










本文转载来源自:http://blog.csdn.net/teaspring/article/details/75390210
感谢原作者teaspring的分享。本文已经得到原作者的转载许可。
在Ethereum的世界里,数据的最终存储形式是[k,v]键值对,目前使用的[k,v]型底层数据库是LevelDB;所有与交易,操作相关的数据,其呈现的集合形式是Block(Header);如果以Block为单位链接起来,则构成更大粒度的BlockChain(HeaderChain);若以Block作切割,那么Transaction和Contract就是更小的粒度;所有交易或操作的结果,将以各个个体账户的状态(state)存在,账户的呈现形式是stateObject,所有账户的集合受StateDB管理。下图描绘了上述各数据单元的层次关系:
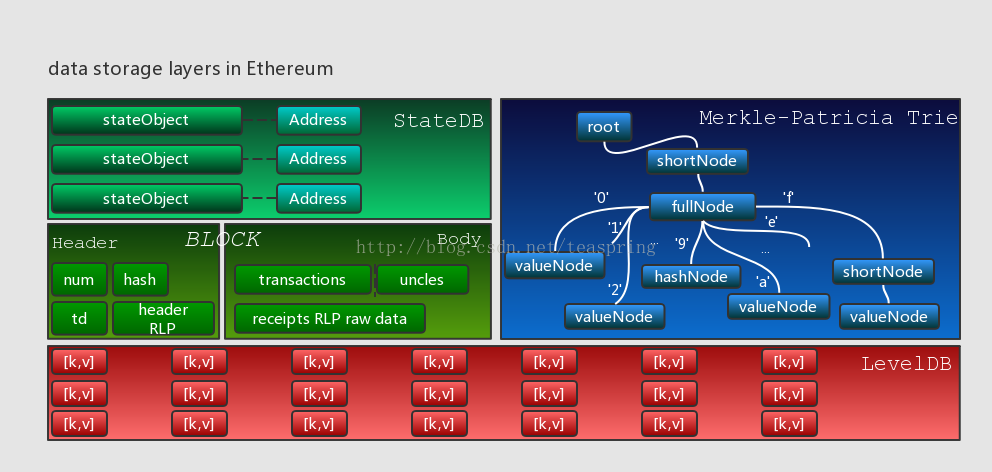
另一方面,上述数据单元如Block,stateObject,StateDB等,均大量使用Merkle-PatriciaTrie(MPT)数据结构以组织和管理[k,v]型数据。利用MPT高效的分段哈希验证机制和灵活的节点(Node)插入/载入设计,调用方均可快速且高效的实现对数据的插入、删除、更新、压缩和加密。以下各章节会对以上内容分别展开详细介绍。
1. Block和Header
Block(区块)是Ethereum的核心数据结构之一。所有账户的相关活动,以交易(Transaction)的格式存储,每个Block有一个交易对象的列表;每个交易的执行结果,由一个Receipt对象与其包含的一组Log对象记录;所有交易执行完后生成的Receipt列表,存储在Block中(经过压缩加密)。不同Block之间,通过前向指针ParentHash一个一个串联起来成为一个单向链表,BlockChain 结构体管理着这个链表。
Block结构体基本可分为Header和Body两个部分,其UML关系族如下图所示:
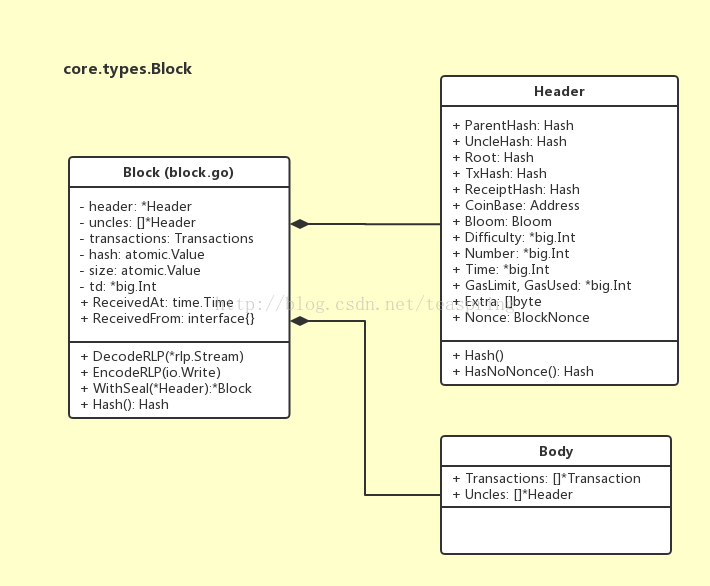
Header部分
Header是Block的核心,注意到它的成员变量全都是公共的,这使得它可以很方便的向调用者提供关于Block属性的操作。Header的成员变量全都很重要,值得细细理解:
- ParentHash:指向父区块(parentBlock)的指针。除了创世块(Genesis Block)外,每个区块有且只有一个父区块。
- Coinbase:挖掘出这个区块的作者地址。在每次执行交易时系统会给与一定补偿的Ether,这笔金额就是发给这个地址的。
- UncleHash:Block结构体的成员uncles的RLP哈希值。uncles是一个Header数组,它的存在,颇具匠心。
- Root:StateDB中的“state Trie”的根节点的RLP哈希值。Block中,每个账户以stateObject对象表示,账户以Address为唯一标示,其信息在相关交易(Transaction)的执行中被修改。所有账户对象可以逐个插入一个Merkle-PatricaTrie(MPT)结构里,形成“state Trie”。
- TxHash: Block中 “tx Trie”的根节点的RLP哈希值。Block的成员变量transactions中所有的tx对象,被逐个插入一个MPT结构,形成“tx Trie”。
- ReceiptHash:Block中的 "Receipt Trie”的根节点的RLP哈希值。Block的所有Transaction执行完后会生成一个Receipt数组,这个数组中的所有Receipt被逐个插入一个MPT结构中,形成"Receipt Trie"。
- Bloom:Bloom过滤器(Filter),用来快速判断一个参数Log对象是否存在于一组已知的Log集合中。
- Difficulty:区块的难度。Block的Difficulty由共识算法基于parentBlock的Time和Difficulty计算得出,它会应用在区块的‘挖掘’阶段。
- Number:区块的序号。Block的Number等于其父区块Number +1。
- Time:区块“应该”被创建的时间。由共识算法确定,一般来说,要么等于parentBlock.Time + 10s,要么等于当前系统时间。
- GasLimit:区块内所有Gas消耗的理论上限。该数值在区块创建时设置,与父区块有关。具体来说,根据父区块的GasUsed同GasLimit * 2/3的大小关系来计算得出。
- GasUsed:区块内所有Transaction执行时所实际消耗的Gas总和。
- Nonce:一个64bit的哈希数,它被应用在区块的"挖掘"阶段,并且在使用中会被修改。
Merkle-PatriciaTrie(MPT)是Ethereum用来存储区块数据的核心数据结构。最简单理解是一个倒置的树形结构,每个节点可能有若干个子节点,关于MPT在Ethereum中的实现细节在下文有专门介绍。
Root,TxHash和ReceiptHash,分别取自三个MPT类型对象:stateTrie, txTrie, 和receiptTrie的根节点哈希值。用一个32byte的哈希值,来代表一个有若干节点的树形结构(或若干元素的数组),这是为了加密。比如在Block的同步过程中,通过比对收到的TxHash,可以确认数组成员transactions是否同步完整。
三者当中,TxHash和ReceiptHash的生成稍微特殊一点,因为这两的数据来源是数组,而不像stateTrie原本就存在。如何将数组转化成MPT结构?考虑到MPT专门存储[k,v]类型数据,代码里利用了点小技巧:将数组中每个元素的索引作为k,该元素的RLP编码值作为v,组成一个[k,v]键值对作为一个节点,这样所有数组元素作为节点逐个插入一个初始化为空的MPT,形成MPT结构。
在stateTrie,txTrie,receiptTrie这三个MPT结构的产生时间上,receiptTrie 必须在Block的所有交易执行完成才能生成;txTrie 理论上只需tx数组transactions即可,不过依然被限制在所有交易执行完后才生成;最有趣的是stateTrie,由于它存储了所有账户的信息,比如余额,发起交易次数,虚拟机指令数组等等,所以随着每次交易的执行,stateTrie 其实一直在变化,这就使得Root值也在变化中。于是StateDB 定义了一个函数IntermediateRoot(),用来生成那一时刻的Root值:
这个函数的返回值,代表了所有账户信息的一个即时状态。
关于Header.Root的生成时间,在上篇帖子提到的交易执行过程中,交易执行的入口函数StateProcessor.Process()在返回前调用了Engine.Finalize()。正是这个Finalize(),在内部调用上述IntermediateRoot()函数并赋值给header.Root。所以Root值就是在该区块所有交易完成后,所有账户信息的即时状态。
Body结构体
Block的成员变量td 表示的是整个区块链表从源头创世块开始,到当前区块截止,累积的所有区块Difficulty之和,td 取名totalDifficulty。从概念上可知,某个区块与父区块的td之差,就等于该区块Header带有的Difficulty值。
Body可以理解为Block里的数组成员集合,它相对于Header需要更多的内存空间,所以在数据传输和验证时,往往与Header是分开进行的。
Uncles是Body非常特别的一个成员,从业务功能上说,它并不是Block结构体必须的,它的出现当然会占用整个Block计算哈希值时更长的时间,目的是为了抵消整个Ethereum网络中那些计算能力特别强大的节点会对区块的产生有过大的影响力,防止这些节点破坏“去中心化”这个根本宗旨。官方描述可见ethereum-wiki
Block的唯一标识符
同Ethereum世界里的其他对象类似,Block对象的唯一标识符,就是它的(RLP)哈希值。需要注意的是,Block的哈希值,等于其Header成员的(RLP)哈希值。
小技巧:Block的成员hash会缓存上一次Header计算出的哈希值,以避免不必要的计算。
Block的哈希值等于其Header的(RLP)哈希值,这就从根本上明确了Block(结构体)和Header表示的是同一个区块对象。考虑到这两种结构体所占内存空间的差异,这种设计可以带来很多便利。比如在数据传输时,完全可以先传输Header对象,验证通过后再传输Block对象,收到后还可以利用二者的成员哈希值做相互验证。
成员分散存储在底层数据库
Header和Block的主要成员变量,最终还是要存储在底层数据库中。Ethereum 选用的是LevelDB, 属于非关系型数据库,存储单元是[k,v]键值对。我们来看看具体的存储方式(core/database_util.go)
| key | value |
| 'h' + num + hash | header's RLP raw data |
| 'h' + num + hash + 't' | td |
| 'h' + num + 'n' | hash |
| 'H' + hash | num |
| 'b' + num + hash | body's RLP raw data |
| 'r' + num + hash | receipts RLP |
| 'l' + hash | tx/receipt lookup metadata |
这里的hash就是该Block(或Header)对象的RLP哈希值,在代码中也被称为canonical hash;num是Number的uint64类型,大端(big endian)整型数。可以发现,num 和 hash是key中出现最多的成分;同时num和hash还分别作为value被单独存储,而每当此时则另一方必组成key。这些信息都在强烈的暗示,num(Number)和hash是Block最为重要的两个属性:num用来确定Block在整个区块链中所处的位置,hash用来辨识惟一的Block/Header对象。
通过以上的设计,Block结构体的所有重要成员,都被存储进了底层数据库。当所有Block对象的信息都已经写进数据库后,我们就可以使用BlockChain结构体来处理整个块链。
2. HeaderChain和BlockChain
BlockChain结构体被用来管理整个区块单向链表,在一个Ethereum客户端软件(比如钱包)中,只会有一个BlockChain对象存在。同Block/Header的关系类似,BlockChain还有一个成员变量类型是HeaderChain, 用来管理所有Header组成的单向链表。当然,HeaderChain在全局范围内也仅有一个对象,并被BlockChain持有(准确说是HeaderChain只会被BlockChain和LightChain持有,LightChain类似于BlockChain,但默认只处理Headers,不过依然可以下载bodies和receipts)。它们的UML关系图如下所示:
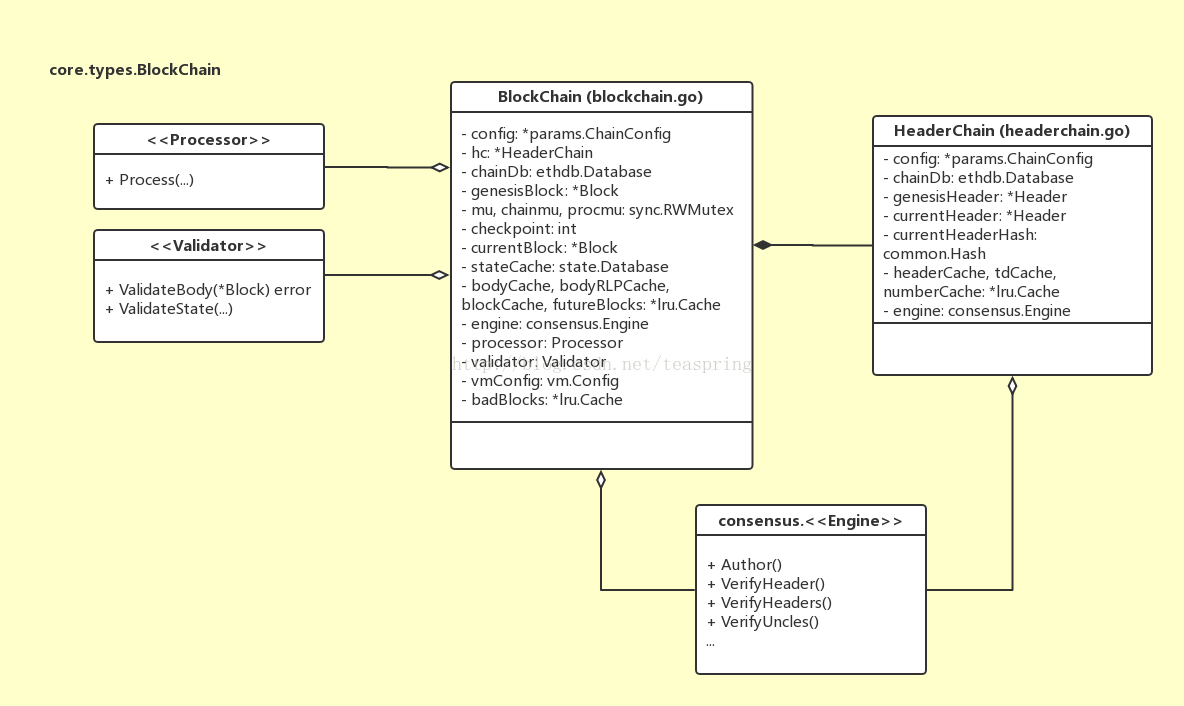
在结构体的设计上,BlockChain 同HeadeChain有诸多类似之处。比如二者都有相同的ChainConfig对象,有相同的Database接口行为变量以提供[k,v]数据的读取和写入;BlockChain 有成员genesisBlock和currentBlock,分别对应创世块和当前块,而HeaderChain则有genesisHeader和currentHeader;BlockChain 有bodyCache,blockCache 等成员用以缓存高频调用对象,而HeaderChain则有headerCache, tdCache, numberCache等缓存成员变量。除此之外,BlockChain 相对于HeaderChain主要增多了Processor和Validator两个接口行为变量,前者用以执行所有交易对象,后者可以验证诸如Body等数据成员的有效性。
Engine是共识算法定义的行为接口。共识算法是整个数字货币体系最重要的概念之一,它在理论上的完整性,有力的支撑了“去中心化”这个伟大设想的实现。落实在代码层面,consensus.Engine就是Ethereum系统里共识算法的一个主要行为接口,它基于符合某种共识算法规范的算法库,提供包括VerifyHeaders(),VerifyUncles()等一系列涉及到数据合法性的关键函数。不仅仅BlockChain和HeaderChain结构体,在Ethereum系统里,所有跟验证区块对象相关的操作都会调用Engine行为接口来完成。目前存在两种共识算法规范,一种是基于运算能力(proof-of-work),叫Ethash;另一种基于某个投票机制(proof-of-authority),叫Clique。具体内容在之后的文章中会有更多展开。
区块链的操作
从逻辑上讲,既然BlockChain和HeaderChain都管理着一个类似单向链表的结构,那么它们提供的操作方法肯定包括插入,删除,和查找。
查找比较简单,以BlockChain为例,它有一个成员currentBlock,指向当前最新的Block,而HeaderChain也有一个类似的成员currentHeader。除此之外,底层数据库里还分别存有当前最新Block和Header的canonical hash:
| key | value |
| "LastHeader" | hash |
| "LastBlock" | hash |
| "LastFast" | hash |
以BlockChain为例,通过"LastBlock"为key从数据库中获取最新的Block之后,用num逐一遍历,得到目标Block的num后,用'h'+num+'n'作key,就可以从数据库中获取目标canonical hash。
插入和删除。区块链跟普通单向链表有一点非常明显的不同,在于Header的前向指针ParentHash是不能修改的,即当前区块的父区块是不能修改的。所以在插入的实现中,当决定写入一个新的Header进底层数据库时,从这个Header开始回溯,要保证它的parent,以及parent的parent等等,都已经写入数据库了。只有这样,才能确保从创世块(num为0)起始,直到当前新写入的区块,整个链式结构是完整的,没有中断或分叉。删除的情形也类似,要从num最大的区块开始,逐步回溯。在BlockChain的操作里,删除一般是伴随着插入出现的,即当需要插入新区块时,才可能有旧的区块需要被删除,这种情形在代码里被称为reorg。
3. 精巧的Merkle-PatriciaTrie
Ethereum 使用的Merkle-PatriciaTrie(MPT)结构,源自于Trie结构,又分别继承了PatriciaTrie和MerkleTree的优点,并基于内部数据的特性,设计了全新的节点体系和插入/载入机制。
Trie,又称为字典树或者前缀树(prefix tree),属于查找树的一种。它与平衡二叉树的主要不同点包括:每个节点数据所携带的key不会存储在Trie的节点中,而是通过该节点在整个树形结构里位置来体现;同一个父节点的子节点,共享该父节点的key作为它们各自key的前缀,因此根节点key为空;待存储的数据只存于叶子节点中,非叶子节点帮助形成叶子节点key的前缀。下图来自wiki-Trie,展示了一个简单的Trie结构。
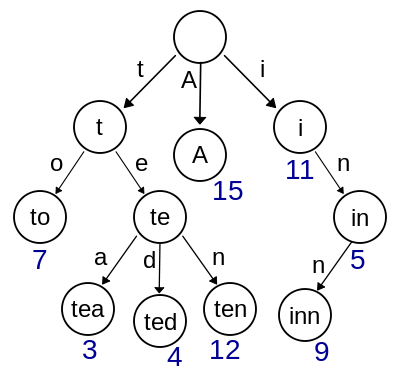
PatriciaTrie,又被称为RadixTree或紧凑前缀树(compact prefix tree),是一种空间使用率经过优化的Trie。与Trie不同的是,PatriciaTrie里如果存在一个父节点只有一个子节点,那么这个父节点将与其子节点合并。这样可以缩短Trie中不必要的深度,大大加快搜索节点速度。
MerkleTree,也叫哈希树(hash tree),是密码学的一个概念,注意理论上它不一定是Trie。在哈希树中,叶子节点的标签是它所关联数据块的哈希值,而非叶子节点的标签是它的所有子节点的标签拼接而成字符串的哈希值。哈希树的优势在于,它能够对大量的数据内容迅速作出高效且安全的验证。假设一个hash tree中有n个叶子节点,如果想要验证其中一个叶子节点是否正确-即该节点数据属于源数据集合并且数据本身完整,所需哈希计算的时间复杂度是是O(log(n)),相比之下hash list大约需要时间复杂度O(n)的哈希计算,hash tree的表现无疑是优秀的。
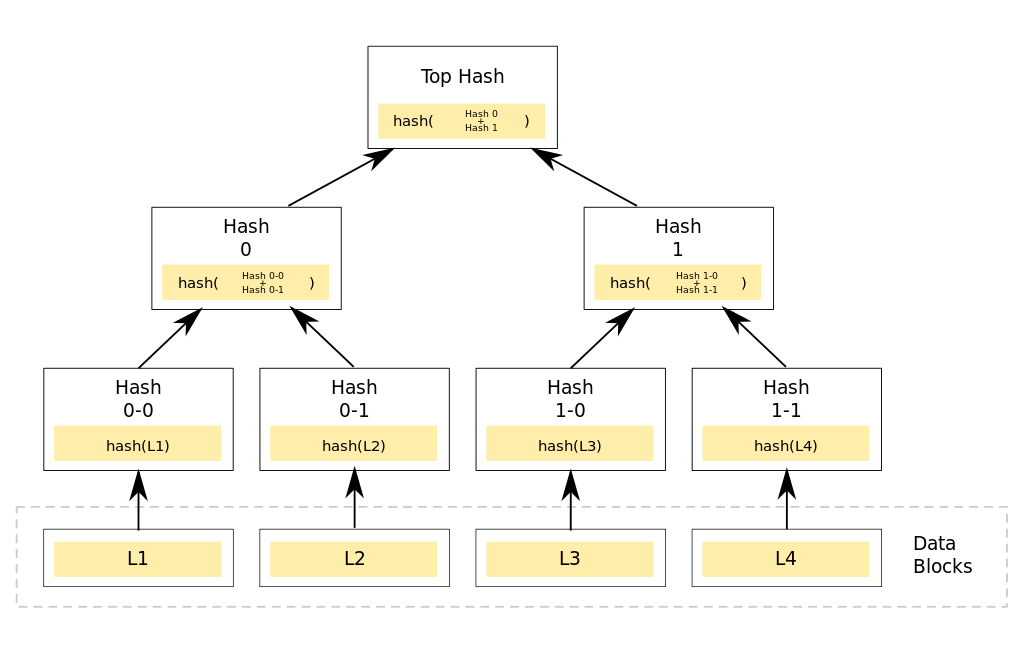
上图来自wiki-MerkleTree,展示了一个简单的二叉哈希树。四个有效数据块L1-L4,分别被关联到一个叶子节点上。Hash0-0和Hash0-1分别等于数据块L1和L2的哈希值,而Hash0则等于Hash0-0和Hash0-1二者拼接成的新字符串的哈希值,依次类推,根节点的标签topHash等于Hash0和Hash1二者拼接成的新字符串的哈希值。
哈希树最主要的应用场景是p2p网络中的数据传输。因为p2p网络中可能存在未知数目的不可信数据源,所以确保下载到的数据正确可信并且无损坏无改动,就显得非常重要。哈希树可用来解决这个问题:每个待下载文件按照某种方式分割成若干小块后,组成类似上图的哈希树。首先从一个绝对可信的数据源获取该文件对应哈希树的根节点哈希值(top hash),有了这个可靠的top hash后,就可以开始从整个p2p网络下载文件。不同的数据部分可以从不同的源下载,由于哈希树中任意的分支树都可以单独验证哈希值,所以一旦发现任何数据部分无法通过验证,都可以切换到其他数据源进行下载那部分数据。最终,完整下载文件所对应哈希树的top hash值,一定要与我们的可靠top hash相等。
Merkle-Patricia Trie(MPT)的实现
MPT是Ethereum自定义的Trie型数据结构。在代码中,trie.Trie结构体用来管理一个MPT结构,其中每个节点都是行为接口Node的实现类。下图是Trie结构体和node接口族的UML关系图:
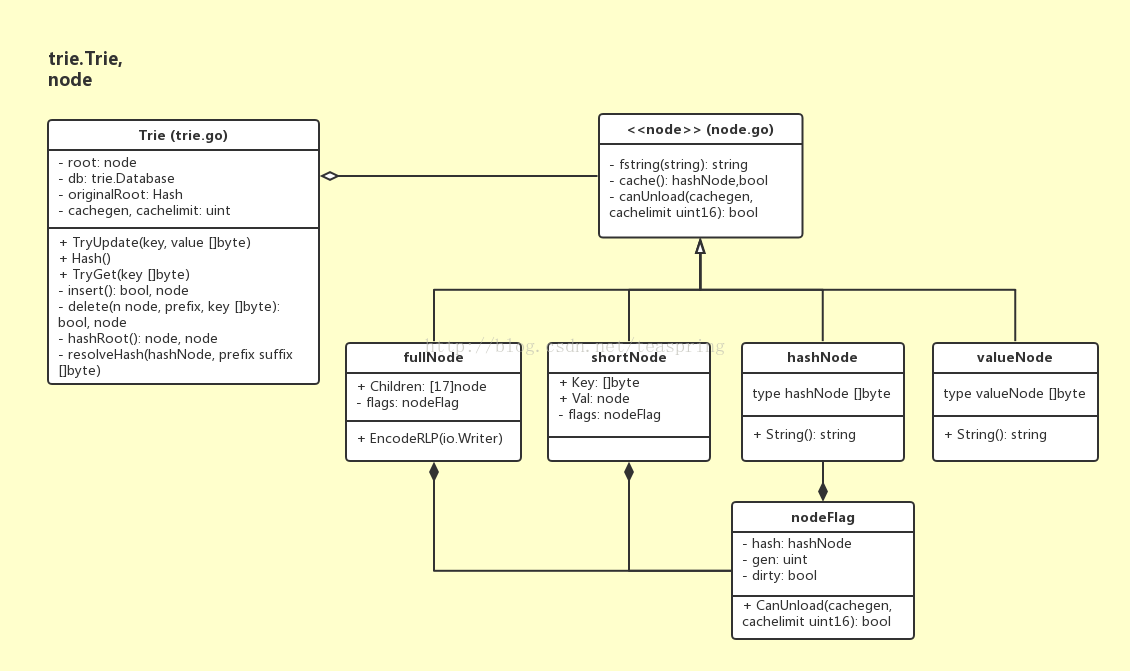
在Trie结构体中,成员root始终作为整个MPT的根节点;originalRoot的作用是在创建Trie对象时承接入参hashNode;cacheGen是cache次数的计数器,每次Trie的变动提交后(写入的对象可由外部参数传入),cacheGen自增1。Trie结构体提供包括对节点的插入、删除、更新,所有节点改动的提交(写入到传入参数),以及返回整个MPT的哈希值。
node接口族担当整个MPT中的各种节点,node接口分四种实现: fullNode,shortNode,valueNode,hashNode,其中只有fullNode和shortNode可以带有子节点。
fullNode 是一个可以携带多个子节点的父(枝)节点。它有一个容量为17的node数组成员变量Children,数组中前16个空位分别对应16进制(hex)下的0-9a-f,这样对于每个子节点,根据其key值16进制形式下的第一位的值,就可挂载到Children数组的某个位置,fullNode本身不再需要额外key变量;Children数组的第17位,留给该fullNode的数据部分。fullNode明显继承了原生trie的特点,而每个父节点最多拥有16个分支也包含了基于总体效率的考量。
shortNode 是一个仅有一个子节点的父(枝)节点。它的成员变量Val指向一个子节点,而成员Key是一个任意长度的字符串(字节数组[]byte)。显然shortNode的设计体现了PatriciaTrie的特点,通过合并只有一个子节点的父节点和其子节点来缩短trie的深度,结果就是有些节点会有长度更长的key。
valueNode 充当MPT的叶子节点。它其实是字节数组[]byte的一个别名,不带子节点。在使用中,valueNode就是所携带数据部分的RLP哈希值,长度32byte,数据的RLP编码值作为valueNode的匹配项存储在数据库里。
这三种类型覆盖了一个普通Trie(也许是PatriciaTrie)的所有节点需求。任何一个[k,v]类型数据被插入一个MPT时,会以k字符串为路径沿着root向下延伸,在此次插入结束时首先成为一个valueNode,k会以自顶点root起到到该节点止的key path形式存在。但之后随着其他节点的不断插入和删除,根据MPT结构的要求,原有节点可能会变化成其他node实现类型,同时MPT中也会不断裂变或者合并出新的(父)节点。比如:
- 假设一个shortNode S已经有一个子节点A,现在要新插入一个子节点B,那么会有两种可能,要么新节点B沿着A的路径继续向下,这样S的子节点会被更新;要么S的Key分裂成两段,前一段分配给S作为新的Key,同时裂变出一个新的fullNode作为S的子节点,以同时容纳B,以及需要更新的A。
- 如果一个fullNode原本只有两个子节点,现在要删除其中一个子节点,那么这个fullNode就会退化为shortNode,同时保留的子节点如果是shortNode,还可以跟它再合并。
- 如果一个shortNode的子节点是叶子节点同时又被删除了,那么这个shortNode就会退化成一个valueNode,成为一个叶子节点。
诸如此类的情形还有很多,提前设想过这些案例,才能正确实现MPT的插入/删除/查找等操作。当然,所有查找树(search tree)结构的操作,免不了用到递归。
特殊的那个 - hashNode
hashNode 跟valueNode一样,也是字符数组[]byte的一个别名,同样存放32byte的哈希值,也没有子节点。不同的是,hashNode是fullNode或者shortNode对象的RLP哈希值,所以它跟valueNode在使用上有着莫大的不同。
在MPT中,hashNode几乎不会单独存在(有时遍历遇到一个hashNode往往因为原本的node被折叠了),而是以nodeFlag结构体的成员(nodeFlag.hash)的形式,被fullNode和shortNode间接持有。一旦fullNode或shortNode的成员变量(包括子结构)发生任何变化,它们的hashNode就一定需要更新。所以在trie.Trie结构体的insert(),delete()等函数实现中,可以看到除了新创建的fullNode、shortNode,那些子结构有所改变的fullNode、shortNode的nodeFlag成员也会被重设,hashNode会被清空。在下次trie.Hash()调用时,整个MPT自底向上的遍历过程中,所有清空的hashNode会被重新赋值。这样trie.Hash()结束后,我们可以得到一个根节点root的hashNode,它就是此时此刻这个MPT结构的哈希值。上文中提到的,Block的成员变量Root、TxHash、ReceiptHash的生成,正是源出于此。
明显的,hashNode体现了MerkleTree的特点:每个父节点的哈希值来源于所有子节点哈希值的组合,一个顶点的哈希值能够代表一整个树形结构。valueNode加上之前的fullNode,shortNode,valueNode,构成了一个完整的Merkle-PatriciaTrie结构,很好的融合了各种原型结构的优点,又根据Ethereum系统的实际情况,作了实际的优化和平衡。MPT这个数据结构在设计中的种种细节,的确值得好好品味。
函数实现
代码方面,创建新nodeFlag对象的函数叫newFlags()。在nodeFlag初始化过程中,bool成员dirty置为true,表明了所代表的父节点有改动需要提交,同时hashNode成员hash,直接设空。
每个hashNode被赋值的过程,就是它所代表的fullNode或shortNode被折叠(collapse)的过程。基于效率和数据安全考虑,trie.Trie仅提供整个MPT结构的折叠操作Hash()函数,它默认从顶点root开始遍历。
hashRoot()函数内部调用Hasher结构体进行折叠操作:
折叠node的入口是hasher.hash(),在执行中,hash()和hashChiildren()相互调用以遍历整个MPT结构,store()对节点作RLP哈希计算。折叠node的基本逻辑是:如果node没有子节点,那么直接返回;如果这个node带有子节点,那么首先将子节点折叠成hashNode。当这个node的子节点全都变成哈希值hashNode之后,再对这个node作RLP+哈希计算,得到它的哈希值,亦即hashNode。
注意到hash()和hashChildren()返回两个node类型对象,第一个@hash是入参n经过折叠的hashNode哈希值,第二个@cached是没有经过折叠的n,并且n的hashNode还被赋值了。
由于Hasher.hash()有一个数据库接口类型的参数,这样在折叠MPT过程中,如果db不为空,就把每次计算hashNode时的哈希值和它对应的节点RLP编码值一起存进数据库里,这也正是Commit()的逻辑。
回看一下Trie.Hash(),它在调用hashRoot()时,传入的是空值db。只有显式调用Commit()或者CommitTo()才可以提交数据,所以Hash()多次调用也是安全的。
在MPT的查找,插入,删除中,如果遍历过程中遇到一个hashNode,首先需要从数据库里以这个哈希值为k,读取出相匹配的v,然后再将v解码恢复成fullNode或shortNode。在代码中这个过程叫resolve。
这样,涉及到hashNode的所有操作就基本完整了。
MPT中对key的编码
当[k,v]数据插入MPT时,它们的k(key)都必须经过编码。这时对key的编码,要保证原本是[]byte类型的key能够以16进制形式按位进入fullNode.Children[],因为Children[]数组最多只能容纳16个子节点。相应的,Ethereum代码中在这里定义了一种编码方式叫Hex,将1byte的字符大小限制在4bit(16进制)以内。
先来看Hex编码的实现,这里将原本[]byte形式称之为keybytes,Hex编码的基本逻辑如下图:
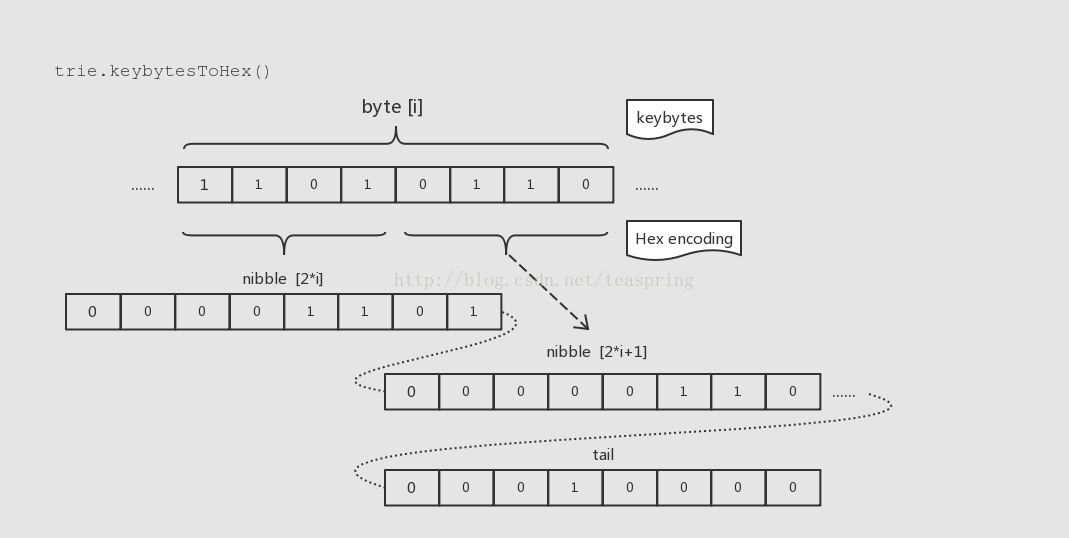
很简单,就是将keybytes中的1byte信息,将高4bit和低4bit分别放到两个byte里,最后在尾部加1byte标记当前属于Hex格式。这样新产生的key虽然形式还是[]byte,但是每个byte大小已经被限制在4bit以内,代码中把这种新数据的每一位称为nibble。这样经过编码之后,带有[]nibble格式的key的数据就可以顺利的进入fullNode.Children[]数组了。
Hex编码虽然解决了key是keybytes形式的数据插入MPT的问题,但代价也很大,就是数据冗余。典型的如shortNode,目前Hex格式下的Key,长度会变成是原来keybytes格式下的两倍。这一点对于节点的哈希计算,比如计算hashNode,影响很大。所以Ethereum又定义了另一种编码格式叫Compact,用来对Hex格式进行优化。
Compact编码又叫hex prefix编码,它的主要意图是将Hex格式的字符串恢复到keybytes的格式,同时要加入当前Compact格式的标记位,还要考虑在奇偶不同长度Hex格式字符串下,避免引入多余的byte。
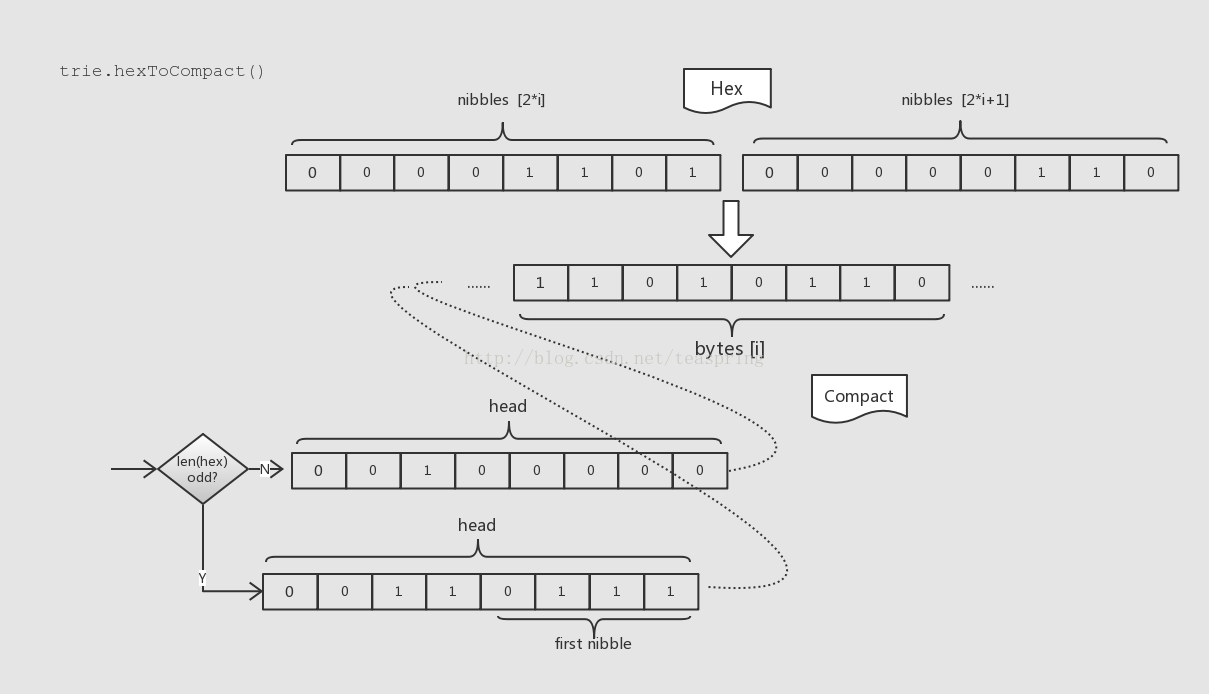
如上图所示,Compact编码首先将Hex尾部标记byte去掉,然后将原本每2 nibble的数据合并到1byte;增添1byte在输出数据头部以放置Compact格式标记位;如果输入Hex格式字符串有效长度为奇数,还可以将Hex字符串的第一个nibble放置在标记位byte里的低4bit。
Key编码的设计细节,也体现出MPT整个数据结构设计的思路很完整。
4. 数据库体系
到目前为止,Ethereum系统中区块数据的呈现,组织管理已经介绍了不少,我们可以开始探讨存储部分了。先来看看数据存储部分的UML关系图。
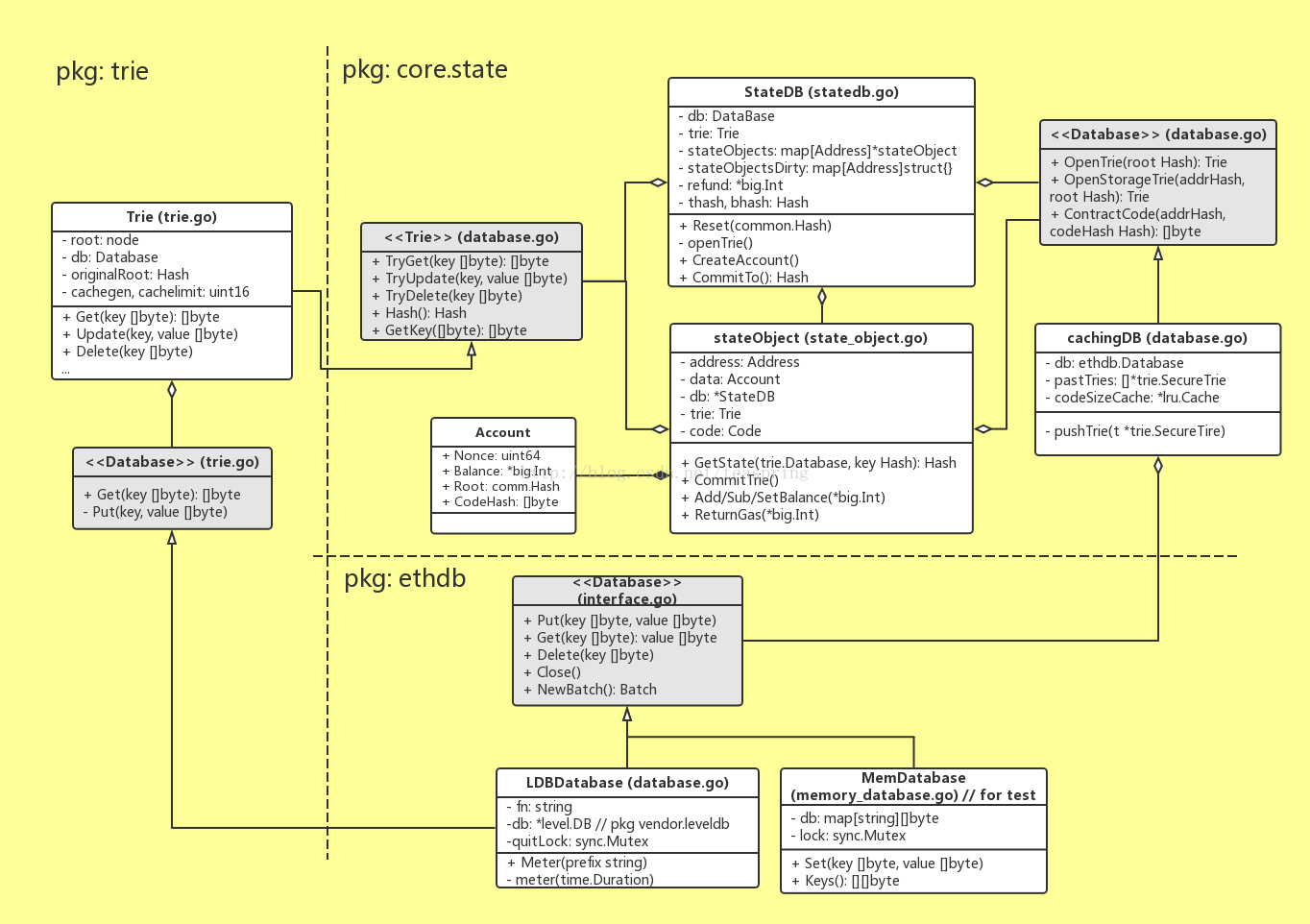
属于Ethereum代码范围内的最底层数据库是ethdb.LDBDatabase,它通过持有一个levelDB的对象,最终为Ethereum世界里所有需要存储/读取[k,b]的需求提供服务。
留意到图中多次出现一种类似的设计模式,比如trie.Trie持有一个本地接口trie.<<Database>>,而后者的具体实现是ethdb.LDBDatabase。这种设计模式其实是golang的语法带来的。在golang中,一个结构体(类)要实现另一个接口的所有方法,不必在结构体声明时显式继承那个接口,只要完全实现那些方法。这样,当一个结构体想调用另一个包路径下结构体的多个方法时,可以声明一个本地接口,带有几个同想要调用方法完全一样的方法,就可以了,这种方式的优点是不同包之间的代码更充分的解耦合。所以在上图中,这些辅助性的本地接口全都被标为灰色,只需要关注实际调用的实现类就好了。
系统设计中,在底层数据库模块和业务模型之间,往往需要设置本地存储模块,它面向业务模型,可以根据业务需求灵活的设计各种存储格式和单元,同时又连接底层数据库,如果底层数据库(或者第三方API)有变动,可以大大减少对业务模块的影响。在Ethereum世界里,StateDB就担任这个角色,它通过大量的stateObject对象集合,管理所有“账户”信息。
面向业务的存储模块 - StateDB
StateDB有一个trie.Trie类型成员trie,它又被称为storage trie或stte trie,这个MPT结构中存储的都是stateObject对象,每个stateObject对象以其地址(20 bytes)作为插入节点的Key;每次在一个区块的交易开始执行前,trie由一个哈希值(hashNode)恢复出来。另外还有一个map结构,也是存放stateObject,每个stateObject的地址作为map的key。那么问题来了,这些数据结构之间是怎样的关系呢?
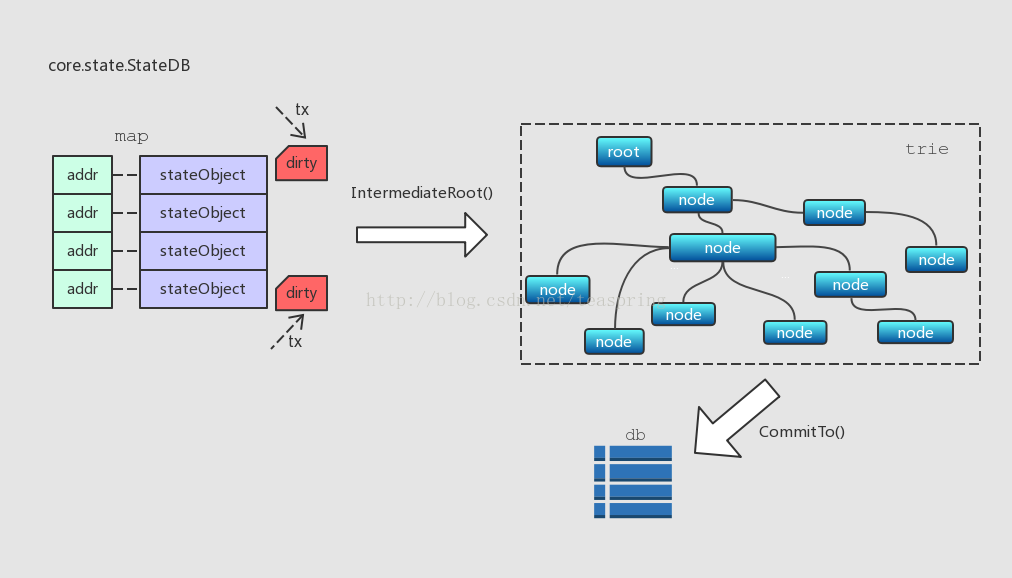
如上图所示,每当一个stateObject有改动,亦即“账户”信息有变动时,这个stateObject对象会更新,并且这个stateObject会标为dirty,此时所有的数据改动还仅仅存储在map里。当IntermediateRoot()调用时,所有标为dirty的stateObject才会被一起写入trie。而整个trie中的内容只有在CommitTo()调用时被一起提交到底层数据库。可见,这个map被用作本地的一级缓存,trie是二级缓存,底层数据库是第三级,各级数据结构的界限非常清晰,这样逐级缓存数据,每一级数据向上一级提交的时机也根据业务需求做了合理的选择。
StateDB中账户状态的版本管理
StateDB还可以管理账户状态的版本。这个功能用到了几个结构体:journal,revision,先来看看UML关系图:
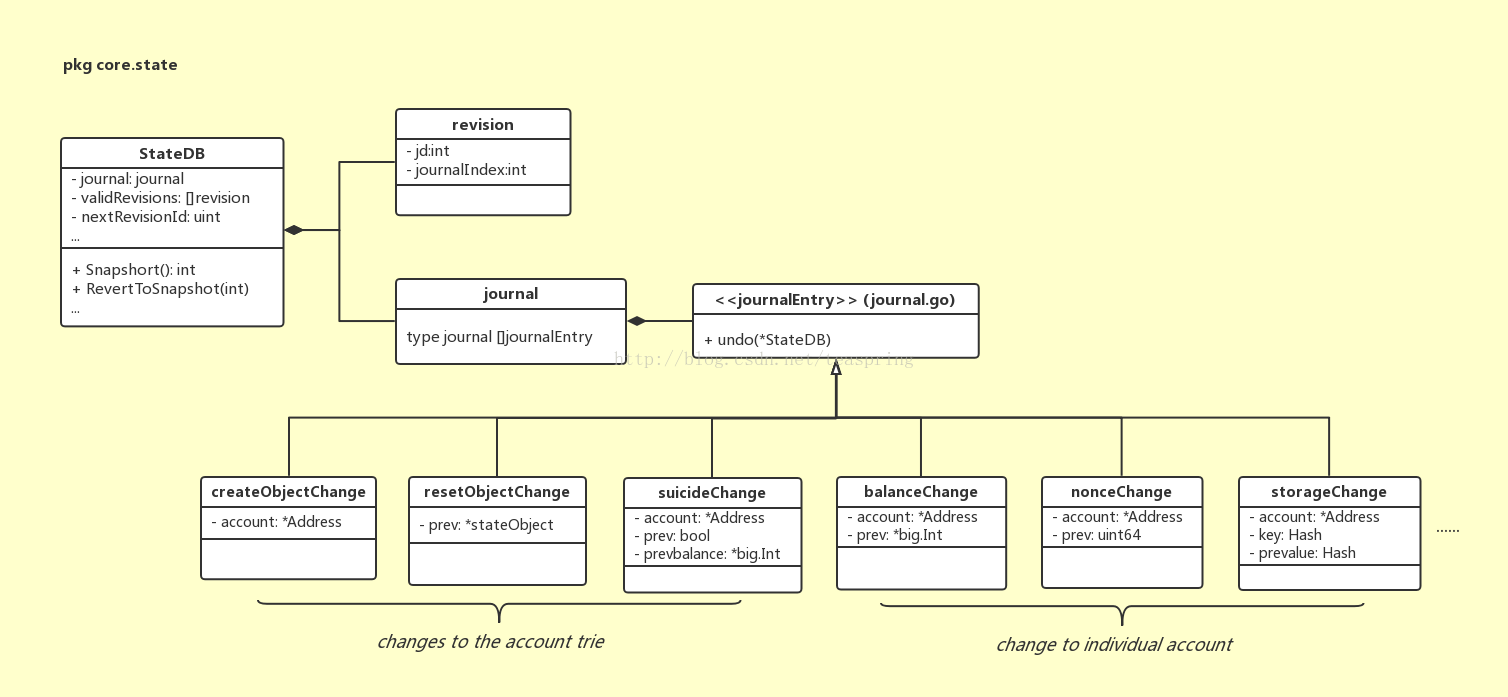
其中journal对象是journalEntry的散列,长度不固定,可任意添加元素。接口journalEntry存在若干种实现体,描述了从单个账户操作(账户余额,发起合约次数等),到account trie变化(创建新账户对象,账户消亡)等各种最小事件。revision结构体,用来描述一个‘版本’,它的两个整型成员jd和journalIndex,都是基于journal散列进行操作的。

上图简述了StateDB中账户状态的版本是如何管理的。首先journal散列会随着系统运行不断的增长,记录所有发生过的单位事件;当某个时刻需要产生一个账户状态版本时,代码中相应的是Snapshop()调用,会产生一个新revision对象,记录下当前journal散列的长度,和一个自增1的版本号。
基于以上的设计,当发生回退要求时,只要根据相应的revision中的journalIndex,在journal散列上,根据所记录的所有journalEntry,即可使所有账户回退到那个状态。
Ethereum里的账户 - stateObject
每个stateObject对象管理着Ethereum世界里的一个“账户”。stateObject有一个成员变量data,类型是Accunt结构体,里面存有账户Ether余额,合约发起次数,最新发起合约指令集的哈希值,以及一个MPT结构的顶点哈希值。
stateObject内部也有一个Trie类型的成员trie,被称为storage trie,它里面存放的是一种被称为State的数据。State跟每个账户相关,格式是[Hash, Hash]键值对。有意思的是,stateObject内部也有类似StateDB一样的二级数据缓存机制,用来缓存和更新这些State。
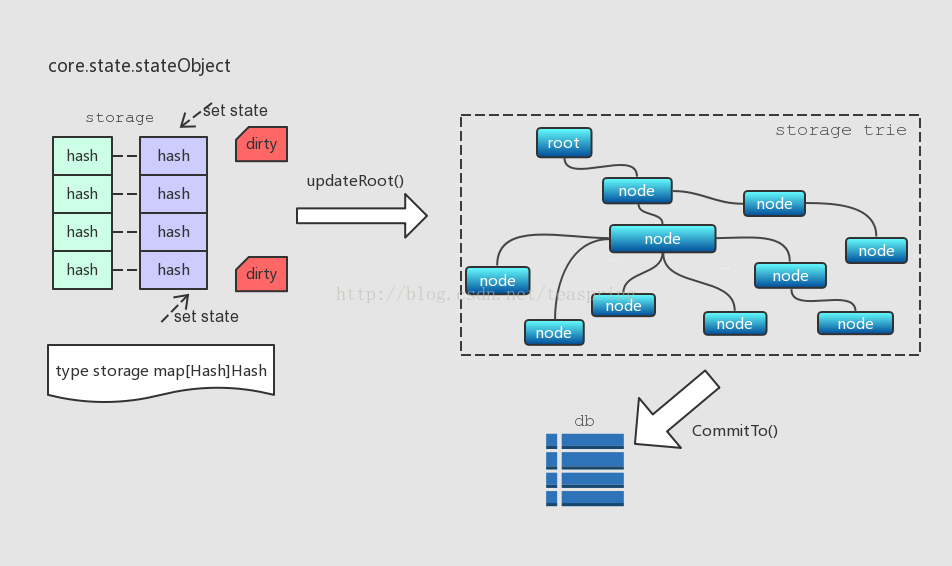
stateObject定义了一种类型名为storage的map结构,用来存放[]Hash,Hash]类型的数据对,也就是State数据。当SetState()调用发生时,storage内部State数据被更新,相应标示为"dirty"。之后,待有需要时(比如updateRoot()调用),那些标为"dirty"的State数据被一起写入storage trie,而storage trie中的所有内容在CommitTo()调用时再一起提交到底层数据库。
State数据略显神秘,目前笔者尚未完全理解它的含义,在代码里,仅仅查到某些合约指令中会调用SetState(),来更新某个stateObject中的State数据。
小结
任何一个系统中,数据部分的占用空间,运行效率当然会影响到整体性能。如何简洁完整的呈现数据,并涵盖业务模型下的大大小小各种需求;如何高效的管理数据,使得插入、删除、查找数据更快速;如何在业务模块和底层数据库之间安排面向业务的、接口友好的本地存储模块,使得内存占用更紧凑,提交和回退数据更加安全等等,都是值得全面思考的。从本文中,可以看到整个Ethereum系统的架构设计、代码实现上,对于以上各个话题都进行了诸多考量,值得同业者学习参考。
- Block结构体主要分为Header和Body,Header相对轻量,涵盖了Block的所有属性,包括特征标示,前向指针,和内部数据集的验证哈希值等;Body相对重量,持有内部数据集。每个Block的Header部分,Body部分,以及一些特征属性,都以[k,v]形式单独存储在底层数据库中。
- BlockChain管理Block组成的一个单向链表,HeaderChain管理Header组成的单向链表,并且BlockChain持有HeaderChain。在做插入/删除/查找时,要注意回溯,以及数据库中相应的增删。
- Merkle-PatriciaTrie(MPT)数据结构用来组织管理[k,v]型数据,它设计了灵活多变的节点体系和编码格式,既融合了多种原型结构的优点,又兼顾了业务需求和运行效率。
- StateDB作为本地存储模块,它面向业务模型,又连接底层数据库,内部利用两极缓存机制来存储和更新所有代表“账户”的stateObject对象。
- stateObject除了管理着账户余额等信息之外,也用了类似的两级缓存机制来存储和更新所有的State数据。















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









