







XPath抽取网页数据
XML
是什么
- 可扩展标记语言
- 用来传输和存储数据
用途
- XHTML
- 用于描述可用的web服务的WSDL
- 作为手持设备的标记语言的WAP和WML
- 用于新闻feed的RSS语言
- 描述资本和本体的RDF和OWL
- 用于描述针对web的多媒体的SMIL
语法规则
-
所有XML元素都必须有关闭标签
-
XML标签对大小写敏感
-
XML必须正确地嵌套
-
XML文档必须有根元素
-
XML的属性必须加引号
-
实体引用(实体引用的分号和字母间没有空格)
- < < 小于
- > > 大于
- & & 和
- ' ’ 单引号
- " " 引号
-
XML中的注释与HTML相似
<!-- -->
-
在XML中,空格会被保留
-
XML以LF存储换行
元素
XML 元素指的是从(且包括)开始标签直到(且包括)结束标签的部分。
一个元素可以有一个(其他元素、文本、属性)或多个(其他元素、文本、属性)。
XML标签命名规则
- 可包含字母、数字和符号
- 不能以数字或者标点符号开始
- 不能以一切xml字样(大小写)开始
- 不能包含空格
XML属性
- 提供元素的额外信息
- 属性值必须加引号
- 如果属性值中有双引号必须用单引号包裹
- 也可以用实体引用
XPath
概念
xpath是一种查询语言,也称XML路径语言,能够在XML和HTML中寻找节点,确定某部分在文档中的位置。
- Xpath是一门在XML文档中查找信息的语言
- xpath是XSLT中的主要元素
- xquery和xpointer均构建于xpath表达式之上
节点
节点有七种类型:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点
基本值
没有父节点或子节点的节点
项目
项目是基本值或者节点
节点关系
父节点
每个元素以及属性都有一个父节点
子节点
每个元素可以有不定个数的子节点
兄弟节点
拥有相同的父节点
先辈节点
某节点的父节点、父节点的父节点……
后代节点
某节点的子节点、子节点的子节点……
在python下的安装
Ubuntu
sudo apt-get install python-lxml
windows
安装方法多样
pycharm直接搜索安装
cmd中pip install lxml
本地安装,在https://pypi.org/search/网页搜索lxml,下载后缀为whl的文件,cmd中执行pip install xxx.whl
xpath语法
nodename 选取此节点 (第一个节点)的所有节点
/ 从根节点选取
// 跳过多个标签选取
. 选取当前节点
.. 选取当前节点的父节点
@ 选取属性
* 匹配任何元素
@* 匹配任何属性节点
node() 匹配任何类型的节点
xpath谓语
谓语用来查找某个特定区域的节点或者包含某个指定的值的节点。
/node[1] 选取第一个node
/node[last()] 选取最后一个node
/node[last()-1] 选取倒数第二个node
/node[position() < 3] 选取最前面的两个node
//title[@lang] 选取标签是title,带有属性lang的节点
//title[@lang=‘eng’] 选取标签是title,带有属性lang,且其值为eng的节点
xpath运算符
| 计算两个节点集
+ 加法
- 减法
* 乘法
div 除法
= 等于
!= 不等于
< 小于
<= 小于等于
> 大于
>= 大于等于
or 或
and 与
mod 取余
xpath功能函数
starts-with //nodename[starts-with(@str1,str2)] 选取节点的str1属性以str2开头的节点
contains //nodename[contains(@str1,str2) ] 选取str1属性是以str2开头的节点
text() //div[@id = ‘str’]/text() 选取文本内容
xpath案例
爬取糗事百科https://www.qiushibaike.com/8hr/page/的标题
准备
-
python已经安装lxml
导入lxml不出错,表明已经安装成功

-
浏览器中安装一个xpath插件
浏览器扩展中心安装,并查看说明,找到快捷键
网页样式
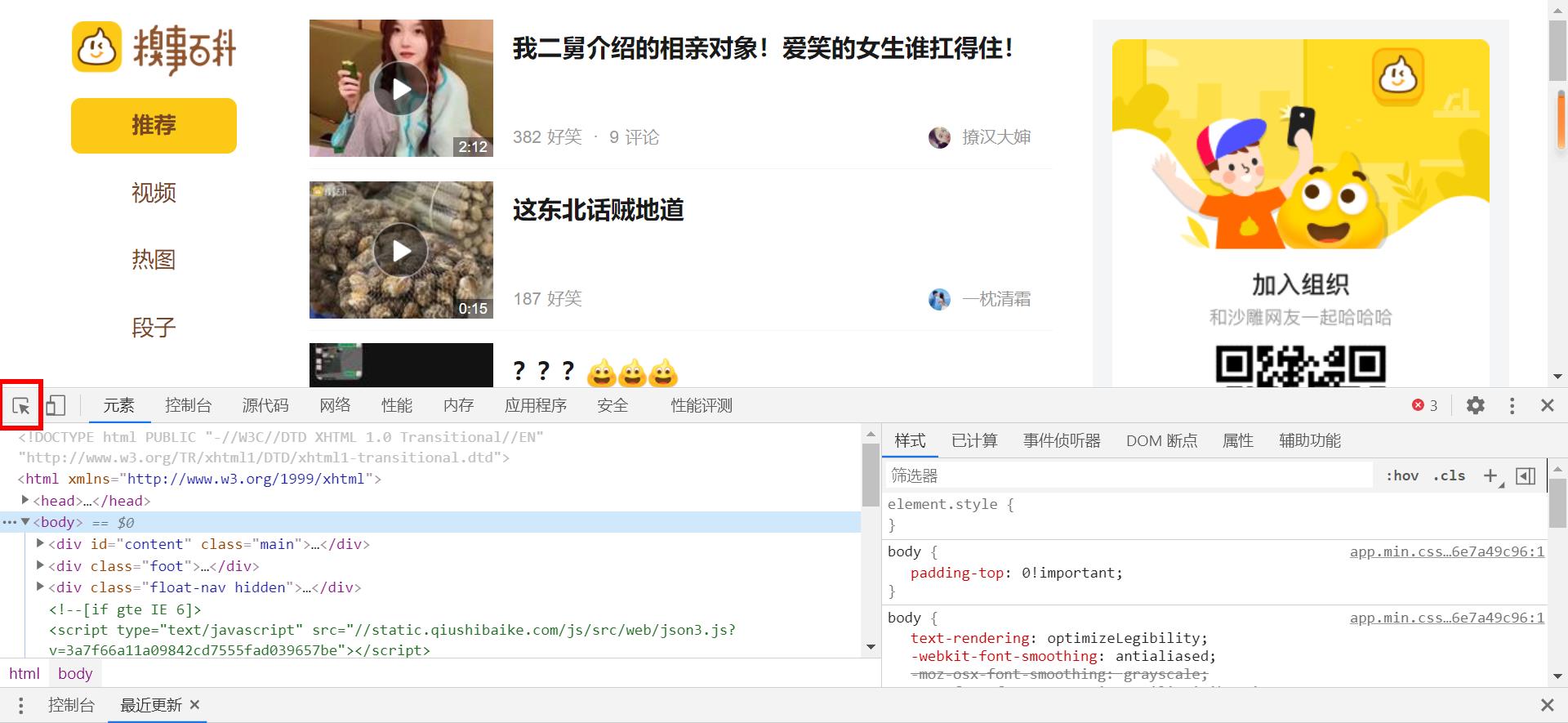
分析网页源码
F12打开开发者模式,点击 “在页面中选择一个元素已进行检查功能”或者Ctrl+Shift+C开启此功能。
指针移到标题位置,并点击。
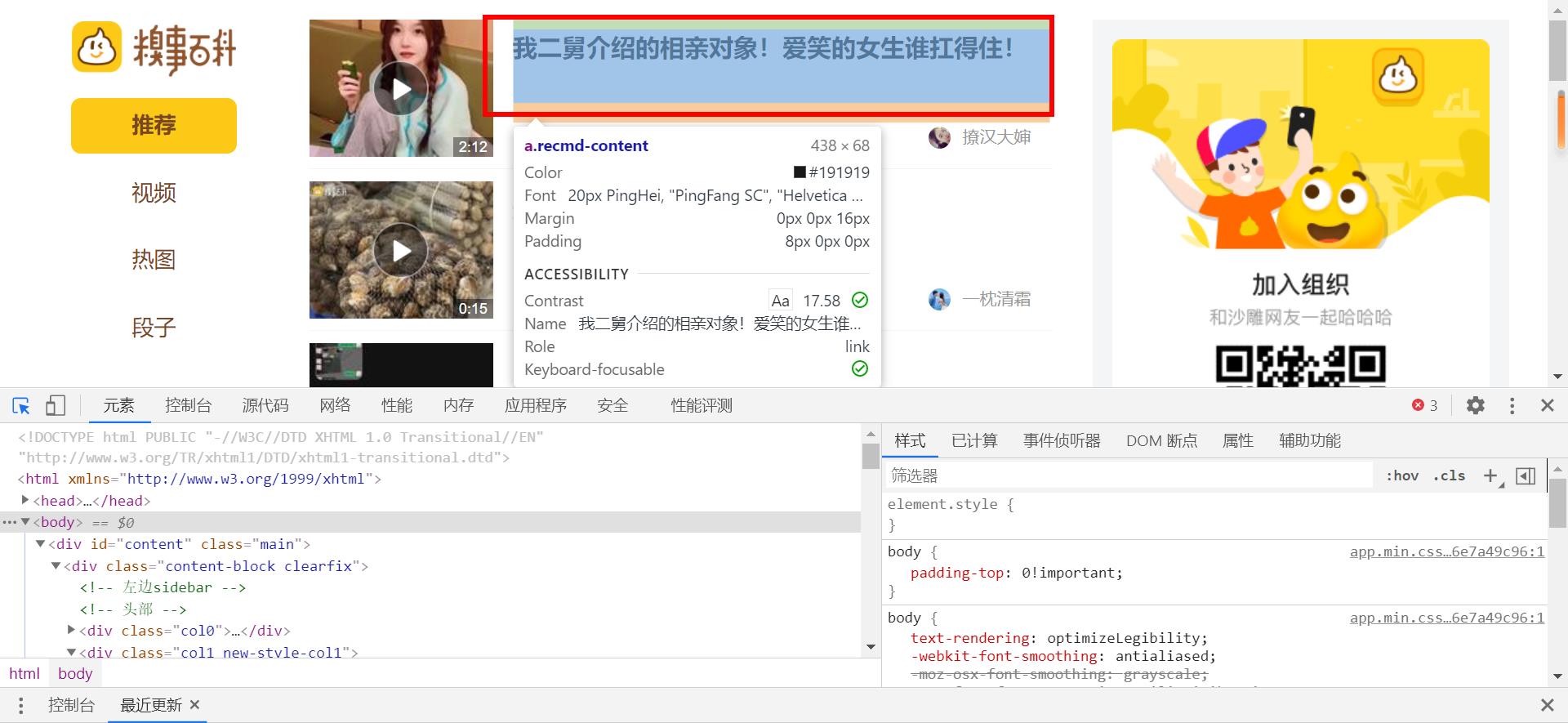
开发者模式的元素以跳到该文本所在的位置。
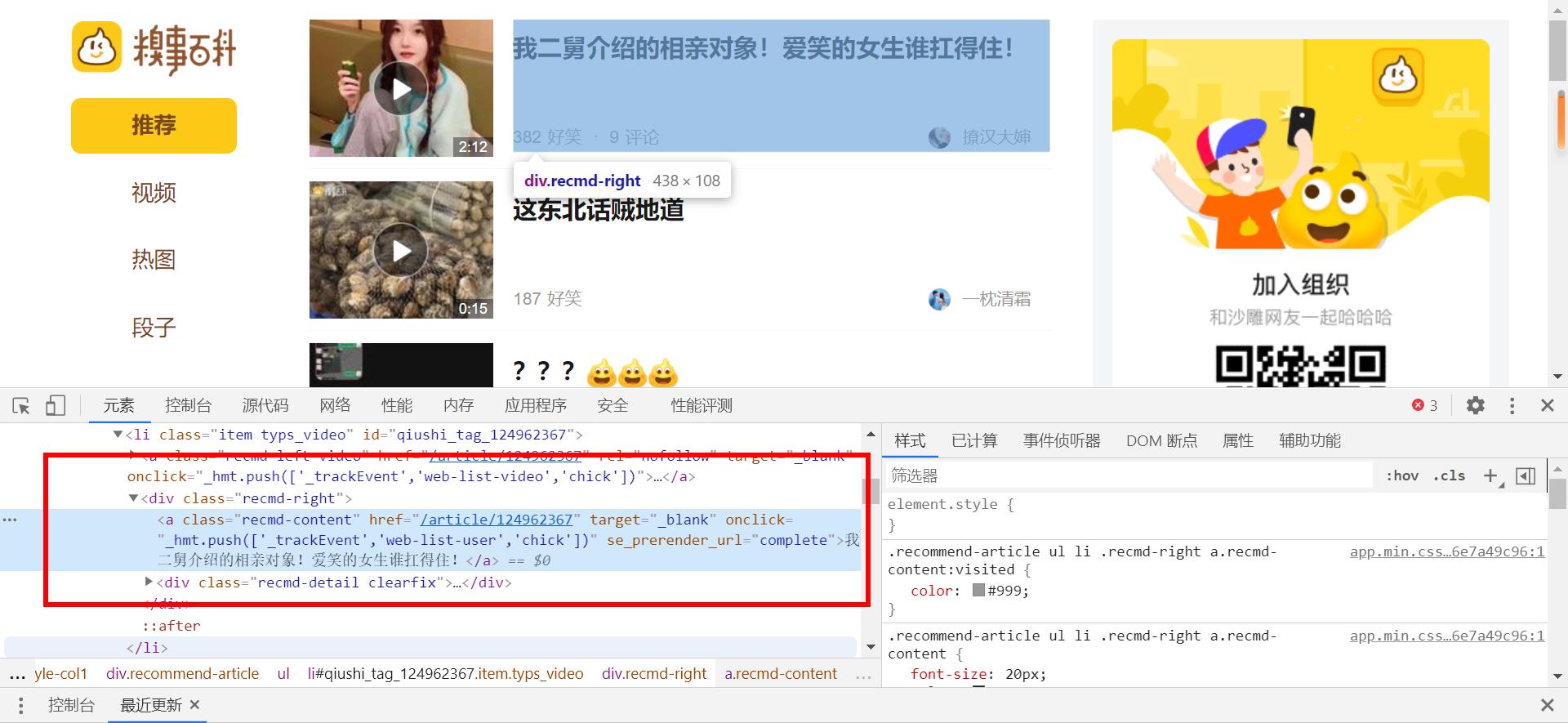
依次叠起标签可发现所有标题在li标签中的一个a标签里。
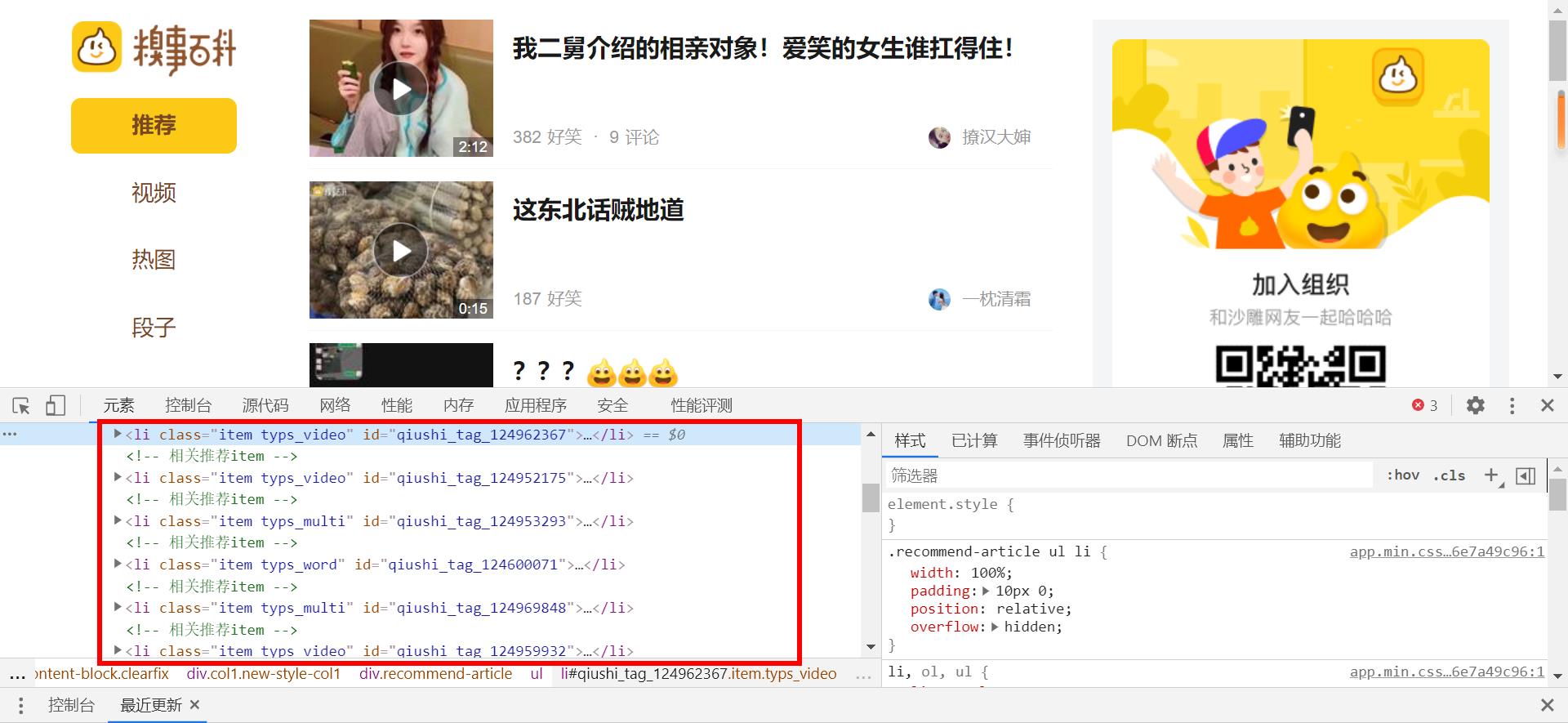
打开浏览器中的xpath插件
编写xpath匹配规则,不断尝试,找到一个匹配规则。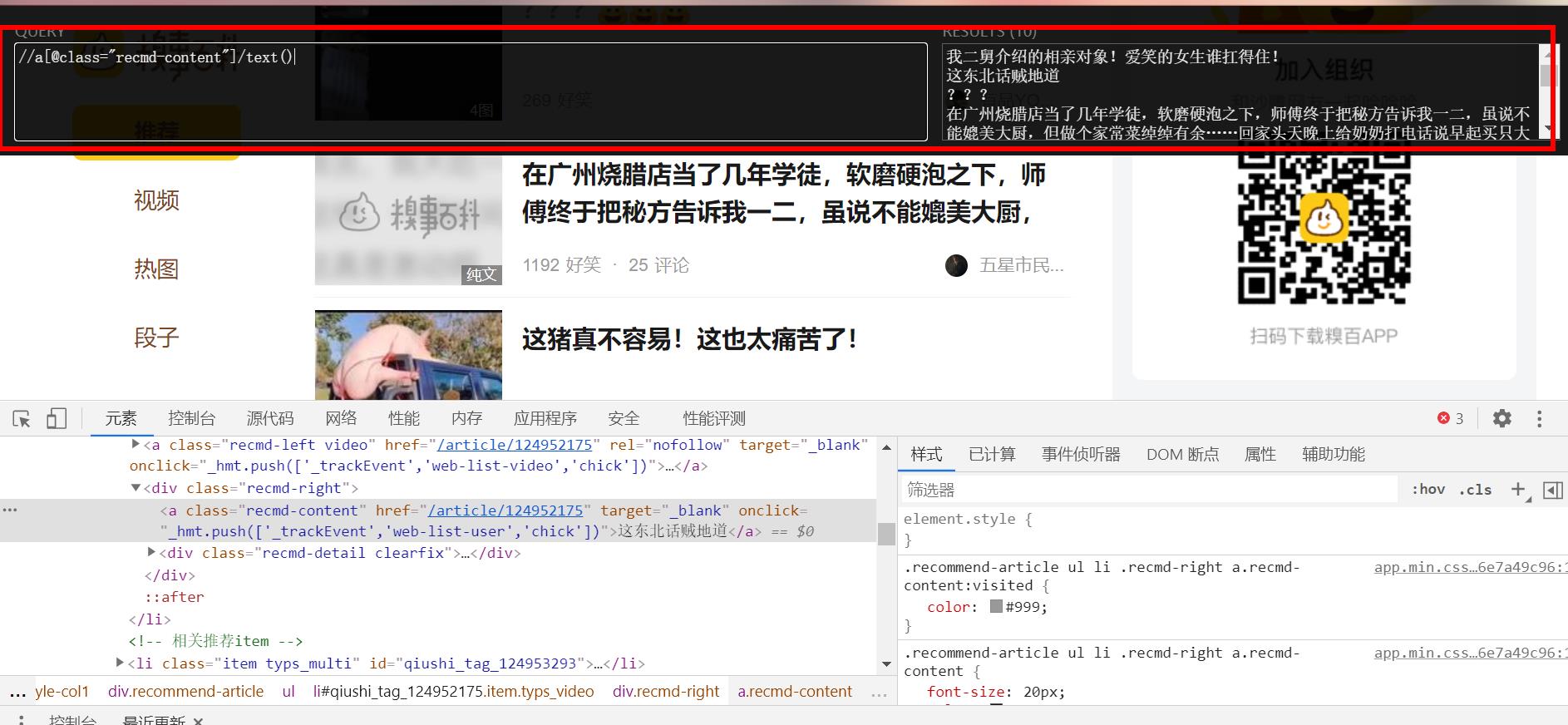
编写python程序
xpath_html = etree.HTML(str(li))
title = xpath_html.xpath("//a[@class='recmd-content']/text()")
值得注意的是,xpath在lxml中的etree包中。
匹配结果是个列表,遍历列表打印并输出到文件。
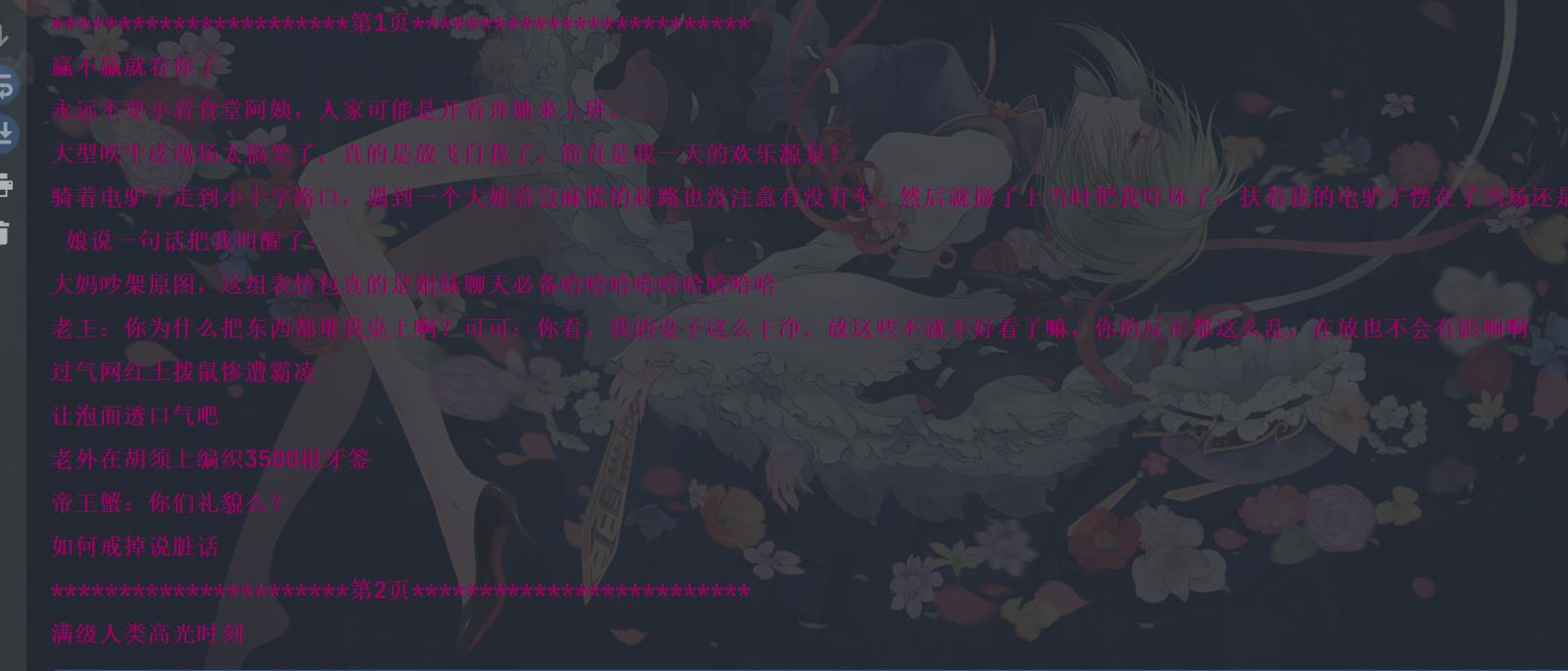















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











