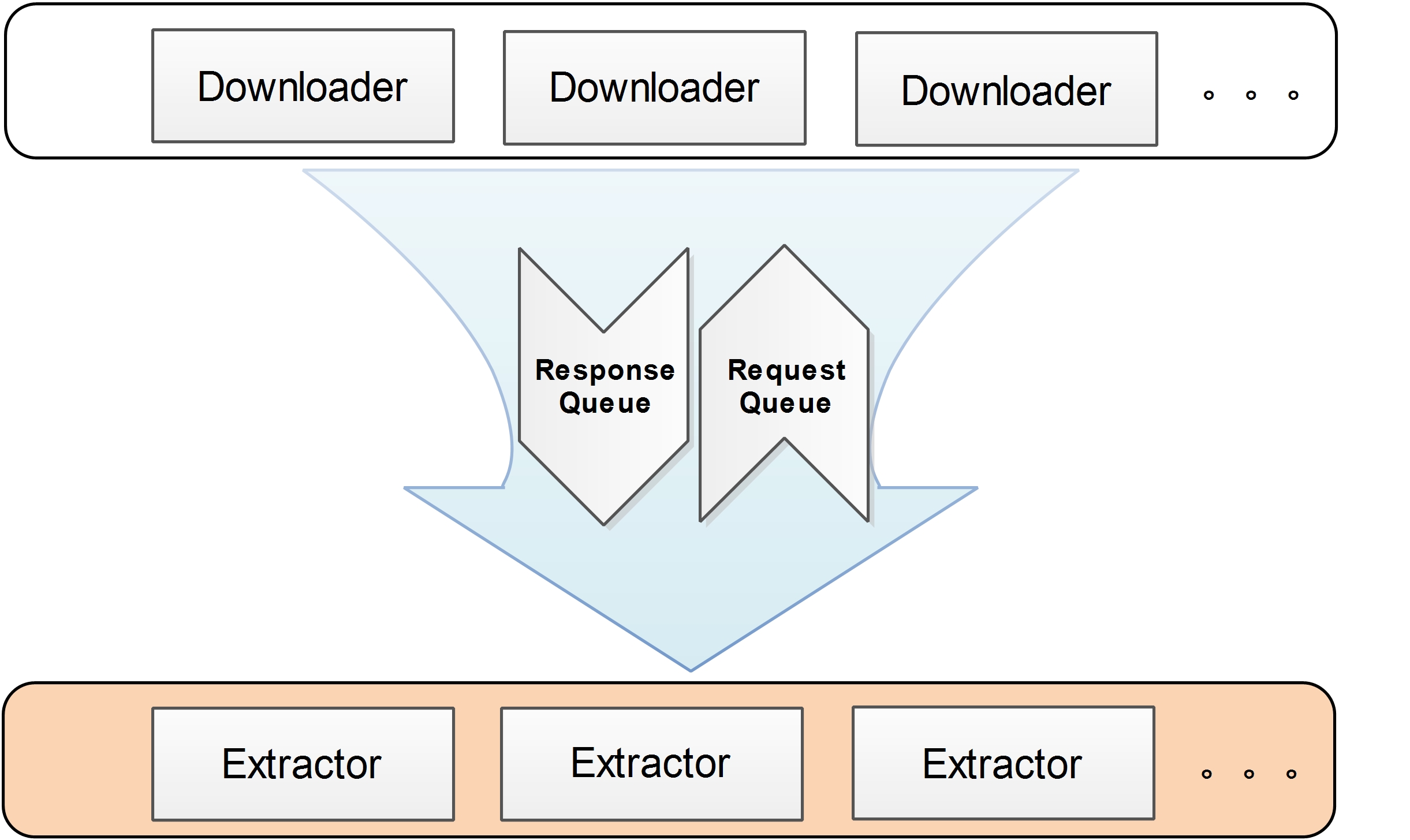
下图为爬虫运行的流程模型:
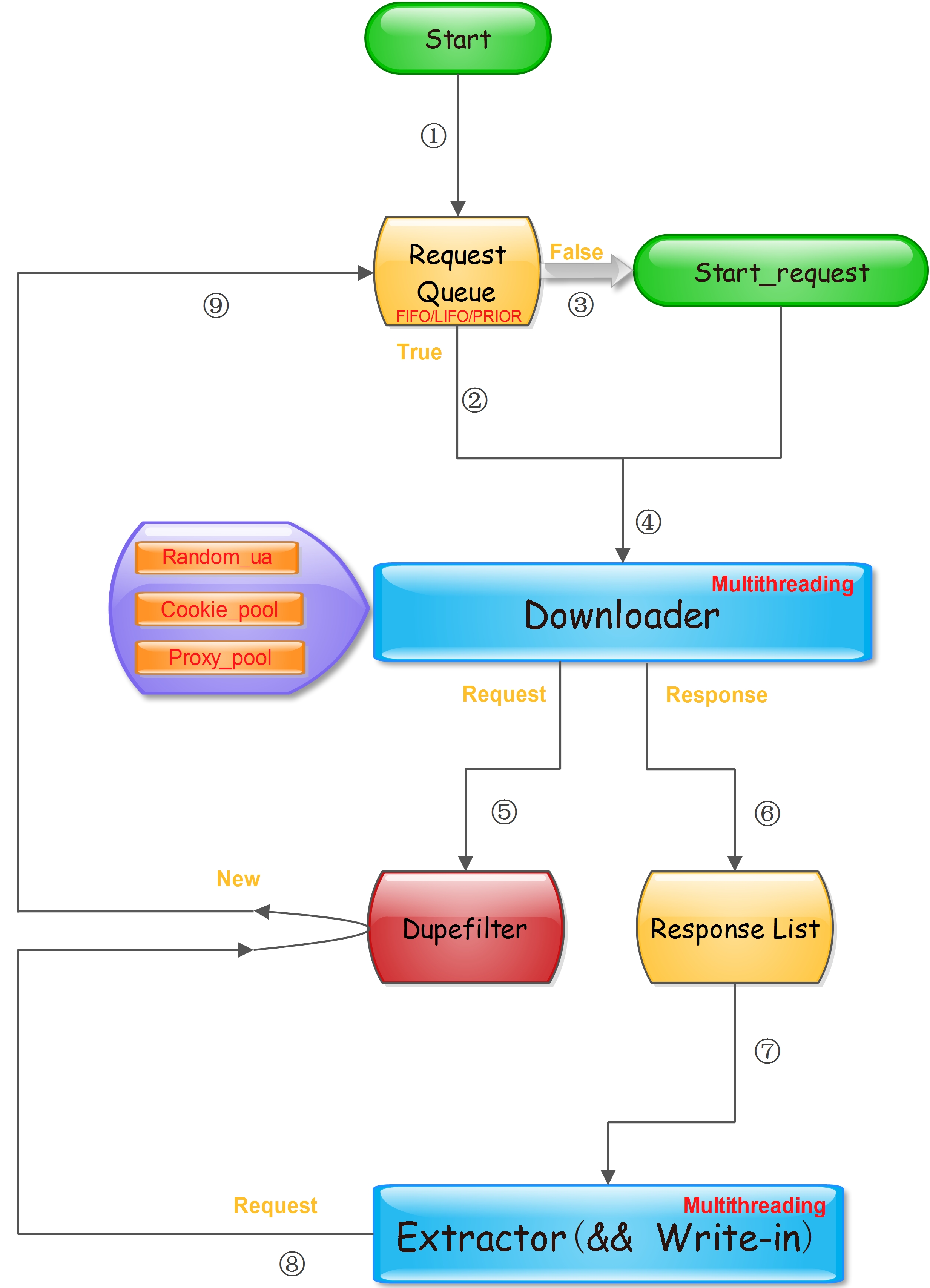
架构主要分两部分,下载器(Downloader)和提取器(Extractor)。下载器专注于数据的下载,可为下载器配置UA池或fake_useragent、cookie池、代理IP池(需要本地维护),不会做任何数据处理任务,下载成功后将数据写入Redis中定义好的Response List,并将用于下载的Request写入Dupefilter;提取器就会从Response List中拉取Response进行解析,不同网站使用不同key存储List。这里使用Redis作为Response中转是因为当运行的下载器数量较多时,返回大量的Response不一定能被提取器及时解析入库(数据库存储量达到一定级别后,磁盘IO可能大于网络IO),若放在内存中可能由于程序意外停止而丢失已经下载的Response(未入库)。
Dupefilter:使用BloomFilter可以有效节省去重集合对内存的消耗,取Redis中的256M字符串可对9000万条Url进行去重,漏失率为1.12e-04,漏失率和去重Url的数量关系可参考基于Redis的Bloomfilter去重,也就是说漏失率是可以控制的。
Request Queue:此队列可采用Redis的List或Zset数据类型实现,前者实现FIFO和LIFO队列,后者实现PRORI队列
Downloader和Extractor都可以分布式部署,只需配置好Redis服务的网络地址。两者的多线程部署有助于充分利用单机的带宽资源,CPU利用率提升可能不明显,爬虫始终是偏IO密集型的活动。
Request和Response:Request对象可作为一个字典来存,字典包含请求的url、cookie、headers、body、params、method以及others属性,Response也作为一个字典,包含下载到的html、cookies、headers、url以及others属性;这会有利于复杂页面的抓取。
声明:本文章为个人对技术的理解与总结,不保证100%正确,接收网友的斧正。
个人设计思想,转载请注明出处!(https://blog.csdn.net/sc_lilei/article/details/80160346)














 1859
1859











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









