






solr和ElasticSearch差不多,是一个索引服务器,也可以看做是nosql。
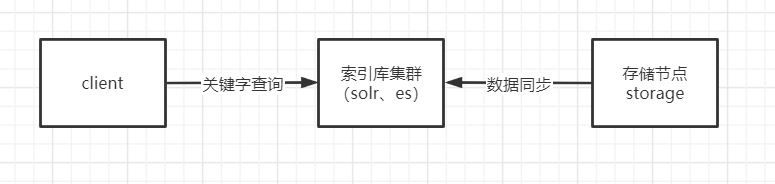
mysql 5.6之后为INNODB存储引擎提供了全文索引,如果有大量的相似度查询,那么压力还是会在sql服务器上。因此可以采用索引库的方式,将mysql中的数据某一些数据同步到索引库上,客户端直接访问索引库,这样就可以减轻sql服务器的压力了。结构图如下:
一、安装solr
jdk 1.8、tomcat
wget http://archive.apache.org/dist/lucene/solr/4.10.4/solr-4.10.4.tgz
tar -zxvf solr-4.10.4.tgz
# solr-core:独立提供搜索服务的单位(相当于mysql中的一张表),在一个solr-home(相当于database)中可以有多个solr-core,数据库中的数据需要同步给某一个具体的solr-core
# solr-4.10.4/dist/ 包含了一个连通tomcat和solr-home的可运行war包,通过页面的方式查看solr的情况
# /solr-4.10.4/example/solr/:是一个标准的solr-home,包含了一个solr-core

cp -r /solr-4.10.4/example/solr /usr/local/solr-home # 将solr-home放到自定义目录中
cp /solr-4.10.4/dist/solr-4.10.4.war /usr/local/tomcat/webapps/ # 将war包放到tomcat对应目录下
启动tomcat # 自动解压war包
cd /usr/local/tomcat/webapps/
mv solr-4.10.4 solr # 重命名文件,通过http://192.168.206.135:8080/solr访问
添加监控日志:
cd /usr/local/tomcat/webapps/solr/WEB-INF
mkdir classes # 存放配置文件的目录
cp /solr-4.10.4/example/lib/ext/* /usr/local/tomcat/webapps/solr/WEB-INF/lib/ # 将对应的jar包放在项目中
cp /solr-4.10.4/example/resources/log4j.properties /usr/local/tomcat/webapps/solr/WEB-INF/classes/ # 在项目中放对应的配置文件
加载solr-home:
vim /usr/local/tomcat/webapps/solr/WEB-INF/web.xml
<env-entry> # 41行
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>/usr/local/solr-home/</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
重启tomcat
访问: http://192.168.206.135:8080/solr/
对应的solr-core如下图:

添加分词器:
这个版本的solr提供的分词器对中文不敏感。我这里采用了IK分词器:
git clone https://gitee.com/wltea/IK-Analyzer-2012FF.git
cp /IK-Analyzer-2012FF/dist/IKAnalyzer2012FF_u1.jar /usr/local/tomcat/webapps/solr/WEB-INF/lib/ # 分词器的jar包放在项目路径中
cp /IK-Analyzer-2012FF/dist/IKAnalyzer.cfg.xml stopword.dic /usr/local/tomcat/webapps/solr/WEB-INF/classes/ # 配置文件,xxx.dic表示词典,用户可以通过修改IKAnalyzer.cfg.xml配置自定义词典,词典放在 WEB-INF/classes/

在solr-core中使用IK分词器:
vim /usr/local/solr-home/collection1/conf/schema.xml
# 在文件末尾添加分词器的配置
<fieldType name="text_ik" class="solr.TextField"> # name可以自定义,分词器名称
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
重启tomcat

自定义域:(将mysql上的数据和solr做一个映射)
# 没有必要将mysql中某张表的数据完全映射到solr中,但是没有必要完全映射。
# 以JD商品搜索为例,页面只显示了图片,价格,商品描述等一部分基础的信息,并没有将所有的信息都显示,如果想要查看物品的详细信息还需要点击商品的链接(这可以对应一个查看商品详情的服务),使用solr做的搜索对应一个所搜服务,只需要返回部分的字段就可以了。
vim /usr/local/solr-home/collection1/conf/schema.xml 【添加到文件最后】
# name:自定义字段名,type:指定分词器,indexed:是否可以按照这个字段搜索,stored:存储,这一部分是搜索的时候返回的字段
<field name="goods_name" type="text_ik" indexed="true" stored="true" />
<field name="goods_price" type="int" indexed="true" stored="true" />
<field name="goods_sale_point" type="text_ik" indexed="true" stored="true" />
<field name="goods_img" type="string" indexed="false" stored="true" />
# 目标域(组合域) multiValue:符合字段,会按照目标域进行搜索。相当于(or)
<field name="goods_keywords" type="text_ik" indexed="true" stored="true" multiValued="true"/>
# 将自定义域放在目标域中
<copyField source="goods_name" dest="goods_keywords"/>
<copyField source="goods_sale_point" dest="goods_keywords"/>

二、springboot链接solr
相关依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-solr</artifactId>
</dependency>
配置文件application.yml
spring:
data:
solr:
host: http://192.168.206.135:8080/solr # 单机版solr配置
代码实现增删改查:
注入:(可以使用@Autowired)
@Resource
private SolrClient solrClient;
1、增:(只要id号存在就变成了修改操作)
@org.junit.Test
public void addTest() throws Exception{
// solr里面的操作记录 -- 也就是一条数据
SolrInputDocument document = new SolrInputDocument();
// 自定义域--要和和服务器配置文件对应
document.setField("id", "1001"); // id在服务器的配置文件中不需要配置。但插入数据的时候需要写。
// 如果id存在则执行修改操作
document.setField("goods_name", "林俊杰演唱会门票,前排");
document.setField("goods_price", "5999");
document.setField("goods_sale_point", "90后的回忆");
document.setField("goods_img", "暂无");
// 提交
solrClient.add(document);
solrClient.commit();
}
2、删:
@org.junit.Test
public void deleteTest() throws Exception{
solrClient.deleteById("100"); // id是精确匹配
solrClient.deleteByQuery("goods_name:林俊杰"); // 分词,匹配,删除
solrClient.commit();
}
3、查:
@org.junit.Test
public void queryTest() throws Exception{
// 查询条件
SolrQuery condition = new SolrQuery();
// condition.setQuery("*:*"); // 查询字符串
// condition.setQuery("goods_name:林俊杰周杰伦");
// condition.setQuery("goods_name:林俊杰");
condition.setQuery("goods_keywords:前排");
// 执行查询, 会将查询字符串进行分词,然后进行匹配查找
QueryResponse response = solrClient.query(condition);
// 查询结果
SolrDocumentList results = response.getResults();
for (SolrDocument document : results){
System.out.println(document.get("id") + ", " +
document.get("goods_name") + ", " +
document.get("goods_sale_point"));
}
}
目前也就学到了这么多,关于mysql向solr中同步数据,我也没有具体去找这个,有比较好办法的请大家留言一下哈。
参考:
架构风清扬














 489
489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









