







RDD创建了, 就可以进行一些列的转换操作了。Spark算子分为Transformation算子和Action算子。其中Transformation算子可以将RDD转换成新的RDD,Action算子将RDD消化,在控制台打印或者持久化到文件系统或数据库。
Spark 算子详解(一)
1. Transformation 算子
Transformation 具有Lazy 特性,操作是延迟计算的。也就是说从一个RDD转换成另一个RDD的转换操作不是马上执行,需要等到有Action操作或者CheckPoint 操作时,才真正触发操作。
通过Lazy 特性底层的Spark程序才能对应用程序进行优化。因为一直是延迟执行的Spark框架能够观察到很多运算步骤,观察到的越多,对其进行优化的机会就越多。
看下面这个例子说明Transformation的Lazy 特性:
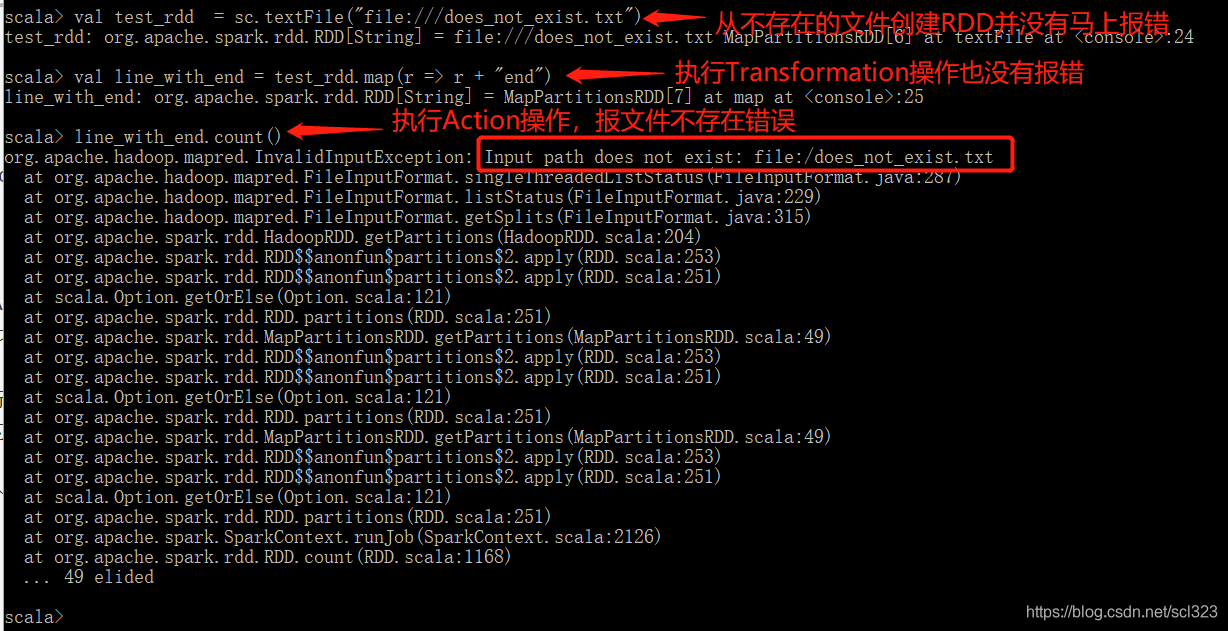
从一个不存在的文件上创建RDD,只要还没执行到Action操作都不会报文件不存在的错误, 只有到执行Action操作的时候才会报错,说明到Action操作才会执行前面的Transformation操作。
注意:所以你如果通过集合创建RDD,在Action操作执行之前,修改了集合里面的内容,那最后执行Action操作时这个创建的RDD就是你修改之后的内容。
Transformation算子有很多,这些除了私有方法都是Transformation算子(绿色锁是公共方法, 橙色锁是私有方法)

1.1 map
映射
首先看源码:
/**
* 通过将函数应用于此RDD的所有元素来返回新的RDD
*/
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f) // clean方法实际上调用了ClosureCleaner的clean方法,这里一再清除闭包中的不能序列化的变量,防止RDD在网络传输过程中反序列化失败。
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF)) // 可以看到其实最终是调用Iterator的map方法
}
| 分区数 | 元素个数 |
|---|---|
| 输入 = 输出 | 输入 = 输出 |
- map算子输入分区和输出分区是一对一关系(输入与输出分区关系涉及到stage划分, 具体可看我的博客重拾Spark 之day04–Spark RDD )
例子:
后面算子的例子如无特殊说明都在spark-shell终端中
scala> val rdd = sc.parallelize(Array("hello world", "hello nick", "hello spark", "nick spark"))
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[0] at parallelize at <console>:27
scala> val maped_rdd = rdd.map(_.toUpperCase)
maped_rdd: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[1] at map at <console>:29
scala> maped_rdd.collect() // 这里collect是Action算子, 这里主要用来查看rdd内容的。
res0: Array[String] = Array(HELLO WORLD, HELLO NICK, HELLO SPARK, NICK SPARK)
1.2 flatMap
展平映射
/**
* 通过首先将函数应用于此
* RDD的所有元素,然后展平结果,返回新的RDD。
*/
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.flatMap(cleanF)) // Iterator 的flatMap方法
}
| 分区数 | 元素个数 |
|---|---|
| 输入 = 输出 | 输入 <= 输出 |
- 如果传进去的函数的返回值是String类型的话, 那么将会按字符序列展平, 并不是你期望的那样。
例子:
scala> val src_rdd = sc.parallelize(Array("hello world","hello nick", "i love you")) src_rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[0] at parallelize at <console>:27 scala> val flatMaped_rdd = src_rdd.flatMap(_.toUpperCase) flatMaped_rdd: org.apache.spark.rdd.RDD[Char] = MapPartitionsRDD[1] at flatMap at <console>:29 scala> flatMaped_rdd.collect() res0: Array[Char] = Array(H, E, L, L, O, , W, O, R, L, D,H, E, L, L, O, , N, I, C, K, I, , L, O, V, E, , Y, O, U)
如果源RDD里面的每个元素没有先转换成Iterator的话, 就会自动把String转成字符数组
scala> val new_flatMaped_rdd = src_rdd.flatMap(_.split(" ").map(_.toUpperCase)) new_flatMaped_rdd: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at flatMap at <console>:29 scala> new_flatMaped_rdd.collect() res1: Array[String] = Array(HELLO, WORLD, HELLO, NICK, I, LOVE, YOU)
返回元组也行
scala> val pair_flatMaped_rdd= src_rdd.flatMap(_.split(" ").map((_,1))) pair_flatMaped_rdd: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[3] at flatMap at <console>:29 scala> pair_flatMaped_rdd.collect() res2: Array[(String, Int)] = Array((hello,1), (world,1), (hello,1), (nick,1), (i,1), (love,1), (you,1))
1.3 filter
对元素过滤
/**
* 返回仅包含满足谓词的元素的新RDD。
*/
def filter(f: T => Boolean): RDD[T] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[T, T](
this,
(context, pid, iter) => iter.filter(cleanF),
preservesPartitioning = true)
}
| 分区数 | 元素个数 |
|---|---|
| 输入 = 输出 | 输入 >= 输出 |
- 保留的是条件为真的
例子:
scala> val rdd = sc.parallelize(Array("hello world", "hello nick", "hello spark", "nick spark"))
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[2] at parallelize at <console>:27
scala> val filtered_rdd = rdd.filter(_.length == 11)
filtered_rdd: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[3] at filter at <console>:29
scala> filtered_rdd.collect()
res1: Array[String] = Array(hello world, hello spark)
1.4 distinct
对元素去重
/**
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
}
/**
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(): RDD[T] = withScope {
distinct(partitions.length)
}
| 分区数 | 元素个数 |
|---|---|
| 看是否重新分区, 如果是无参distinct则输入=输出 | 输入 >= 输出 |
- distinct 有两个方法, 一个是带参数的numPartitions, 一个是不带的; 带参数的可以重新分区, 按参数分区, 没带参数的跟之前分区一样
例子:
scala> val rdd = sc.parallelize(Array("hello", "world", "hello", "nick", "hello", "spark", "nick", "spark"))
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[4] at parallelize at <console>:27
scala> val distincted_rdd = rdd.distinct()
distincted_rdd: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[7] at distinct at <console>:29
scala> distincted_rdd.collect()
res2: Array[String] = Array(hello, world, spark, nick)
1.5 repartition
重新分区, 可以增加分区也可以减少分区, 不管增加还是减少分区都会shuffle, 所以减少分区建议使用coalesce
/**
* 返回一个具有numPartitions分区的新RDD
*
* 可以增加或减少此RDD中的并行度。在内部,它使用
* shuffle来重新分配数据。
*
* 如果要减少此RDD中的分区数,请考虑使用coalesce方法,
* 这可以避免执行shuffle。
*/
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
| 分区数 | 元素个数 |
|---|---|
| 看numPartitions是否比原来大 | 输入 = 输出 |
- 正如注释上所说, repartition会通过shuffle来重新分区, 涉及到shuffle会影响性能, 所以如果是减少分区可以使用coalesce方法, 可以避免执行shuffle
- 重新分区会返回一个新的RDD, 老的RDD还是原来分区数。
例子:
scala> val rdd = sc.parallelize(Array("hello", "world", "hello", "nick", "hello", "spark", "nick", "spark"))
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[14] at parallelize at <console>:27
scala> rdd.getNumPartitions
res10: Int = 2
scala> val repartitioned_rdd = rdd.repartition(4)
repartitioned_rdd: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[18] at repartition at <console>:29
scala> repartitioned_rdd.getNumPartitions
res11: Int = 4
scala> repartitioned_rdd.collect()
res12: Array[String] = Array(world, spark, hello, nick, nick, spark, hello, hello)
scala> rdd.getNumPartitions
res13: Int = 2
1.6 coalesce
减少分区数, 不用shuffle
/**
* Return a new RDD that is reduced into `numPartitions` partitions.
*
* This results in a narrow dependency, e.g. if you go from 1000 partitions
* to 100 partitions, there will not be a shuffle, instead each of the 100
* new partitions will claim 10 of the current partitions.
*
* However, if you're doing a drastic coalesce, e.g. to numPartitions = 1,
* this may result in your computation taking place on fewer nodes than
* you like (e.g. one node in the case of numPartitions = 1). To avoid this,
* you can pass shuffle = true. This will add a shuffle step, but means the
* current upstream partitions will be executed in parallel (per whatever
* the current partitioning is).
*
* Note: With shuffle = true, you can actually coalesce to a larger number
* of partitions. This is useful if you have a small number of partitions,
* say 100, potentially with a few partitions being abnormally large. Calling
* coalesce(1000, shuffle = true) will result in 1000 partitions with the
* data distributed using a hash partitioner.
*/
def coalesce(numPartitions: Int, shuffle: Boolean = false)(implicit ord: Ordering[T] = null)
: RDD[T] = withScope {
if (shuffle) {
/** Distributes elements evenly across output partitions, starting from a random partition. */
val distributePartition = (index: Int, items: Iterator[T]) => {
var position = (new Random(index)).nextInt(numPartitions)
items.map { t =>
// Note that the hash code of the key will just be the key itself. The HashPartitioner
// will mod it with the number of total partitions.
position = position + 1
(position, t)
}
} : Iterator[(Int, T)]
// include a shuffle step so that our upstream tasks are still distributed
new CoalescedRDD(
new ShuffledRDD[Int, T, T](mapPartitionsWithIndex(distributePartition),
new HashPartitioner(numPartitions)),
numPartitions).values
} else {
new CoalescedRDD(this, numPartitions)
}
}
| 分区数 | 元素个数 |
|---|---|
| 看numPartitions是否比原来大 | 输入 = 输出 |
- 如果是需要减小分区数, 则参数shuffle只需要是默认为false就可以, 它会均匀的把分区合并起来, 假设原来分区1000个, 现在想缩小到100个, 那么每10个分区会合并成一个分区。
- 如果是要增加分区数, 则参数shuffle值要为true,内部会进行shuffle操作, 把数据重新分区成numPartitions
例子:
scala> val rdd = sc.parallelize(Array("hello", "world", "hello", "nick", "hello", "spark", "nick", "spark"))
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[19] at parallelize at <console>:27
scala> rdd.getNumPartitions
res14: Int = 2
scala> val coalesceed_rdd = rdd.coalesce(1)
coalesceed_rdd: org.apache.spark.rdd.RDD[String] = CoalescedRDD[20] at coalesce at <console>:29
scala> rdd.getNumPartitions
res15: Int = 2
scala> coalesceed_rdd.getNumPartitions
res16: Int = 1
scala> coalesceed_rdd.collect()
res17: Array[String] = Array(hello, world, hello, nick, hello, spark, nick, spark)
1.7 sample
取样函数
/**
* 返回此RDD的取样子集
*
* @param withReplacement 可以多次对元素进行采样(在采样时替换)
* @param fraction 预期的样本大小作为该RDD大小的一部分
* without replacement: 选择每个元素的概率;fraction必须为[0,1]
* with replacement: 预期每个元素的选择次数;fraction必须 >= 0
* @param seed 随机数发生器的种子
*/
def sample(
withReplacement: Boolean,
fraction: Double,
seed: Long = Utils.random.nextLong): RDD[T] = withScope {
require(fraction >= 0.0, "Negative fraction value: " + fraction)
if (withReplacement) {
new PartitionwiseSampledRDD[T, T](this, new PoissonSampler[T](fraction), true, seed)
} else {
new PartitionwiseSampledRDD[T, T](this, new BernoulliSampler[T](fraction), true, seed)
}
}
先发布一下, 持续更新, 敬请关注…














 259
259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









