







PostgreSQL 10 - 理解事务和锁
使用PostgreSQL事务
PostgreSQL提供了非常先进的事务机制。首先,在PostgreSQL中,所有的事都是一个事务。如果你发送一个简单的查询,也是一个事务。下面是个例子:

在这个例子中,SELECT语句是一个单独的事务,如果再次执行该语句,会返回不同的时间戳。因为now()函数返回事务的时间,所以,这条SELECT语句返回两个相同的时间戳。
如果一个事务中不止一条语句,必须使用BEGIN语句。

BEGIN语句确保多条命令被打包进一个事务。看看它是如何工作的:
可以看到,两个时间戳是相同的。上面说过了,返回的是事务的时间。
要结束一个事务,使用COMMIT。
COMMIT、COMMIT WORK和COMMIT TRANSACTION的作用是相同的。END语句的作用也和COMMIT相同。
COMMIT的对应物是ROLLBACK,它会简单地停止事务,对其他事务不可见。当然,使用ABORT的效果相同。
处理事务内部的错误
事务不是总能正确结束。PostgreSQL中,只有error-free的事务能被committed。
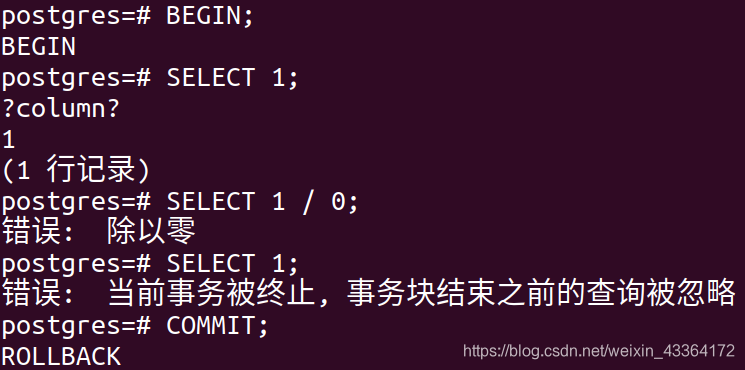
PostgreSQL会出错。在错误发生后,不再接受语句-即使是语义和语法上都正确的语句。然后,即使执行COMMIT,也会回滚事务。
使用SAVEPOINT
写长事务而不遇到错误是很难的。要解决这问题,用户可以使用安全点-事务内的安全点是如果碰到了严重错误,应用可以返回的地点。
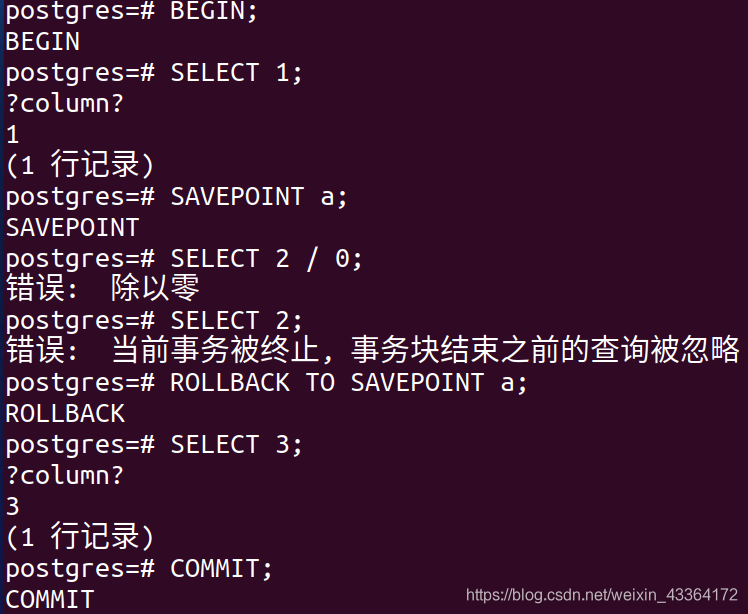
在第一条SELECT语句之后,我决定增加安全点,确保在事务中,应用总能返回该点。安全点有一个名字,在后面被引用。
在返回安全点a以后,事务能正常进行。代码跳回错误之前,所以,每件事情都是好的。
事务内的安全点几乎是没限制的。我们可以在一个事务内定义超过25万个安全点。
可以使用RELEASE SAVEPOINT删除安全点:
安全点的生存周期随着事务的结束而结束。
Transactional DDLs
PostgreSQL的一个功能,连许多商业数据库都没有。这就是,在PostgreSQL中,可以在事务块内部运行DDLs(改变数据结构的命令)。典型的商业数据库,一个DDL会隐式地提交当前事务。而PostgreSQL不会。
除了一些小例外(DROP DATABASE、CREATE TABLESPACE、DROP TABLESPACE等),其他DDLs都是transactional。
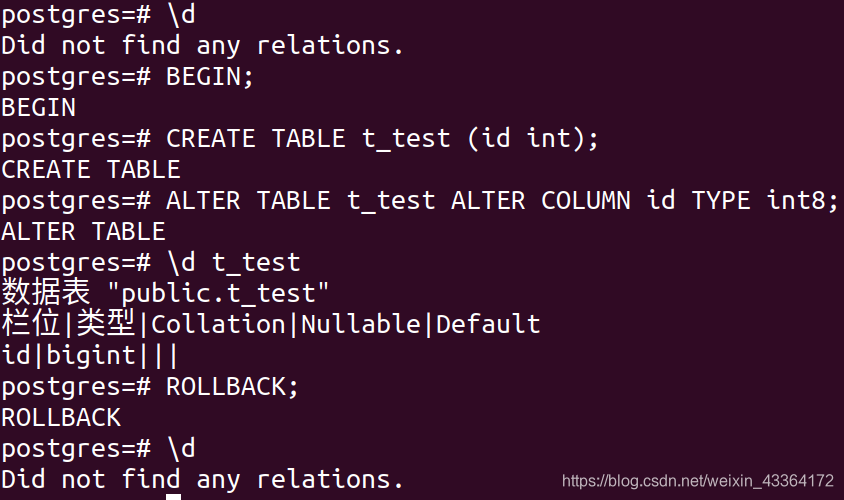
这个例子,表能被增加和修改,事务也能被终止。没有隐式提交或者其他奇怪的行为。
理解基本锁
我们先建一张表,并添加一行记录。
postgres=# CREATE TABLE t_test (id int);
CREATE TABLE
postgres=# INSERT INTO t_test VALUES (1);
INSERT 0 1
该表可以被并发读。很多用户在相同的时间读相同的数据,而不会互相阻塞。
问题来了:如果读和写同时发生,会发生什么?下面是一个例子,让我们假设该表包含一行,它的id是0
| 事务1 | 事务2 |
|---|---|
| BEGIN; | BEGIN; |
| UPDATE t_test SET id = id + 1 RETURNING *; | |
| 用户会看到1 | SELECT * FROM t_test; |
| 用户会看到0 | |
| COMMIT; | COMMIT; |
打开两个事务。第一个修改一行,这没问题,因为第二个事务可以继续。它会返回UPDATE语句之前的旧行。该行为就是多版本并发控制(MVCC)。
一个事务被提交以后才会被看到。一个事务不能检查另一个活动事务的修改。而且,写事务不会阻塞读事务。
事务被提交以后,表里包含2。如果同时修改数据,会发生什么?
| 事务1 | 事务2 |
|---|---|
| BEGIN; | BEGIN; |
| UPDATE t_test SET id = id + 1 RETURNING *; | |
| 它会返回3 | UPDATE t_test SET id = id + 1 RETURNING *; |
| 它会等待事务1 | |
| COMMIT; | 它会等待事务1 |
| 它会重读该行,找到3,设置值,返回4 | |
| COMMIT; |
假设你要在web站点记录点击数。如果你运行该代码,点击不会丢失,因为PostgreSQL会在一个执行完以后再执行另一个。
PostgreSQL只锁UPDATE影响的行。所以,如果你有1000行,理论上可以在该表同时执行1000个并发修改。
另外,你始终可以执行并发读,并发写不会影响并发读。
避免典型错误和明确地锁
看下面的例子
| 事务1 | 事务2 |
|---|---|
| BEGIN; | BEGIN; |
| SELECT max(id) FROM product; | SELECT max(id) FROM product; |
| 用户会看到17 | 用户会看到17 |
| 用户决定使用18 | 用户决定使用18 |
| INSERT INTO product … VALUES (18, …) | INSERT INTO product … VALUES (18, …) |
| COMMIT; | COMMIT; |
这样做,要不是重复的key,要不就是两个相同的条目。
要解决这问题,可以明确地使用表锁。
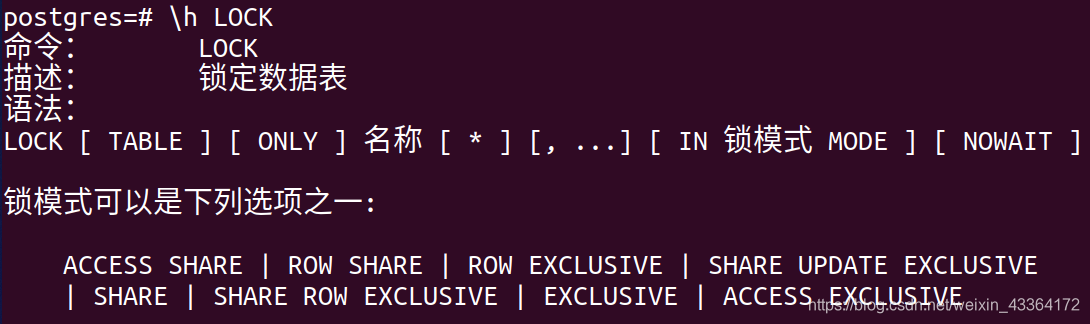
要锁一个表,PostgreSQL支持八种类型的锁:
- ACCESS SHARE:读锁,和ACCESS EXCLUSIVE冲突。事实上,它意味着如果表将要被drop,不能开始SELECT。也意味着DROP TABLE在等待一个读事务的完成
- ROW SHARE:在SELECT FOR UPDATE/SELECT FOR SHARE的时候,PostgreSQL采用这种锁。它和EXCLUSIVE、ACCESS EXCLUSIVE冲突
- ROW EXCLUSIVE:INSERT、UPDATE和DELETE的时候使用。和SHARE、SHARE ROW EXCLUSIVE、EXCLUSIVE和ACCESS EXCLUSIVE冲突
- SHARE UPDATE EXCLUSIVE:CREATE INDEX CONCURRENTLY、ANALYZE、ALTER TABLE和VALIDATE的时候,以及通过VACUUM(不是VACUUM FULL)的ALTER TABLE采用。和SHARE UPDATE EXCLUSIVE、SHARE、SHARE ROW EXCLUSIVE、EXCLUSIVE和ACCESS EXCLUSIVE冲突
- SHARE:当增加索引时,使用SHARE锁。和ROW EXCLUSIVE、SHARE UPDATE EXCLUSIVE、SHARE ROW EXCLUSIVE、EXCLUSIVE和ACCESS EXCLUSIVE冲突
- SHARE ROW EXCLUSIVE:CREATE TRIGGER时,或者一些ALTER TABLE时使用。和除了ACCESS SHARE以外的其他锁冲突
- EXCLUSIVE:迄今为止最严格的锁。它保护读和写。如果一个事务使用了该锁,其他人不能读或者写受影响的表
- ACCESS EXCLUSIVE:防止读和写的并发事务
所以,前面的max问题,可以使用下面的办法解决:
BEGIN;
LOCK TABLE product IN ACCESS EXCLUSIVE MODE;
INSERT INTO product SELECT max(id) + 1, ... FROM product;
COMMIT;
记住,这样做非常讨厌,在你操作期间,其他人都不能读或者写该表。因此,要不惜一切代价避免ACCESS EXCLUSIVE。
考虑替代方案
下面是一个替代方案。考虑下面的例子:你要写一个程序生成的发票数,它不能有间隙也不能重复。如果不使用表锁,可以这样做:
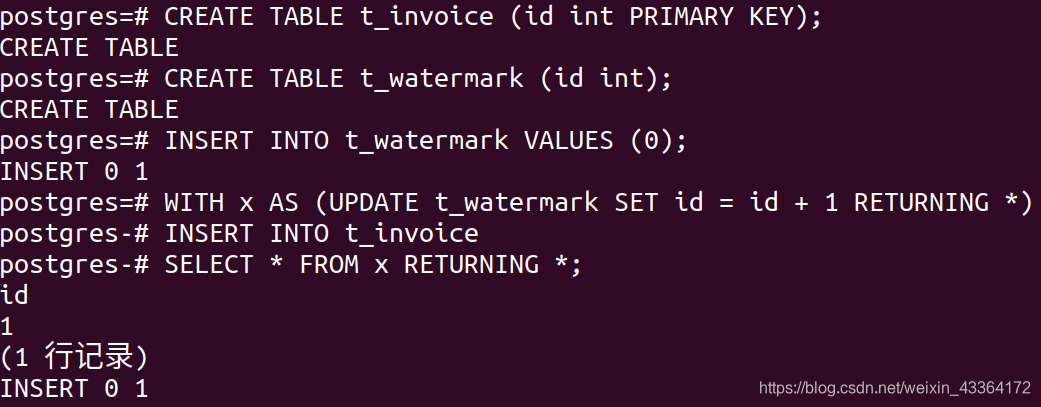
本例中,我使用了表t_watermark。它只有一行。首先执行WITH,该行被锁并且增加,返回新值。某一时刻只能有一个人做此事。该CTE返回的值被用于发票表。它肯定是唯一的。而且,watermark表只有一个简单的行锁;invoice表也不会发生读阻塞。
使用FOR SHARE和FOR UPDATE
有时候,数据从数据库中查询出来,经过处理,最后,修改以后保存回数据库。这是经典的SELECT FOR UPDATE的例子。比如
BEGIN;
SELECT * FROM invoice WHERE processed = false;
** 应用逻辑 **
UPDATE invoice SET processed = true ...
COMMIT;
问题是如果两个人可能选择了相同的未处理的数据,可能导致修改被覆盖。所以,可以这样使用SELECT FOR UPDATE:
BEGIN;
SELECT * FROM invoice WHERE processed = false FOR UPDATE;
** 应用逻辑 **
UPDATE invoice SET processed = true ...
COMMIT;
像UPDATE一样,SELECT FOR UPDATE会锁行。这样就不会发生并发修改。所有的锁在COMMIT的时候被释放。
如果一个SELECT FOR UPDATE在等其他的SELECT FOR UPDATE,就必须等到完成的时候(COMMIT或者ROLLBACK)。如果第一个事务不想结束,第二个事务可能会永远等下去。为了避免这个,可以使用SELECT FOR UPDATE NOWAIT。
| 事务1 | 事务2 |
|---|---|
| BEGIN; | BEGIN; |
| SELECT … FROM tab WHERE … FOR UPDATE NOWAIT; | |
| 一些处理 | SELECT … FROM tab WHERE … FOR UPDATE NOWAIT; |
| 一些处理 | 错误: 无法在关系 "tab"中的记录上获得锁 |
如果认为NOWAIT不够灵活,可以使用lock_timeout。它会包含想等待锁的时间。你可以在session级别做设置:
postgres=# SET lock_timeout TO 5000;
SET
这样,该值是5秒。
虽然SELECT基本上是无锁的,但是SELECT FOR UPDATE比较苛刻。想像如下业务流程:飞机有200个座位,很多人想并发预订座位。可能会发生:
| 事务1 | 事务2 |
|---|---|
| BEGIN; | BEGIN; |
| SELECT … FROM flight LIMIT 1 FOR UPDATE; | |
| 等待用户输入 | SELECT … FROM flight LIMIT 1 FOR UPDATE; |
| 等待用户输入 | 它不得不等 |
麻烦的是,一次只能预订一个座位。有可能还有200个空座位,但是每个人不得不等第一个人。当第一个座位被阻塞了,其他人就不能预订,即使他们不关心最终得到哪个座位。
SELECT FOR UPDATE SKIP LOCKED可以解决该问题。我们先增加一些例子数据:
postgres=# CREATE TABLE t_flight AS SELECT * FROM generate_series(1, 200) AS id;
SELECT 200
然后:
| 事务1 | 事务2 |
|---|---|
| BEGIN; | BEGIN; |
| SELECT * FROM t_flight LIMIT 2 FOR UPDATE SKIP LOCKED; | SELECT * FROM t_flight LIMIT 2 FOR UPDATE SKIP LOCKED; |
| 它会返回1和2 | 它会返回3和4 |
如果每个人想得到两行,可以同时满足100个并发事务,而不用担心事务被阻塞。
有时候,FOR UPDATE可能产生意想不到的后果。大多数人不知道,FOR UPDATE会对外键产生影响。比如有两张表,一个保存钱,一个保存账户:
CREATE TABLE t_currency (id int, "name" text, PRIMARY KEY (id));
INSERT INTO t_currency VALUES (1, 'EUR');
INSERT INTO t_currency VALUES (2, 'USD');
CREATE TABLE t_account (
id int,
currency_id int REFERENCES t_currency (id) ON UPDATE CASCADE ON DELETE CASCADE,
balance numeric);
INSERT INTO t_account VALUES (1, 1, 100);
INSERT INTO t_account VALUES (2, 1, 200);
现在,我们想在帐号表运行SELECT FOR UPDATE:
| 事务1 | 事务2 |
|---|---|
| BEGIN; | |
| SELECT * FROM t_account FOR UPDATE; | BEGIN; |
| 等待用户继续 | UPDATE t_currency SET id = id * 10; |
| 等待用户继续 | 等待事务1 |
虽然是在帐号表运行SELECT FOR UPDATE,但是,帐号表的UPDATE会被阻塞。这是必要的,否则,修改会破坏外键约束。
在FOR UPDATE之上,还有FOR SHARE、FOR NO KEY UPDATE和FOR KEY SHARE:
- FOR NO KEY UPDATE:和FOR UPDATE类似。但是,该锁比较弱,可以和SELECT FOR SHARE共存
- FOR SHARE:FOR UPDATE足够强壮,认定你要修改行。FOR SHARE不一样,同时可以有多个事务持有FOR SHARE锁
- FOR KEY SHARE:它的行为和FOR SHARE类似,只能更弱。它会阻塞FOR UPDATE而不会阻塞FOR NO KEY UPDATE
理解事务隔离级别
| 事务1 | 事务2 |
|---|---|
| BEGIN; | |
| SELECT sum(balance) FROM t_account; | |
| 用户会看到300 | BEGIN; |
| - | INSERT INTO t_account (balance) VALUES (100); |
| - | COMMIT; |
| SELECT sum(balance) FROM t_account; | |
| 用户会看到400 | |
| COMMIT; |
大多数用户希望左边的事务总是返回300,而不管右边的事务。但是,这是错误的。默认地,PostgreSQL运行在READ COMMITTED事务隔离级别模式。这意味着事务内的每条语句会得到数据的新的快照。
一条SQL语句会在同一个快照上运行,而忽略它运行时候的并发事务的修改。
如果你使用TRANSACTION ISOLATION LEVEL REPEATABLE READ,在真个事务执行期间,都使用相同的快照。看看会发生什么:
| 事务1 | 事务2 |
|---|---|
| BEGIN; | |
| SELECT sum(balance) FROM t_account; | |
| 用户会看到300 | BEGIN; |
| INSERT INTO t_account (balance) VALUES (100); | |
| COMMIT; | |
| SELECT sum(balance) FROM t_account; | SELECT sum(balance) FROM t_account; |
| 用户看到300 | 用户看到400 |
| COMMIT; |
第一个事务会冻结数据的快照。对于报表系统,这样做很重要。报表的第一页和最后一页应该用的是相同的数据。因此,可重复读是报表一致的关键。
Repeatable read比read committed更昂贵。对于普通的OLTP,read committed有各种优点,因为能更早看到变化。
考虑SSI事务
在read committed和repeatable read之上,PostgreSQL还有Serializable Snapshot Isolation事务。所以,PostgreSQL支持三种隔离级别。注意,不支持read uncommitted:如果你想开始一个read uncommitted事务,PostgreSQL会默默地转换到read committed。
串行背后的思想是简单的;如果一个事务在只有一个用户时可以正确工作,它也会在SSI级别下正确地并发工作。但是,用户要准备好,事务可能会失败和错误退出。还会有性能问题。
只有在非常熟悉数据库引擎的情况下,才应该考虑串行隔离级别。
死锁和类似的问题
基本上,如果两个事务互相等待,就会发生死锁。
假设我们有包含两行的表:
CREATE TABLE t_deadlock (id int);
INSERT INTO t_deadlock VALUES (1), (2);
| 事务1 | 事务2 |
|---|---|
| BEGIN; | BEGIN; |
| UPDATE t_deadlock SET id = id * 10 WHERE id = 1; | UPDATE t_deadlock SET id = id * 10 WHERE id = 2; |
| UPDATE t_deadlock SET id = id * 10 WHERE id = 2; | |
| 等待事务2 | UPDATE t_deadlock SET id = id * 10 WHERE id = 1; |
| 等待事务2 | 错误: 检测到死锁 … |
一旦检测到死锁,就显示如下信息
错误: 检测到死锁
描述: 进程3827等待在事务 684上的ShareLock; 由进程20965阻塞.
进程20965等待在事务 685上的ShareLock; 由进程3827阻塞.
提示: 详细信息请查看服务器日志.
背景: 当更新关系"t_deadlock"的元组(0, 1)时
PostgreSQL甚至可以告诉我们哪行导致了冲突。本例中,都是因为tuple (0, 1)。它是ctid,是表内一行数据的唯一标识。它告诉我们,行在表内的物理位置。本例中,位于第一个块(0)的第一行。
如果该行对事务还是可见的,甚至可以查询到它:
postgres=# SELECT ctid, * FROM t_deadlock WHERE ctid = '(0, 1)';
ctid | id
-------+----
(0,1) | 1
(1 行记录)
并不只是死锁能导致事务失败。事务没有串行的时候,也会发生。看下面的例子,先假设两行的id分别是1和2。
| 事务1 | 事务2 |
|---|---|
| BEGIN ISOLATION LEVEL REPEATABLE READ; | |
| SELECT * FROM t_deadlock; | |
| 返回两行 | |
| - | DELETE FROM t_deadlock; |
| SELECT * FROM t_deadlock; | |
| 返回两行 | |
| DELETE FROM t_deadlock; | |
| 事务error-out(错误: 由于同步更新而无法串行访问) |
本例中,两个并发事务在工作。当事务1只是在查询数据的时候,每件事都是好的,这是因为PostgreSQL能保护静态数据。但是,当第二个事务提交了DELETE之后,读还是没问题的。当事务1试图删除或者修改数据的时候,就不行了。
应用advisory locks
PostgreSQL有高效、复杂的事务机制,能以精细而有效的机制处理锁。前些年,大家只能使用同步代码。
于是,协同锁出生了。
使用咨询锁的时候,COMMIT的时候不要像普通锁那样离开,要以安全可靠的方式解锁。
如果你决定使用协同锁,你真正锁的是一个数字,它跟行或者数据无关。看下面的例子:
| Session 1 | Session 2 |
|---|---|
| BEGIN; | - |
| SELECT pg_advisory_lock(15); | - |
| - | SELECT pg_advisory_lock(15); |
| - | 它在等待 |
| COMMIT; | 它还在等待 |
| SELECT pg_advisory_unlock(15); | 它仍然等待 |
| - | 锁了 |
第一个事务锁了15,第二个事务只能等着锁被释放。第二个甚至会等到第一个提交以后。
可以使用pg_advisory_unlock_all()解除全部锁。
有时候,你可能想看是否能得到一个锁,
优化存储和管理清除
事务是PostgreSQL不可或缺的一部分。但是,它可能为并发用户提供不同的数据。此外,DELETE和UPDATE不能真的覆盖数据,否则ROLLBACK会无法工作。如果碰巧在一个大型的DELETE操作中,你不能判断是否可以COMMIT。还有,当你执行DELETE的时候,数据仍然是可见的,甚至在修改完成以后,一些数据还是可见的。
所以,清理必须异步进行。事务不能清理自己带来的混乱,COMMIT/ROLLBACK可能太早关心死亡的行。
使用VACUUM解决该问题:
VACUUM能访问所有可能已经修改的页,找到所有死亡空间。然后通过关系的自由空间映射(FSM)跟踪找到的自由空间。
注意,大多数情况下,VACUUM不会缩小表的大小。它会跟踪并找到存储文件中的自由空间。VACUUM之后,表一般还有相同的大小。
如果表的结尾有无效的行,文件大小可能会变小(这一般是例外)。
配置VACUUM和autovacuum
在PostgreSQL的早期,大家只能手动运行VACUUM。现在,管理员可以使用工具autovacuum,它是PostgreSQL服务器的一部分。它在后台自动执行清理工作。它每分钟醒一次(postgresql.conf文件中,autovacuum_naptime = 1)检查是否有可做的工作。如果有工作,autovacuum会通过主进程fork三个工作进程(postgresql.conf中的autovacuum_max_workers)。
autovacuum的触发标准是(postgresql.conf):
autovacuum_vacuum_threshold = 50
autovacuum_analyze_threshold = 50
autovacuum_vacuum_scale_factor = 0.2
autovacuum_analyze_scale_factor = 0.1
autovacuum_vacuum_scale_factor告诉PostgreSQL,如果表的20%数据被改变了,就值得VACUUM。问题是如果表只有一行,一个改变已经是100%了。fork一个进程清理一行是没有意义的。因此,autovacuum_vacuuum_threshold指出,这20%必须最少50行。优化器统计数据的创建的机制与此相同(10%和50)。理想的情况下,autovacuum在VACUUM期间,为避免不必要地访问表,增加新的统计。
深入事务的wraparound相关问题
还有两个重要配置
autovacuum_freeze_max_age = 200000000
autovacuum_multixact_freeze_max_age = 400000000
要理解整个问题,先要理解PostgreSQL怎么处理并发。PostgreSQL的事务机制基于比较事务ID和事务的状态。
让我们看一个例子。如果我正在处理事务4711,你在处理事务4712,我不能看到你,因为你还在运行。如果我在运行事务4711的时候,你已经运行完事务3900,我能看到你已经提交的,如果你失败了我会忽略。问题是,事务ID是有限的。在某一时刻,事务ID开始wrap around。这意味着,事务5可能在事务800000000的后面运行。PostgreSQL如何知道哪个在先呢?它会保存一个水印(watermark)。有时候,当VACUUM开始的时候,会调整水印。通过运行VACUUM,你能确保水印被调整,让未来有足够的事务ID。
注意,不是每个事务都增加事务ID计数器。只要事务仍然在读,就只有一个虚拟事务ID。这样事务ID不会增长地太快。
autovacuum_freeze_max_age定义事务的最大值-在VACUUM操作执行前,一个表的pg_class.relfrozenxid域能达到的最大值-防止表内的事务ID wraparound。这个值相当低,因为它对clog清理有影响(clog或者commit log是一个数据结构,每个事务保存两位,指示事务running、aborted、committed或者是一个子事务)。
autovacuum_multixact_freeze_max_age配置最大年龄(multixacts)-在VACUUM操作执行前,一个表的pg_classrelminmxid域能达到的最大值-防止表内的multixact ID wraparound。
通常,应该降低VACUUM负载。大表的VACUUM实例是很昂贵的,因此要密切关注这些设置。
VACUUM FULL
你也可以使用VACUUM FULL。VACUUM FULL实际上锁了表,而且重写了整个关系。对于小表,可能还比较合理。如果表比较大,可能会锁很长时间。VACUUM FULL会阻塞写。
在工作中看VACUUM
先建表,添加记录。
CREATE TABLE t_test (id int) WITH (autovacuum_enabled = off);
INSERT INTO t_test
SELECT * FROM generate_series(1, 100000);
这样增加了一张表,包含10万行记录。可以关闭表的autovacuum,不过,对于大多数应用,这样做不是个好主意。考虑一个生存期很短的表,开发者知道表只能存活几秒钟,那么清除元组是没有意义的。对于数据仓库,如果表用作staging areas,也可以关闭autovacuum。本例中,关闭它可以确保后台不做任何事情,你看到的都是我触发的,而不是后台进程。
首先,检查表的大小
postgres=# SELECT pg_size_pretty(pg_relation_size('t_test'));
pg_size_pretty
3544 kB
(1 行记录)
然后,更新所有的行
postgres=# UPDATE t_test SET id = id + 1;
UPDATE 100000
数据库引擎拷贝了所有的行。为什么?
- 我们不知道事务是否会成功。所以数据不能被覆盖
- 并发事务仍然可以看到数据的旧版本
所以,UPDATE会拷贝行。
可以看到,表变大了
postgres=# SELECT pg_size_pretty(pg_relation_size('t_test'));
pg_size_pretty
7080 kB
(1 行记录)
UPDATE以后,人们可能试着把空间返还给文件系统
postgres=# VACUUM t_test;
VACUUM
我们已经知道了,VACUUM不会把空间返还给文件系统。而是,它会允许空间被重新使用。表没有变小
postgres=# SELECT pg_size_pretty(pg_relation_size('t_test'));
pg_size_pretty
7080 kB
(1 行记录)
下一个UPDATE不会让表变大,这是因为它会吃掉表内的自由空间。再一次UPDATE就会把表变大,因为空间都没用了,需要更多的空间:
postgres=# UPDATE t_test SET id = id + 1;
UPDATE 100000
postgres=# SELECT pg_size_pretty(pg_relation_size('t_test'));
pg_size_pretty
7080 kB
(1 行记录)
postgres=# UPDATE t_test SET id = id + 1;
UPDATE 100000
postgres=# SELECT pg_size_pretty(pg_relation_size('t_test'));
pg_size_pretty
10 MB
(1 行记录)
然后执行
VACUUM t_test;
UPDATE t_test SET id = id + 1;
VACUUM t_test;
大小还是没变化,让我们看看表内:
postgres=# SELECT ctid, * FROM t_test ORDER BY ctid DESC;
ctid | id
-----------+-----
(1327,46) | 112
(1327,45) | 111
(1327,44) | 110
(1327,43) | 109
...
(884,20) | 99798
(884,19) | 99797
...
ctid是行在磁盘上的物理位置。使用ORDER BY ctid DESC,就是以物理顺序从后往前读表。在表的结尾,有一些很小的值和一些很大的值。
为什么表的结尾有很多小的和大的值呢?在表保存10万条数据以后,最后的块没充满,所以,第一个UPDATE会充满最后的块,表的结尾被清洗了一点。
执行删除会发生什么?
postgres=# DELETE FROM t_test WHERE id > 99000 OR id < 1000;
DELETE 1999
postgres=# VACUUM t_test;
VACUUM
postgres=# SELECT pg_size_pretty(pg_relation_size('t_test'));
pg_size_pretty
3504 kB
(1 行记录)
虽然只删除了2%的数据,表的大小减少了2/3。这是因为如果VACUUM在表的一定位置之后只找到死行,可以返还空间给文件系统。
当然,用户一般不能控制数据在磁盘上的位置。因此,除非删除所有的行,存储空间不会变小。
利用snapshot too old
VACUUM会根据需要回收空间。那么,什么时候VACUUM能实际上清理行,返还自由空间呢?规则是:如果一行记录不能再被任何人看到,可以被回收。实际上,这意味着最老的活的事务也不能再看到的任何事情,都可以认为已经死了。
这也意味着长事务会推迟清理,然后表就膨胀了,性能也随之下降。幸运的是,从PostgreSQL 9.6开始,数据库有了一个很好的特性,允许管理员智能地限制事务的持续时间。Oracle管理员很熟悉快照太旧的错误,从PostgreSQL 9.6开始,也有该错误消息了。
可以在postgresql.conf中这样限制快照的生存期:
old_snapshot_threshold = -1
# 1min-60d; -1 disables; 0 is immediate
如果设置了该变量,事务会在一定时间后失败。注意,这个设置是实例级别的,而不是session内的设置。














 2361
2361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









