







Postgresql是一个基于多版本并发控制实现的数据库.
事务隔离级别
标准的事务隔离级别包括:
1. 读未提交
2. 读已提交
3. 可重复读
4. 序列化
在正式的postgresql 并不包括读未提交这个隔离级别,因为出于多版本并发控制的架构考虑,默认的事务级别是“读已提交”。
常见的“错误”的数据库现象:
• 脏读 – 一个事务读取到了另外一个事务还没有提交的数据。
• 不可重复读—一个事务试图重新读它前面读取的数据,发现数据已经被另外一个事务修改。
• 幻影读—一个事务,重新查询一个满足一定条件的记录集,发现返回的结果集已经被另外一个最近提交的事务修改。
Postgresql 查看当前的事务级别:
select current_setting(‘transaction_isolation’);
current_setting
read committed
开始一个新的事务:
–values should be SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED
BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ;
– display “repeatable read” select
current_setting(‘transaction_isolation’);commit;
针对每个事务隔离级别的解释
读已提交:
只能看到当前查询开始时间点已经提交了的事务,无法看到在查询期间其他事务未提交的数据或者已提交的更改,但是可以看到当前事务前面造成的修改,即使它还没有提交.
但是官方网站上又说啦:
Also note that two successive SELECT commands can see different data, even though they are within a single transaction, if other transactions commit changes after the first SELECT starts and before the second SELECT starts.
意思是2个select会看到别的事务提交的事务 这样是对的吗??? 不是说不可以看到其他事务提交的更改吗?
原来是自己理解错了,select看的数据是针对每个查询开始的时间点计算 而不是事务开始的时间点:
a SELECT query (without a FOR UPDATE/SHARE clause) sees only data committed before the query began; it never sees either uncommitted data or changes committed during query execution by concurrent transactions
做出测试:
create table testtable(id int, num int);
事务1:
--1
BEGIN TRANSACTION ISOLATION LEVEL READ COMMITTED;
--2 no data
select * from testtable;
--6 nodata trans2 insert but not commit.
select * from testtable;
--8 requery after trans2 committed
-- got one record
select * from testtable;
commit;事务2:
--3
BEGIN TRANSACTION ISOLATION LEVEL READ COMMITTED;
--5 insert one record
insert into testtable values(1,1);
--7 and commit
commit;所以说:总结下来就是 查询只能看到当前查询开始时的一个数据库快照.,具体的就是能看到查询开始时,其他事务已经提交了的更改,未提交的看不到.
可重复读
这个应该就是前面理解错了的那个了,
意思是:它只能看到事务开始前( 注意不是查询开始前, 一个事务可能有多个查询.),已经提交了的数据,是无法看到整个事务过程中,其他事务所做的任何修改.即便他们已经提交了. 注意这个与读已提交不同,读已提交可以看到其他事务已提交的数据.
继续举例:
事务1:
--1
BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ;
--2 no data
select * from testtable;
--7 still no data.
select * from testtable;
commit;事务2:
--4
BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ;
--5
insert into testtable values(1,1);
--6
commit;正如官方文档所说:
This level is different from Read Committed in that a query in a repeatable read transaction sees a snapshot as of the start of the transaction, not as of the start of the current query within the transaction.
如果另外一个事务改了数据会怎么样了??
例子:
假定testtable里面已经有2条数据(1,1), (2,2) 了.
然后分别考察下面几种情况,事务1 事务2 分别对不同的行更新,以及对同一行更行时的情况:
1.事务1修改了行(1,1),提交了,然后事务2也修改了(1,1) 并提交
事务1:
--1. trans1
BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ;
--3. got (1,1) (2,2)
select * from testtable;
--4 update
update testtable set num=2 where id=1;
--5 commit
commit;
事务2:
--2. trans2
BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ;
--6 update
update testtable set num=2 where id=3;事务2在更新时失败:
错误: 由于同步更新而无法串行访问
SQL state: 40001
可以试下将步骤5,步骤6对换,那么你会发现第二个事务update会一直等 直到第一个事务提交.
2.修改不同的行
没有问题.
单位是行.
UPDATE, DELETE, SELECT FOR UPDATE, and SELECT FOR SHARE commands behave the same as SELECT in terms of searching for target rows: they will only find target rows that were committed as of the transaction start time. However, such a target row might have already been updated (or deleted or locked) by another concurrent transaction by the time it is found. In this case, the repeatable read transaction will wait for the first updating transaction to commit or roll back (if it is still in progress). If the first updater rolls back, then its effects are negated and the repeatable read transaction can proceed with updating the originally found row. But if the first updater commits (and actually updated or deleted the row, not just locked it) then the repeatable read transaction will be rolled back with the message
ERROR: could not serialize access due to concurrent update because a
repeatable read transaction cannot modify or lock rows changed by
other transactions after the repeatable read transaction began.
该隔离级别无法规避 幻象读取.–针对带条件的结果集的查询.
还是前面的那个假定数据库记录为(1,1), (2,2)
按照网上说的测试select from where 发现并没有出现数量或者记录不一致的情况,这是为啥?
原来这个在PG中并不会出现,参考PG 9.2 和 最新的9.5的不同:
9.2:
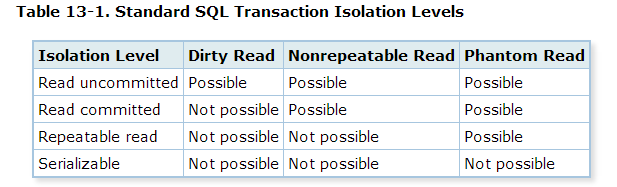
9.5:
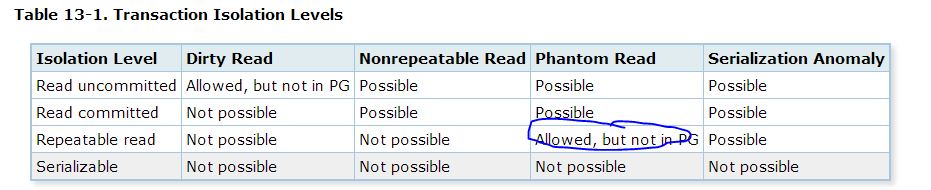
在mysql中测试下:
依然没有出现:
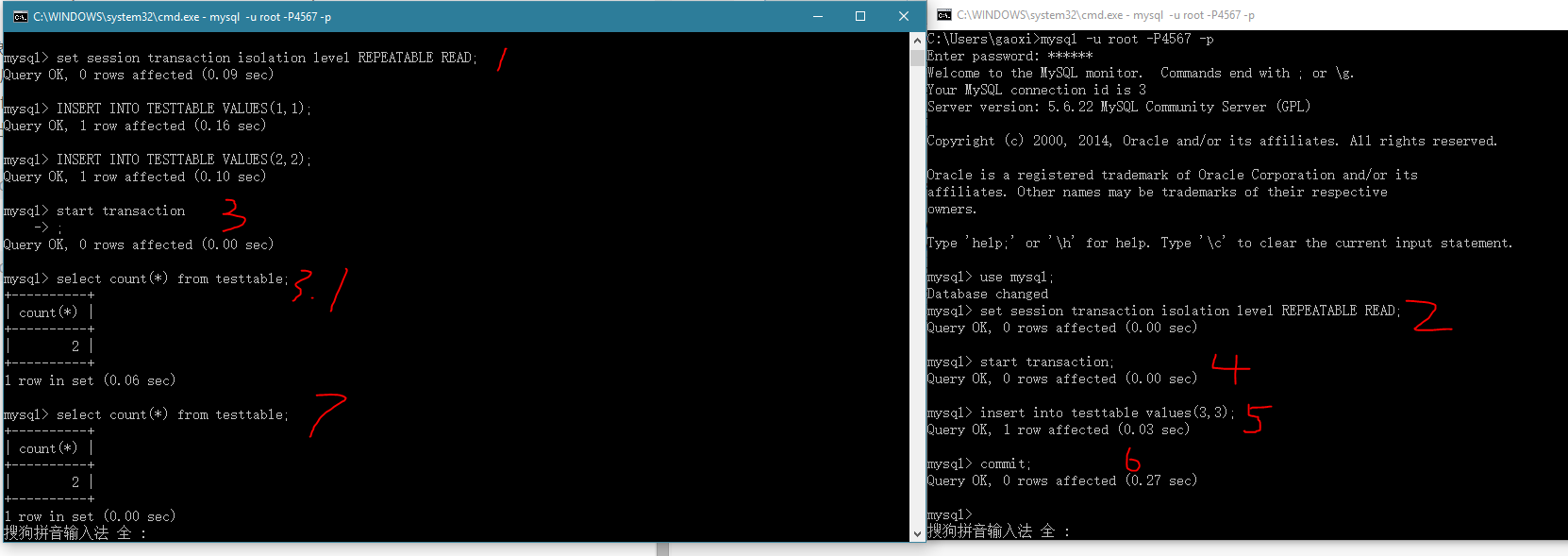
修改我们的表结构后出现,在testtable的id字段加主键约束.
[1]先插入3条数据,
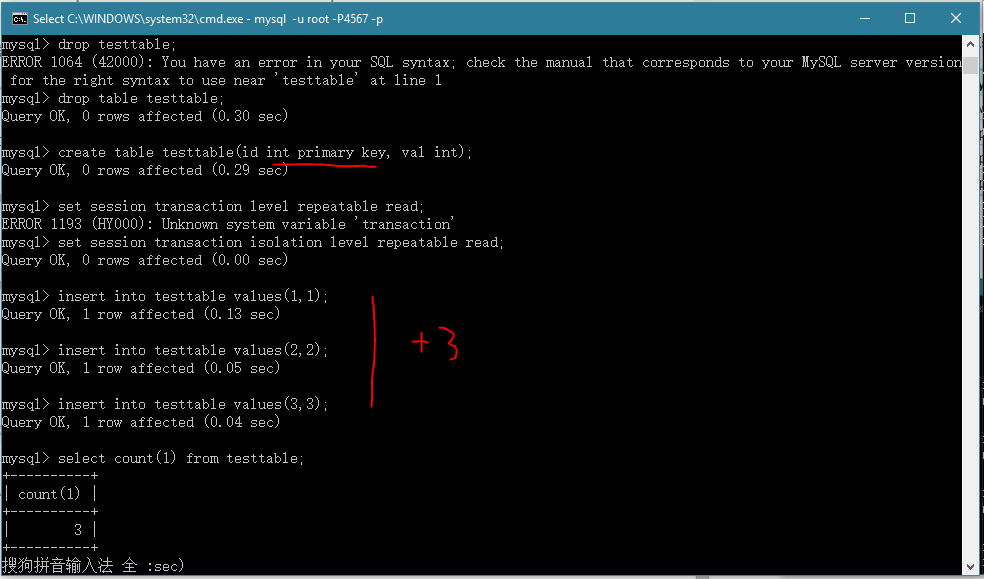
[2]然后分别开另外一个事务插入一条数据.
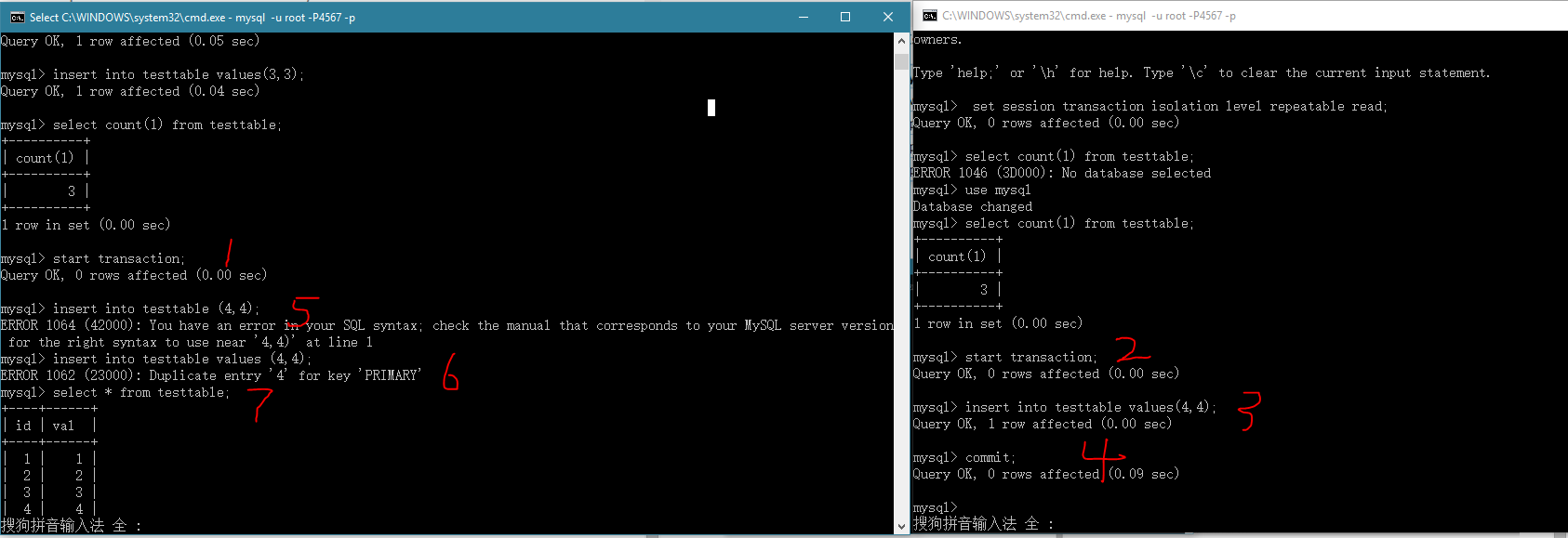
你会发现事务1就会很郁闷,开始只有3条数据,过一下再查就有4条了.

















 4513
4513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









