







一、定义
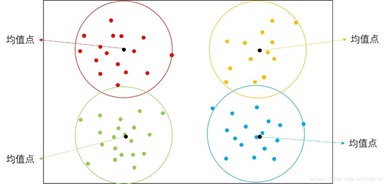
首先简单介绍一些K-Means的原理:字面上,K即原始数据最终被聚为K类或分为K类,Means即均值点。K-Means的核心就是将一堆数据聚集为K个簇,每个簇中都有一个中心点称为均值点,簇中所有点到该簇的均值点的距离都较到其他簇的均值点更近。如下图是一个K=4的聚类示意图,每个点都是到自己所在的簇的均值点更近,而这个均值点可以是原始数据中的点,也可以是一个不存在的点,即不属于原始数据集中的点。
K-Means的算法流程下图所示,这里使用的是周志华教授《机器学习》一书中的插图。用文字描述为:
1、首先确定K值(即你想把数据聚为几类,K值是K-Means算法中唯一的参数);
2、从原始数据集中随机选择K个点作为初始均值点(步骤1和2为准备工作);
3、依次从原始数据集中取出数据,每取出一个数据就和K个均值点分别计算距离(默认计算点间的欧氏距离),和谁更近就归为这个均值点所在的簇;
4、当步骤3结束后,分别计算各簇当前的均值点(即求该簇中所有点的平均值);
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









