







目标
首先说下目标:Spider 以下可以链接到的所有百科文本。
地址:https://wiki.mbalib.com/wiki/MBA%E6%99%BA%E5%BA%93%E7%99%BE%E7%A7%91:%E5%88%86%E7%B1%BB%E7%B4%A2%E5%BC%95
一些初始化
由于使用类,所以要进行一些初始化:
def __init__(self):
self.wikiURL = 'https://wiki.mbalib.com'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/51.0.2704.63 Safari/537.36'}
self.hadGone = {
} # 用来保存已经爬取过的网页
从主页面开始说起
简单分析
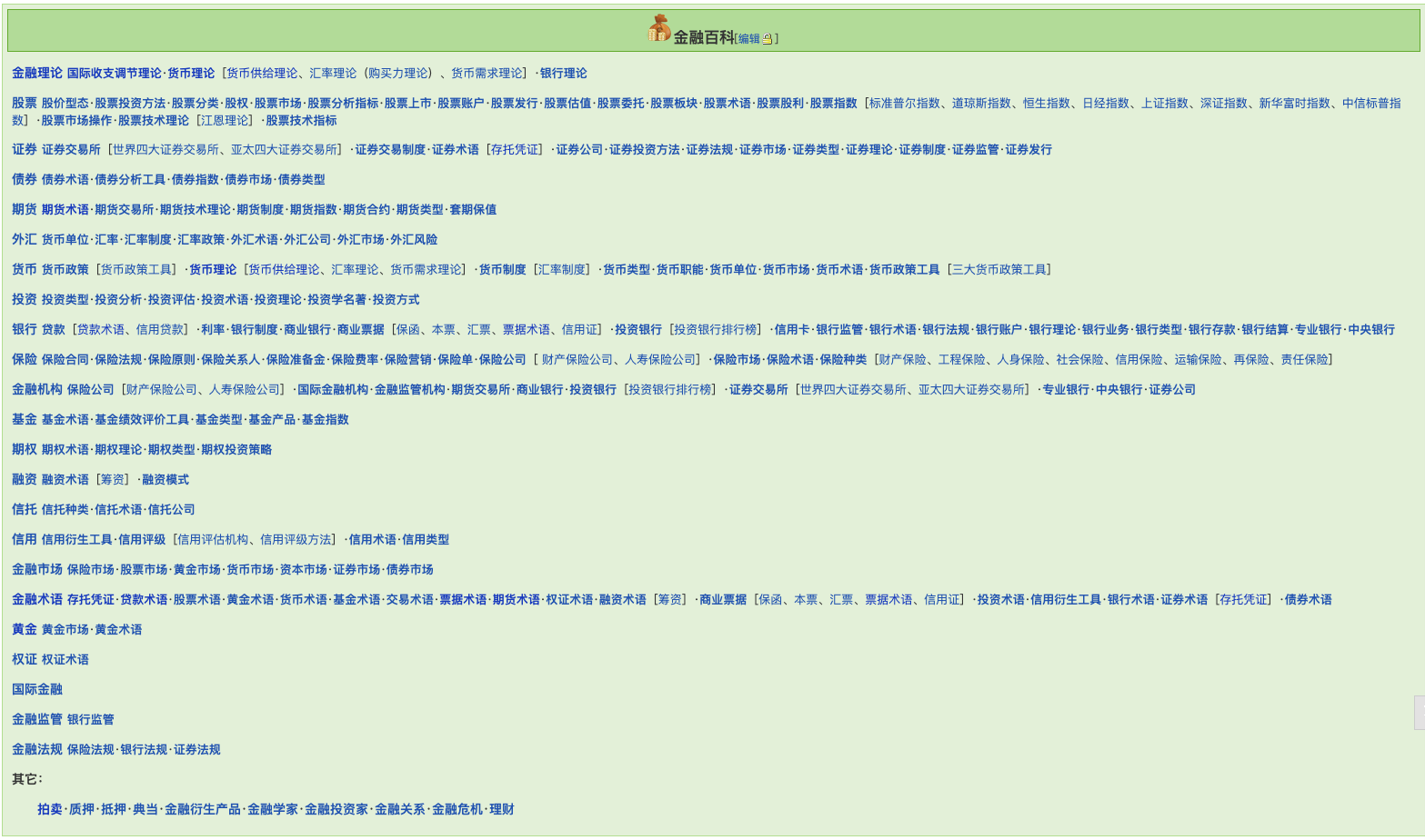
首先需要明确一点:该页面下可能存在许多重复的网页。
为了防止漏爬,我们选择遍历所有索引;同时,为了提高效率和防止重复爬取,使用一个集合来存储已经爬过的 url,劲儿保证每次遍历的都是未曾经走过的网页。
例如:对于“金融理论”下的网页而言,存在以下四种子类(见下图),因此该随后的“国际收支调节理论”,“货币理论”,“银行理论”等网页无需重复爬取。

网页格式
在该网页内使用开发者模式,观察其格式:

注意到,索引界面都是用<p>表示的,我们可以一路 next 到底了。
现在,我们的任务是:将“金融百科”目录下的所有 href 属性爬取下来,并以列表的形式存储。

获取 href
吐槽:MBA中总共有 6 大类,竟然用style标签来区分。
代码:
def get_home_html(self): # 用来爬取首页所需的索引
url = "https://wiki.mbalib.com/wiki/MBA%E6%99%BA%E5%BA%93%E7%99%BE%E7%A7%91:%E5%88%86%E7%B1%BB%E7%B4%A2%E5%BC%95#.E9.87.91.E8.9E.8D.E7.99.BE.E7.A7.91"
r = requests.get(url, headers=self.headers)
soup = BeautifulSoup(r.text, 'lxml') # 第二个参数是解析器,不知道为什么,此处不能使用'html.parser'
# 为直观一点,多写了点 find
indexs = soup.find("div", id="globalWrapper") \
.find("div", id="column-content") \
.find("div", id="content") \
.find("div", id="bodyContent") \
.find("div", style="margin:10px 5px;border:1px solid #B2DE90;background-color:#E3F0D8;padding:5px") \
.find("div", style="padding:0 5px;") \
.find_all('a')
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 75万+
75万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









