







不需要登陆就可以取到数据,采用urllib2进行网页内容获取,BeautifulSoup进行网页内容解析,源代码:
# encoding:utf-8
'''
Created on 2015年1月17日
@author:
'''
import urllib2
from bs4 import BeautifulSoup
myUrl = "http://m.qiushibaike.com/hot/page/1"
headers={"User-Agent": "Mozilla/5.0 (Windows NT 6.1; rv:11.0) Gecko/20100101 Firefox/11.0"}
req=urllib2.Request(myUrl,headers=headers)
myResponse = urllib2.urlopen(req)
myPage = myResponse.read()
# print myPage
soup=BeautifulSoup(myPage)
items=soup.find_all('div',{'class':'article block untagged mb15'})
i=0
for item in items:
i+=1
print '============',i,'============'
contenttag=item.find('div',{'class':'content'})
print 'time:',contenttag.get('title'),'\ncontent:',contenttag.string.strip(),
imgtag=item.find('img')
if imgtag!=None:
print '\nimgtag:',imgtag.get('alt')
else:
print '\nimgtag:',imgtag
statstag=item.find_all('i',{'class':'number'})
print 'stats:',statstag[0].string,'\ncomments:',statstag[1].string
votestag=item.find_all('span',{'class':'number hidden'})
print 'up:',votestag[0].string,'\ndown:',votestag[1].string
控制台输出的采集结果:
============ 1 ============
time: 2015-01-16 20:19:15
content: 就是这么牛逼
imgtag: 無神论
stats: 7601
comments: 83
up: 7793
down: -192
============ 2 ============
time: 2015-01-16 20:02:02
content: 不就是一个不小心嘛,别顶太高了哦��
imgtag: 胡思乱想瞎操心
stats: 6342
comments: 73
up: 6526
down: -184
============ 3 ============
time: 2015-01-16 22:09:49
content: 太霸气!愿大家新年发发发
imgtag: 找个炮友找半年
stats: 4124
comments: 20
up: 4244
down: -120
============ 4 ============
time: 2015-01-16 19:08:10
content: 那时候很穷,但是很开心!现在的你多久没有这么放开心扉的笑了?
imgtag: 月黑风高操石丹丹
stats: 5315
comments: 65
up: 5477
down: -162
...
经过以上简单测试,证明代码可行,进一步抽象与封装之后,对代码进行重构如下:
# encoding:utf-8
'''
Created on 2015年1月17日
@author:
'''
import urllib2
import xlwt
from bs4 import BeautifulSoup
# 存储数据并打印数据
def save_print(items, table,row):
print '==========获取第',num,'页数据============='
i = 1
for item in items:
j = 0
print '-----------', i, '-----------'
contenttag = item.find('div', {'class':'content'})
time=contenttag.get('title')#发布时间
table.write(row, j, time)
j += 1#python竟然没有自增运算
contents=contenttag.strings#发布的内容
content=''#有些内容有换行的,内容中间会出现</br>标签,这种情况下contenttag.getstring会返回None
for con in contents:
content+=con.strip()
table.write(row, j, content)
j += 1
print 'time:', time, '\ncontent:', content
imgtag = item.find('div',{'class':'thumb'})
if imgtag != None:
print 'imgtag:', imgtag.a.get('alt')
table.write(row, j, 1)#该条糗事有图片的标记
else:
print 'imgtag:', imgtag
table.write(row, j, 0)#该条糗事无图片的标记
j += 1
statstag = item.find_all('i', {'class':'number'})
if len(statstag)==2:
stats=statstag[0].string#赞(+)与踩(-)的和
comments=statstag[1].string#评论数
elif len(statstag)==1:
stats=statstag[0].string
comments=0
else:
stats=0
comments=0
print 'stats:', stats, '\ncomments:', comments
table.write(row, j, stats)
j += 1
table.write(row, j, comments)
j += 1
votestag = item.find_all('span', {'class':'number hidden'})
up=votestag[0].string
down=votestag[1].string
print 'up:', up, '\ndown:', down
table.write(row, j, up)
j += 1
table.write(row, j, down)
j += 1
i += 1
row+=1
# 获取网页内容
def getPage(page):
req = urllib2.Request(page, headers=headers)
myResponse = urllib2.urlopen(req)
print myResponse.geturl()
myPage = myResponse.read()
soup = BeautifulSoup(myPage)
items = soup.find_all('div', {'class':'article block untagged mb15'})
return items
# 网页入口
url = "http://m.qiushibaike.com/hot/page/"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; rv:11.0) Gecko/20100101 Firefox/11.0"}
# 创建excel用于存储数据
newfile = xlwt.Workbook()
table = newfile.add_sheet('data', True)
table.write(0, 0, 'time')
table.write(0, 1, 'content')
table.write(0, 2, 'imgtag')
table.write(0, 3, 'stats')
table.write(0, 4, 'comments')
table.write(0, 5, 'up')
table.write(0, 6, 'down')
# 采集前150个网页的数据
row=1
for num in range(1, 151):
myUrl = url + str(num)
items = getPage(myUrl)
save_print(items, table,row)
row+=len(items)
newfile.save(r'E:/java/data.xls')
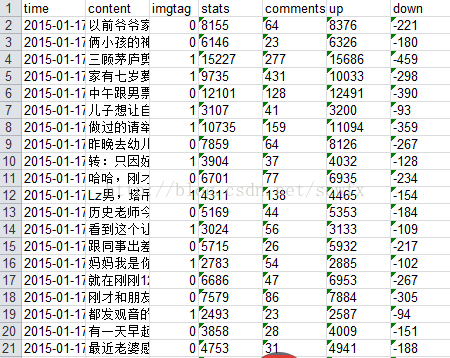
有了数据下一步的工作就是对这些数据进行分析,从而得出潜在有用的知识,这才是目的,资源在这里http://download.csdn.net/detail/scwfx/8394557
分析数据和数据可视化使用R进行
分析数据和数据可视化使用R进行
library(ggplot2)
library(xlsx)
data<-read.xlsx('e:/java/data.xls',1,encoding='utf-8',stringsAsFactors=F)
为数据添加顺序列,看看导入效果
num<-1:nrow(data)
data<-transform(data,num)
head(data[-2],3)
还记得python存进去的数据是字符串吗?检查一下结果果然是character,看来还得先转换一下
class(data['up'][1,])
[1] "character"
data[c(-1,-2)]<-apply(data[c(-1,-2)],2,as.integer)
class(data['up'][1,])
[1] "integer"
数据准备好以后,为了更直观,先用ggplot2画点图看看可视化结果
qplot(num,stats,data=data,geom='point')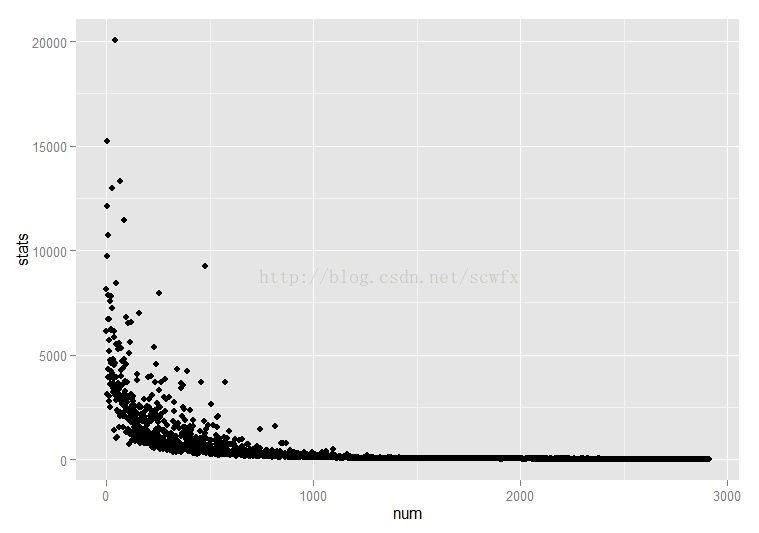
长尾比较明显,大概前面500条(每页20条,25页)评论稍多,后面的就比较少了。看看前500条数据的up和down如何分布
ggplot(data[1:500,],aes(num))+
geom_line(aes(y=up),colour='blue')+
geom_line(aes(y=down),colour='red')
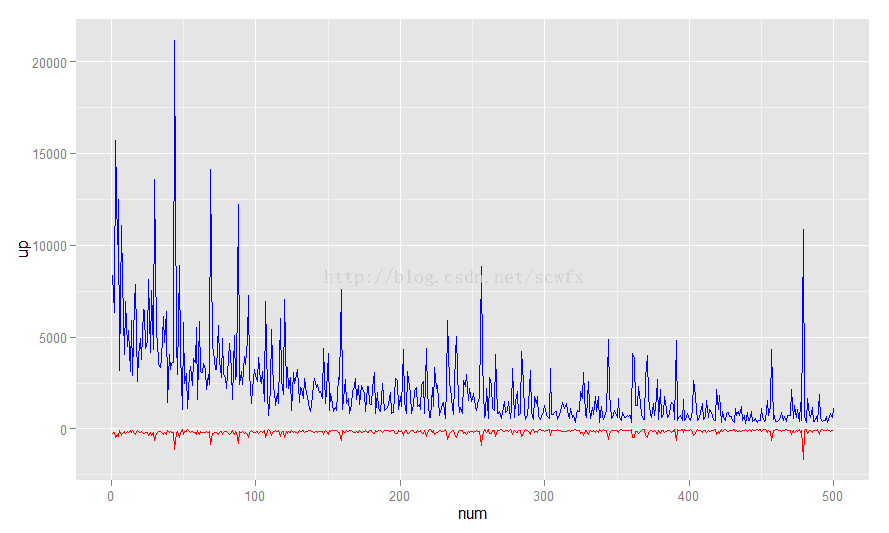
如此看来down和up之间没啥线性关系,虽然越往后up的总体趋势是递减的,单down却分布很均匀。看来不管写什么都会有人踩。下面再看看有图糗事与无图糗事的比例:
pie<-ggplot(data,aes(x=factor(1),fill=factor(imgtag)))+geom_bar(width=1)+coord_polar(theta='y')
pie+xlab('')+labs(fill='Types')
table(data['imgtag'])
0 1
1318 1595
table(data['imgtag'])/nrow(data)
0 1
0.4524545 0.5475455
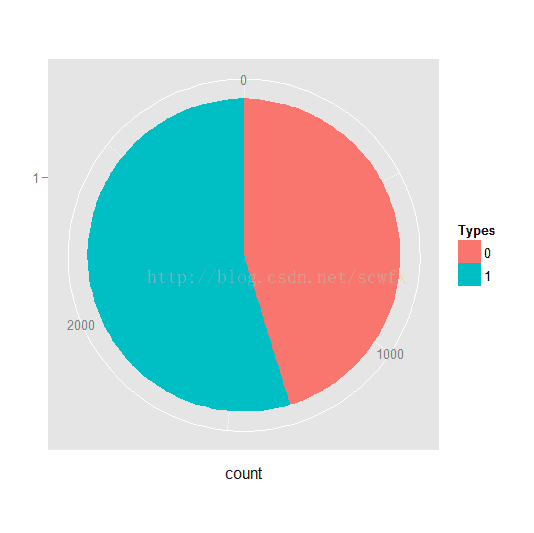
有图占54.75%,无图占45.24%,有图稍多。智能手机时代,随时随地都可以拍照上传,大家都懒得码字了,直接上图。那么,有图和无图与糗事受欢迎程度之间有没有联系呢?
qplot(num,up,color=factor(imgtag),geom='line',data=data[1:500,])
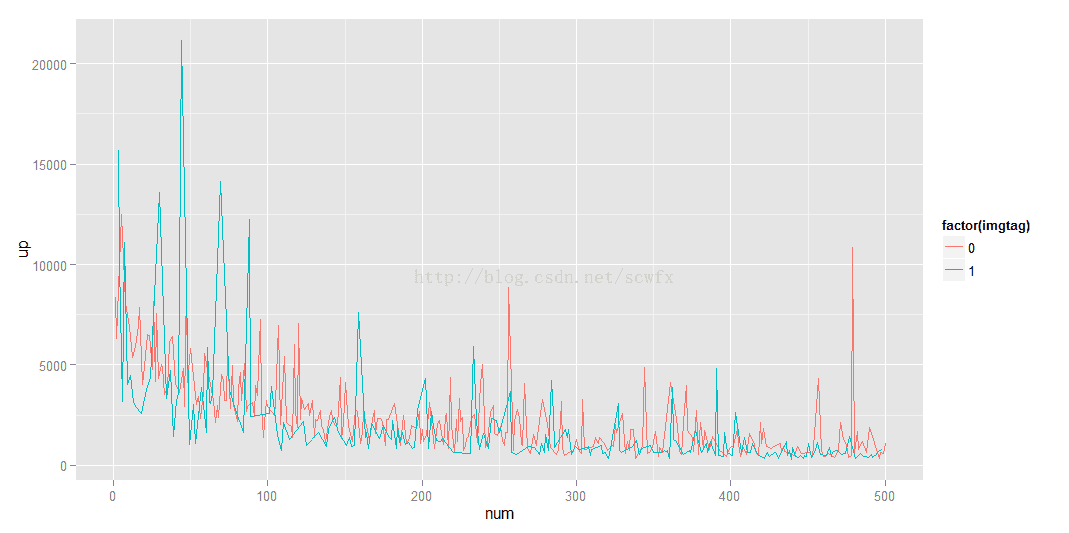
如此看来,受欢迎程度最高的主要是有图有真相类的。长尾部分则区别不太明显。接下来再看看发布时间的分布规律。
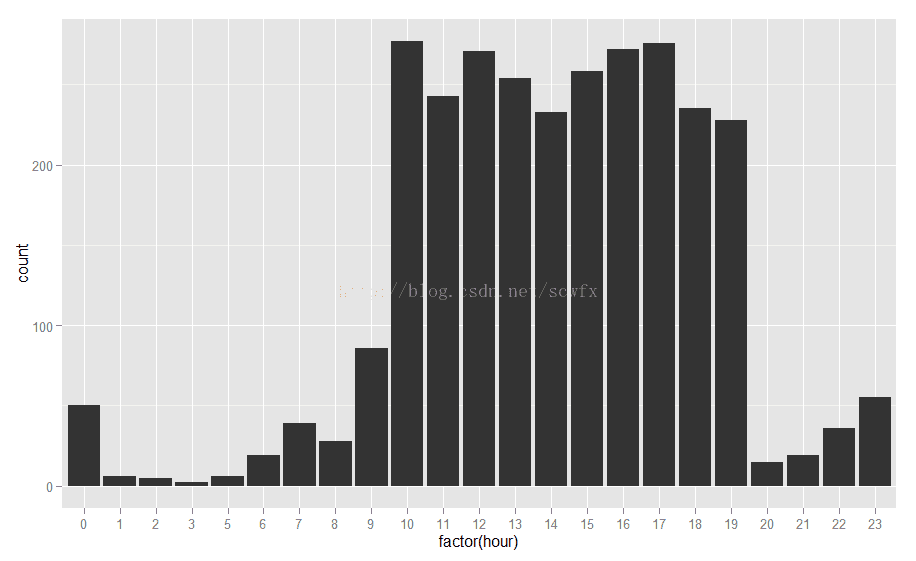
数据为周六抓取,看来我等屌丝们都比较懒,9点钟、10点钟才爬起来,直到晚上7点钟,才稍有消停。而且,长夜漫漫,还有那么一撮人凌晨之前又开始在糗百上活跃了。关键是凌晨两三点怎么还有人不瞌睡,难道是和我们不在同一个时区的国际友人?从周末的数据看来白天活跃度持续很高,如果抓取下工作日的数据,其分布应该是反过来的,待好事者验证。
没有显示第二列contents,没有发现问题,一旦显示出第二列,立马发现亘古不变的老问题--中文乱码。好在有tmcn包,直接调用toUTF8方法就可以正常显示了,然后来对第二列contents进行一点简单的文本分析。
data<-transform(data,hour=as.integer(substr(data[,1],12,13)))
qplot(factor(hour),data=data,geom='bar')数据为周六抓取,看来我等屌丝们都比较懒,9点钟、10点钟才爬起来,直到晚上7点钟,才稍有消停。而且,长夜漫漫,还有那么一撮人凌晨之前又开始在糗百上活跃了。关键是凌晨两三点怎么还有人不瞌睡,难道是和我们不在同一个时区的国际友人?从周末的数据看来白天活跃度持续很高,如果抓取下工作日的数据,其分布应该是反过来的,待好事者验证。
没有显示第二列contents,没有发现问题,一旦显示出第二列,立马发现亘古不变的老问题--中文乱码。好在有tmcn包,直接调用toUTF8方法就可以正常显示了,然后来对第二列contents进行一点简单的文本分析。
library(tmcn)
words<-data[,2]
words<-toUTF8(words)
require(Rwordseg)
wordsList<-segmentCN(words)#输入为向量,返回结果为list
word<-table(unlist(wordsList))#统计词频
word<-sort(v,decreasing=T)#根据词频由高到低排序
wordFreq<-data.frame(w=names(word),f=word)#根据table构建dataframe
wordFreq$w<-as.character(wordFreq$w)#将单词列由因子转换为字符串
wordFreq$len<-nchar(wordFreq$w)#添加一列作为单词长度的计数
nrow(wordFreq)#看看共有多少个词
[1] 9530
wordFreq<-subset(wordFreq,len>1)#去掉长度为1的‘的’,‘了’等停词
nrow(wordFreq)
[1] 7450
wordFreq<-subset(wordFreq,f>1)#再去掉词频为1,只出现过一次的单词
nrow(wordFreq)
[1] 3468
head(wordFreq)
w f len
一个 一个 466 2
知道 知道 301 2
今天 今天 285 2
什么 什么 270 2
然后 然后 260 2
怎么 怎么 260 2</span>install.packages('wordcloud',repos='http://cran.r-project.org/')
library(wordcloud)
wordFreq<-subset(wordFreq,f>30)#只绘制频率大于30的高频词,否则词云太密集
wordcloud(wordFreq$w,wordFreq$f,color=rainbow(length(wordFreq$w)))

看来大部分糗事都是“今天”“看到”的,关于“老公”和“老婆”的,呵呵,貌似效果不太好,得不出有益的知识,入门之作,纯属练手,权且抛砖引玉,博君一笑。















 1057
1057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









