







以下内容为结合李沐老师的课程和教材补充的学习笔记,以及对课后练习的一些思考,自留回顾,也供同学之人交流参考。
本节课程地址:模型构造_哔哩哔哩_bilibili
本节教材地址:5.1. 层和块 — 动手学深度学习 2.0.0 documentation (d2l.ai)
本节开源代码:...>d2l-zh>pytorch>chapter_multilayer-perceptrons>model-construction.ipynb
层和块
之前首次介绍神经网络时,我们关注的是具有单一输出的线性模型。 在这里,整个模型只有一个输出。 注意,单个神经网络 (1)接受一些输入; (2)生成相应的标量输出; (3)具有一组相关 参数(parameters),更新这些参数可以优化某目标函数。
然后,当考虑具有多个输出的网络时, 我们利用矢量化算法来描述整层神经元。 像单个神经元一样,层(1)接受一组输入, (2)生成相应的输出, (3)由一组可调整参数描述。 当我们使用softmax回归时,一个单层本身就是模型。 然而,即使我们随后引入了多层感知机,我们仍然可以认为该模型保留了上面所说的基本架构。
对于多层感知机而言,整个模型及其组成层都是这种架构。 整个模型接受原始输入(特征),生成输出(预测), 并包含一些参数(所有组成层的参数集合)。 同样,每个单独的层接收输入(由前一层提供), 生成输出(到下一层的输入),并且具有一组可调参数, 这些参数根据从下一层反向传播的信号进行更新。
事实证明,研究讨论“比单个层大”但“比整个模型小”的组件更有价值。 例如,在计算机视觉中广泛流行的ResNet-152架构就有数百层, 这些层是由层组(groups of layers)的重复模式组成。 这个ResNet架构赢得了2015年ImageNet和COCO计算机视觉比赛 的识别和检测任务 (链接:[1512.03385] Deep Residual Learning for Image Recognition (arxiv.org))。 目前ResNet架构仍然是许多视觉任务的首选架构。 在其他的领域,如自然语言处理和语音, 层组以各种重复模式排列的类似架构现在也是普遍存在。
为了实现这些复杂的网络,我们引入了神经网络块的概念。 块(block)可以描述单个层、由多个层组成的组件或整个模型本身。 使用块进行抽象的一个好处是可以将一些块组合成更大的组件, 这一过程通常是递归的,如 下图所示。 通过定义代码来按需生成任意复杂度的块, 我们可以通过简洁的代码实现复杂的神经网络。
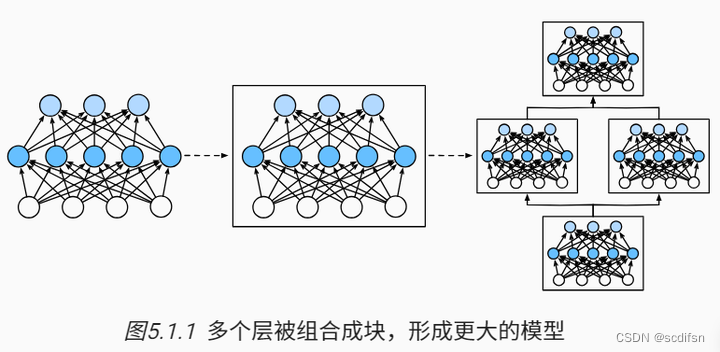
从编程的角度来看,块由类(class)表示。 它的任何子类都必须定义一个将其输入转换为输出的前向传播函数, 并且必须存储任何必需的参数。 注意,有些块不需要任何参数。 最后,为了计算梯度,块必须具有反向传播函数。 在定义我们自己的块时,由于自动微分(在 2.5节 中引入) 提供了一些后端实现,我们只需要考虑前向传播函数和必需的参数。
在构造自定义块之前,(我们先回顾一下多层感知机) ( 4.3节 )的代码。 下面的代码生成一个网络,其中包含一个具有256个单元和ReLU激活函数的全连接隐藏层, 然后是一个具有10个隐藏单元且不带激活函数的全连接输出层。
import torch
from torch import nn
from torch.nn import functional as F
net = nn.Sequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))
X = torch.rand(2, 20)
net(X)输出结果:
tensor([[ 0.1578, -0.0094, -0.0768, 0.0775, -0.0511, -0.0383, -0.3330, -0.0069,
0.0613, 0.0126],
[ 0.2700, 0.0188, -0.1147, 0.0824, -0.0894, -0.1386, -0.4153, 0.0287,
-0.0189, -0.1537]], grad_fn=<AddmmBackward0>)
在这个例子中,我们通过实例化nn.Sequential来构建我们的模型, 层的执行顺序是作为参数传递的。 简而言之,(nn.Sequential定义了一种特殊的Module), 即在PyTorch中表示一个块的类, 它维护了一个由Module组成的有序列表。 注意,两个全连接层都是Linear类的实例, Linear类本身就是Module的子类。 另外,到目前为止,我们一直在通过net(X)调用我们的模型来获得模型的输出。 这实际上是net.__call__(X)的简写。 这个前向传播函数非常简单: 它将列表中的每个块连接在一起,将每个块的输出作为下一个块的输入。
[自定义块]
要想直观地了解块是如何工作的,最简单的方法就是自己实现一个。 在实现我们自定义块之前,我们简要总结一下每个块必须提供的基本功能。
- 将输入数据作为其前向传播函数的参数。
- 通过前向传播函数来生成输出。请注意,输出的形状可能与输入的形状不同。例如,我们上面模型中的第一个全连接的层接收一个20维的输入,但是返回一个维度为256的输出。
- 计算其输出关于输入的梯度,可通过其反向传播函数进行访问。通常这是自动发生的。
- 存储和访问前向传播计算所需的参数。
- 根据需要初始化模型参数。
在下面的代码片段中,我们从零开始编写一个块。 它包含一个多层感知机,其具有256个隐藏单元的隐藏层和一个10维输出层。 注意,下面的MLP类继承了表示块的类。 我们的实现只需要提供我们自己的构造函数(Python中的__init__函数)和前向传播函数。
# (nn.Module)继承Module子类
class MLP(nn.Module):
# 用模型参数声明层。这里,我们声明两个全连接的层
def __init__(self):
# 调用MLP的父类Module的构造函数来执行必要的初始化。
# 这样,在类实例化时也可以指定其他函数参数,例如模型参数params(稍后将介绍)
super().__init__()
self.hidden = nn.Linear(20, 256) # 隐藏层
self.out = nn.Linear(256, 10) # 输出层
# 定义模型的前向传播,即如何根据输入X返回所需的模型输出
def forward(self, X):
# 注意,这里我们使用ReLU的函数版本,其在nn.functional模块中定义。
return self.out(F.relu(self.hidden(X)))我们首先看一下前向传播函数,它以X作为输入, 计算带有激活函数的隐藏表示,并输出其未规范化的输出值。 在这个MLP实现中,两个层都是实例变量。 要了解这为什么是合理的,可以想象实例化两个多层感知机(net1和net2), 并根据不同的数据对它们进行训练。 当然,我们希望它们学到两种不同的模型。
接着我们[实例化多层感知机的层,然后在每次调用前向传播函数时调用这些层]。 注意一些关键细节: 首先,我们定制的__init__函数通过super().__init__() 调用父类的__init__函数, 省去了重复编写模版代码的痛苦。 然后,我们实例化两个全连接层, 分别为self.hidden和self.out。 注意,除非我们实现一个新的运算符, 否则我们不必担心反向传播函数或参数初始化, 系统将自动生成这些。
我们来试一下这个函数:
net = MLP()
net(X)输出结果:
tensor([[-0.0472, 0.0444, 0.3212, -0.0224, 0.0760, 0.0742, -0.1411, -0.0580,
-0.0033, 0.0129],
[-0.0236, 0.0465, 0.3362, -0.0675, 0.0688, 0.0492, -0.1005, -0.1274,
0.0542, 0.0744]], grad_fn=<AddmmBackward0>)
块的一个主要优点是它的多功能性。 我们可以子类化块以创建层(如全连接层的类)、 整个模型(如上面的MLP类)或具有中等复杂度的各种组件。 我们在接下来的章节中充分利用了这种多功能性, 比如在处理卷积神经网络时。
[顺序块]
现在我们可以更仔细地看看Sequential类是如何工作的, 回想一下Sequential的设计是为了把其他模块串起来。 为了构建我们自己的简化的MySequential, 我们只需要定义两个关键函数:
- 一种将块逐个追加到列表中的函数;
- 一种前向传播函数,用于将输入按追加块的顺序传递给块组成的“链条”。
下面的MySequential类提供了与默认Sequential类相同的功能。
class MySequential(nn.Module):
def __init__(self, *args):
super().__init__()
for idx, module in enumerate(args):
# 这里,module是Module子类的一个实例。我们把它保存在'Module'类的成员
# 变量_modules中。_module的类型是OrderedDict
self._modules[str(idx)] = module
def forward(self, X):
# OrderedDict保证了按照成员添加的顺序遍历它们
for block in self._modules.values():
X = block(X)
return X__init__函数将每个模块逐个添加到有序字典_modules中。 读者可能会好奇为什么每个Module都有一个_modules属性? 以及为什么我们使用它而不是自己定义一个Python列表? 简而言之,_modules的主要优点是: 在模块的参数初始化过程中, 系统知道在_modules字典中查找需要初始化参数的子块。
当MySequential的前向传播函数被调用时, 每个添加的块都按照它们被添加的顺序执行。 现在可以使用我们的MySequential类重新实现多层感知机。
net = MySequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))
net(X)输出结果:
tensor([[-0.1963, 0.0103, -0.2702, -0.0204, -0.1183, -0.1163, 0.2095, -0.0391,
0.0355, 0.0535],
[-0.0805, 0.1367, -0.3747, 0.0361, -0.0268, 0.0286, 0.2046, -0.0678,
0.0893, 0.0375]], grad_fn=<AddmmBackward0>)
请注意,MySequential的用法与之前为Sequential类编写的代码相同 (如 4.3节 中所述)。
[在前向传播函数中执行代码]
Sequential类使模型构造变得简单, 允许我们组合新的架构,而不必定义自己的类。 然而,并不是所有的架构都是简单的顺序架构。 当需要更强的灵活性时,我们需要定义自己的块。 例如,我们可能希望在前向传播函数中执行Python的控制流。 此外,我们可能希望执行任意的数学运算, 而不是简单地依赖预定义的神经网络层。
到目前为止, 我们网络中的所有操作都对网络的激活值及网络的参数起作用。 然而,有时我们可能希望合并既不是上一层的结果也不是可更新参数的项, 我们称之为常数参数(constant parameter)。 例如,我们需要一个计算函数 的层, 其中
是输入,
是参数,
是某个在优化过程中没有更新的指定常量。 因此我们实现了一个
FixedHiddenMLP类,如下所示:
class FixedHiddenMLP(nn.Module):
def __init__(self):
super().__init__()
# 不计算梯度的随机权重参数。因此其在训练期间保持不变
self.rand_weight = torch.rand((20, 20), requires_grad=False)
self.linear = nn.Linear(20, 20)
def forward(self, X):
X = self.linear(X)
# 使用创建的常量参数以及relu和mm函数
X = F.relu(torch.mm(X, self.rand_weight) + 1)
# 复用全连接层。这相当于两个全连接层共享参数
X = self.linear(X)
# 控制流
while X.abs().sum() > 1:
X /= 2
return X.sum()在这个FixedHiddenMLP模型中,我们实现了一个隐藏层, 其权重(self.rand_weight)在实例化时被随机初始化,之后为常量。 这个权重不是一个模型参数,因此它永远不会被反向传播更新。 然后,神经网络将这个固定层的输出通过一个全连接层。
注意,在返回输出之前,模型做了一些不寻常的事情: 它运行了一个while循环,在 𝐿1 范数大于 1 的条件下, 将输出向量除以 2 ,直到它满足条件为止。 最后,模型返回了X中所有项的和。 注意,此操作可能不会常用于在任何实际任务中, 我们只展示如何将任意代码集成到神经网络计算的流程中。
net = FixedHiddenMLP()
net(X)输出结果:
tensor(0.0855, grad_fn=<SumBackward0>)
我们可以[混合搭配各种组合块的方法]。 在下面的例子中,我们以一些想到的方法嵌套块。
class NestMLP(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(nn.Linear(20, 64), nn.ReLU(),
nn.Linear(64, 32), nn.ReLU())
self.linear = nn.Linear(32, 16)
def forward(self, X):
return self.linear(self.net(X))
chimera = nn.Sequential(NestMLP(), nn.Linear(16, 20), FixedHiddenMLP())
chimera(X)输出结果:
tensor(-0.1326, grad_fn=<SumBackward0>)
效率
读者可能会开始担心操作效率的问题。 毕竟,我们在一个高性能的深度学习库中进行了大量的字典查找、 代码执行和许多其他的Python代码。 Python的问题全局解释器锁 是众所周知的。 在深度学习环境中,我们担心速度极快的GPU可能要等到CPU运行Python代码后才能运行另一个作业。
小结
- 一个块可以由许多层组成;一个块可以由许多块组成。
- 块可以包含代码。
- 块负责大量的内部处理,包括参数初始化和反向传播。
- 层和块的顺序连接由
Sequential块处理。
练习
- 如果将
MySequential中存储块的方式更改为Python列表,会出现什么样的问题?
解:
如下代码比较结果,将MySequential中存储块的方式为OreredDict或Python列表,net输出结果不一样。
可能的原因为:虽然Python列表是有序的,但是它不像 OrderedDict 那样保证元素的插入顺序。因此,使用Python 列表可能会导致模块的执行顺序不确定,这可能会对网络的前向传播和后向传播产生影响,导致结果不同。
代码如下:
class MySequential_5_1_1(nn.Module):
def __init__(self, *args):
super().__init__()
# 用list存储块
self.sequential = []
for module in args:
self.sequential.append(module)
def forward(self, X):
for block in self.sequential:
X = block(X)
return X
net1 = MySequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))
print(net1(X))
net2 = MySequential_5_1_1(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))
print(net2(X))输出结果:
tensor([[-0.1604, -0.0737, 0.3145, 0.0593, 0.1041, -0.0567, -0.0969, -0.3031,
-0.1152, 0.1059],
[-0.0180, -0.0756, 0.3157, 0.0496, 0.1485, -0.0121, -0.0993, -0.3859,
-0.0600, 0.1425]], grad_fn=<AddmmBackward0>)
tensor([[ 0.0670, 0.0163, -0.0282, -0.1333, -0.0316, -0.3096, -0.1089, 0.0824,
0.0277, 0.2236],
[ 0.1538, -0.0106, -0.0490, -0.0671, 0.1366, -0.3202, -0.0580, 0.1140,
0.1697, 0.2760]], grad_fn=<AddmmBackward0>)
2. 实现一个块,它以两个块为参数,例如net1和net2,并返回前向传播中两个网络的串联输出。这也被称为平行块。
解:
代码如下:
class Block_5_1_2(nn.Module):
def __init__(self, net1, net2):
super().__init__()
self.block1 = net1
self.block2 = net2
def forward(self, X):
return torch.cat((net1(X), net2(X)), dim=1)
block = Block_5_1_2(net1, net2)
print(net1(X))
print(net2(X))
print(block(X))输出结果:
tensor([[-0.1653, -0.0994, 0.1964, -0.0494, 0.0515, 0.0385, -0.0950, -0.2812,
-0.1394, 0.0541],
[-0.1145, -0.0389, 0.1077, -0.0683, 0.1238, 0.1027, -0.0905, -0.3324,
-0.0806, -0.1222]], grad_fn=<AddmmBackward0>)
tensor([[ 0.0085, 0.0565, -0.1319, -0.0749, -0.0120, -0.2857, -0.1574, 0.1393,
0.0417, 0.1513],
[ 0.2507, -0.1259, 0.0380, -0.0848, 0.0518, -0.2206, -0.1449, 0.1044,
0.1401, 0.2763]], grad_fn=<AddmmBackward0>)
tensor([[-0.1653, -0.0994, 0.1964, -0.0494, 0.0515, 0.0385, -0.0950, -0.2812,
-0.1394, 0.0541, 0.0085, 0.0565, -0.1319, -0.0749, -0.0120, -0.2857,
-0.1574, 0.1393, 0.0417, 0.1513],
[-0.1145, -0.0389, 0.1077, -0.0683, 0.1238, 0.1027, -0.0905, -0.3324,
-0.0806, -0.1222, 0.2507, -0.1259, 0.0380, -0.0848, 0.0518, -0.2206,
-0.1449, 0.1044, 0.1401, 0.2763]], grad_fn=<CatBackward0>)
3. 假设我们想要连接同一网络的多个实例。实现一个函数,该函数生成同一个块的多个实例,并在此基础上构建更大的网络。
解:
代码如下:
def create_network(block, num_instances):
# 用dict存储多个实例
network = nn.Sequential()
for i in range(num_instances):
network.add_module(f'block_{i+1}', block)
return network
network = create_network(NestMLP(), 5)
print(network)输出结果:
Sequential(
(block_1): NestMLP(
(net): Sequential(
(0): Linear(in_features=20, out_features=64, bias=True)
(1): ReLU()
(2): Linear(in_features=64, out_features=32, bias=True)
(3): ReLU()
)
(linear): Linear(in_features=32, out_features=16, bias=True)
)
(block_2): NestMLP(
(net): Sequential(
(0): Linear(in_features=20, out_features=64, bias=True)
(1): ReLU()
(2): Linear(in_features=64, out_features=32, bias=True)
(3): ReLU()
)
(linear): Linear(in_features=32, out_features=16, bias=True)
)
(block_3): NestMLP(
(net): Sequential(
(0): Linear(in_features=20, out_features=64, bias=True)
(1): ReLU()
(2): Linear(in_features=64, out_features=32, bias=True)
(3): ReLU()
)
(linear): Linear(in_features=32, out_features=16, bias=True)
)
(block_4): NestMLP(
(net): Sequential(
(0): Linear(in_features=20, out_features=64, bias=True)
(1): ReLU()
(2): Linear(in_features=64, out_features=32, bias=True)
(3): ReLU()
)
(linear): Linear(in_features=32, out_features=16, bias=True)
)
(block_5): NestMLP(
(net): Sequential(
(0): Linear(in_features=20, out_features=64, bias=True)
(1): ReLU()
(2): Linear(in_features=64, out_features=32, bias=True)
(3): ReLU()
)
(linear): Linear(in_features=32, out_features=16, bias=True)
)
)
















 349
349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











