






目录
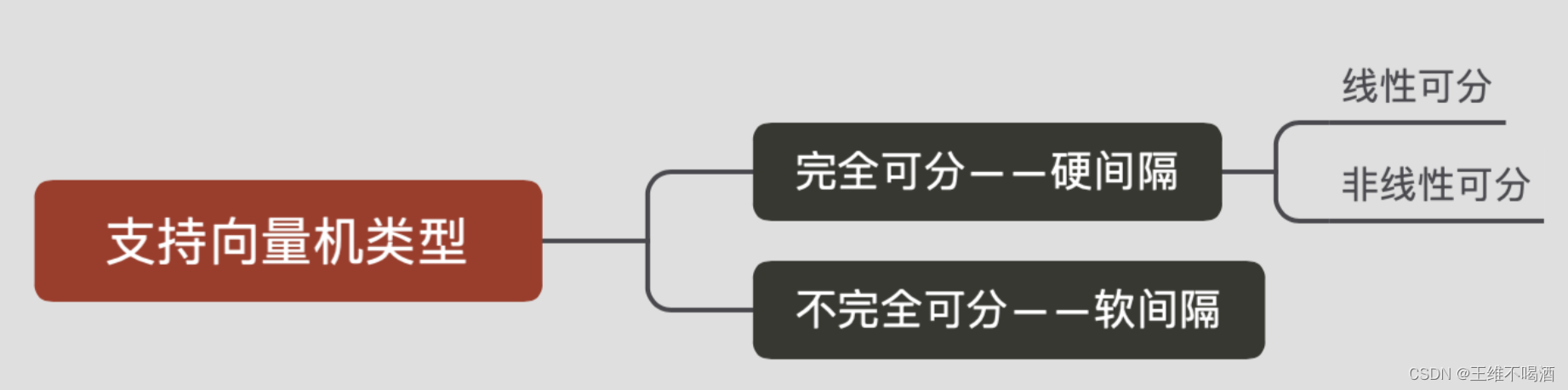
1.支持向量机简介
支持向量机(Support Vector Machine,SVM)是一种二分类模型,SVM可以用于线性和非线性分类问题,回归以及异常值检测。其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。支持向量机的学习算法是求解凸二次规划的最优化算法。
其基本原理是通过在特征空间中找到一个超平面,将不同类别的样本分开,并且使得离超平面最近的样本点到超平面的距离最大化。
1.1 支持向量机的类别

- 分割超平面:将上述数据集分隔开来的直线成为分隔超平面。对于二维平面来说,分隔超平面就是一条直线。对于三维及三维以上的数据来说,分隔数据的是个平面,称为超平面,也就是分类的决策边界。
- 间隔:点到分割面的距离,称为点相对于分割面的间隔。数据集所有点到分隔面的最小间隔的2倍,称为分类器或数据集的间隔。论文中提到的间隔多指这个间隔。SVM分类器就是要找最大的数据集间隔。
- 支持向量:离分隔超平面最近的那些点。
1.2 最大间隔

我们假设平面上任意一点x的很坐标是,纵坐标是
,则此点的类别是1 或 -1:
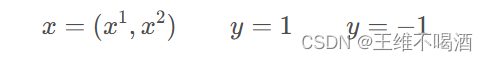
此时,超平面方程:
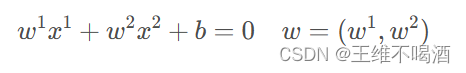
因为需要保证直线两边的点到此超平面的距离最大,所以我们需要计算点x xx到超平面的距离d :
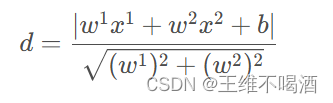
观察上式中的分子,如果分子的绝对值里面是正数,说明类别为1;如果分子的绝对值里面是负数,说明类别为-1。所以我们可以把绝对值拿开,用y来代替:
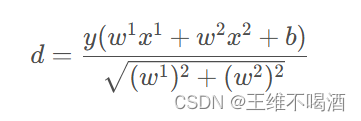
所以点到直线的距离d dd就可以更新为:

1.3 核函数
核函数是支持向量机(SVM)中一个核心的概念,它使得SVM能够有效地处理非线性可分的数据
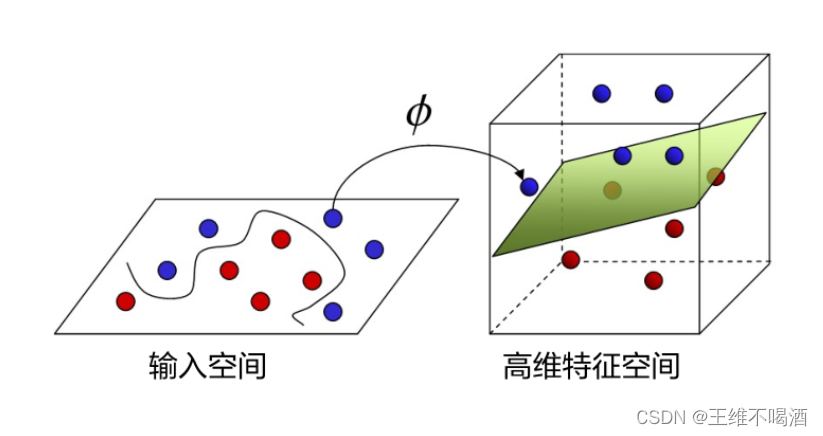
将样本从原始空间映射到一个更高维的特征空间, 使得样本在这个特征空间内线性可分
核函数的基本定义:核函数可以定义为一个函数,它接受两个低维空间中的向量作为输入,并返回它们在高维特征空间中的内积。这种方法避免了直接在高维空间中操作,因为那会涉及到复杂的运算和高计算成本。通过这种方式,数据可以在高维空间中变得线性可分,从而使用线性算法进行处理。
核函数的工作原理:通过将原始数据映射到更高维的空间中,数据点在这个新的空间中可以被线性超平面分隔。这种映射使得原本在低维空间中线性不可分的问题,在高维空间中变得线性可分。核函数通过计算数据的点积来实现这一点,而无需显式地构造高维空间中的数据表示,这称为“核技巧”。
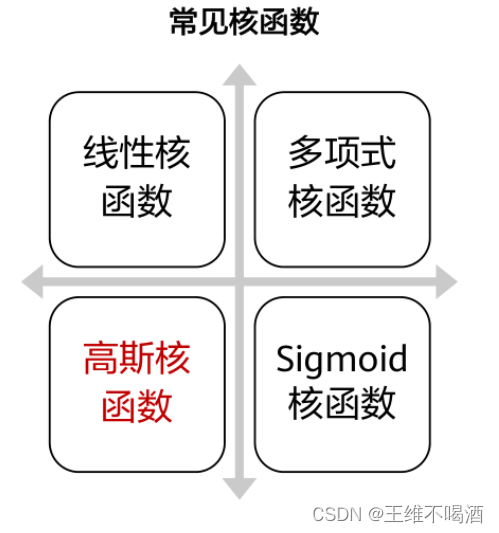
常用的核函数类型:线性核函数主要用于原始特征空间本身即是线性可分的场景。多项式核函数可以将数据映射到一个更高阶的多项式空间,使数据在新的空间中线性可分。高斯核函数,也称为径向基函数(RBF),其特点是可以将数据映射到无限维的空间,提供强大的灵活性和泛化能力。此外,还有其他如Sigmoid核、拉普拉斯核等,每种核函数都有其特定的应用场景和优势。
1.4 实验步骤
2 代码实现
线性支持向量机
2.1 导入所需库
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
2.2 生成线性可分数据
X, y = datasets.make_classification(n_features=2, n_redundant=0, n_informative=2, random_state=1, n_clusters_per_class=1)
2.3 划分数据集
使用`datasets.make_classification`函数生成了一个包含两个特征的线性可分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=1)
2.4 数据标准化
将数据集分为训练集和测试集,测试集的大小为40%,随机状态设置为1以确保可复现性。
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
2.5 创建SVM分类器实例
创建了一个`StandardScaler`对象,并使用它来标准化训练集和测试集的数据。标准化是为了确保权重不会因为特征的大小而偏袒某些特征
svm = SVC(kernel='linear', C=1.0, random_state=0)
2.6 训练SVM分类器
创建了一个SVM分类器实例,其中`kernel='linear'`指定了使用线性核函数,`C=1.0`是正则化参数,`random_state=0`确保了随机性的可复现性。
svm.fit(X_train, y_train)
2.7 预测测试集
使用训练集来训练SVM分类器
y_pred = svm.predict(X_test)
2.8 可视化
使用训练好的SVM分类器来预测测试集的标签
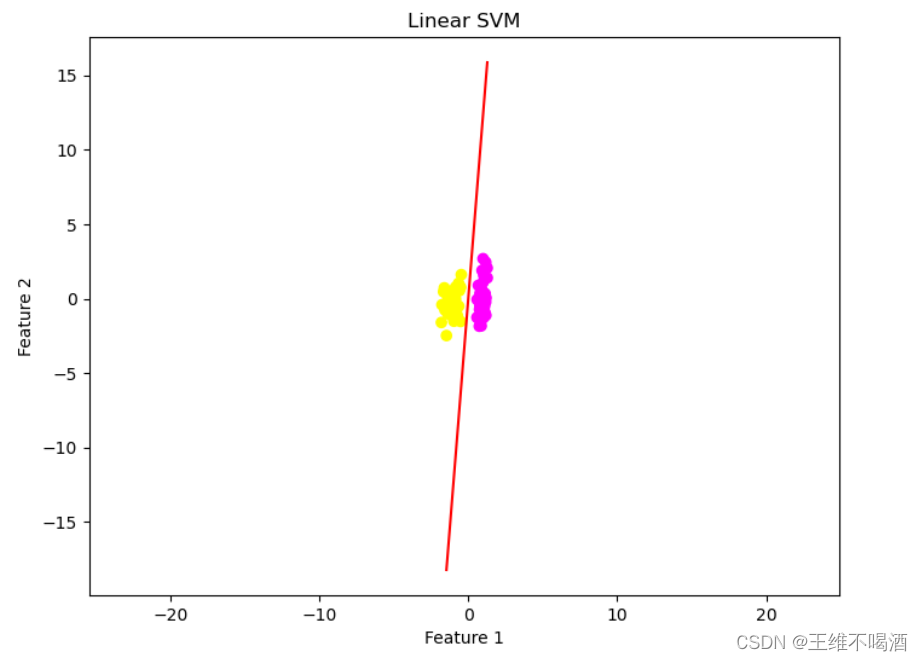
plt.figure(figsize=(8, 6))
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap='spring')
plt.scatter(X_test[:, 0], X_test[:, 1],2.9 可视化结果
3 总结
线性支持向量机(SVM)的优缺点:
优点:
1. **理论支持**:线性SVM是基于严格的数学理论的,特别是在处理线性可分数据时,它能够找到一个最优的线性分隔超平面。
2. **计算效率**:当数据集线性可分时,线性SVM的计算效率相对较高,因为其优化问题可以通过解析方法求解。
3. **易于理解**:线性模型通常更易于解释,因为它们的决策边界是线性的,这使得人们更容易理解模型是如何工作的。
缺点:
1. **数据限制**:线性SVM依赖于数据的线性可分性,这在现实世界的数据集中并不常见,导致其适用性受限。
2. **性能限制**:线性模型在处理复杂数据时性能可能不如非线性模型,因为它们不能捕捉数据的非线性关系。
3. **参数调整**:线性SVM的性能很大程度上依赖于正则化参数C的选择,这需要通过交叉验证来优化。
非线性支持向量机(SVM)的优缺点:
优点:
1. **适应性**:非线性SVM通过使用核技巧可以适应非线性数据,允许模型在更高维的特征空间中找到非线性决策边界。
2. **泛化能力**:非线性SVM通常具有较好的泛化能力,因为它们能够捕捉数据中的复杂模式。
3. **灵活性**:非线性SVM提供了多种核函数选择,如线性核、多项式核和径向基函数(RBF)核,可以根据数据的特点选择合适的核函数。
缺点:
1. **计算复杂性**:非线性SVM的训练和预测通常比线性SVM更复杂,因为它们涉及到了高维空间的优化问题,这可能导致更长的训练时间和更高的计算成本。
2. **过拟合风险**:非线性SVM在处理大量数据时可能会遇到过拟合问题,特别是在特征空间维度非常高的情况下。
3. **参数调整**:非线性SVM的参数选择,包括核函数类型和参数、正则化参数C等,通常更加复杂,需要通过交叉验证来优化。















 1331
1331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









