







Lucane-基础
Lucene是apache软件基金会发布的一个开放源代码的全文检索引擎工具包,由资深全文检索专家Doug Cutting所撰写,它是一个全文检索引擎的架构,
提供了完整的创建索引和查询索引,以及部分文本分析的引擎,Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便在目标系统中实现
全文检索的功能,或者是以此为基础建立起完整的全文检索引擎,Lucene在全文检索领域是一个经典的祖先,现在很多检索引擎都是在其基础上创建的,
思想是相通的。Lucece不能用在互联网搜索(即像百度那样),只能用在网站内部的文本搜索(即只能在CRM,RAX,ERP等内部使用),但思想是相通的。
即:Lucene是根据关健字来搜索的文本搜索工具,只能在某个网站内部搜索文本内容,不能跨网站搜索
Lucene相关jar包可到官网下载。
以3.0.2版为例,一般在工程中会使用到以下jar包:
lucene-core-3.0.2.jar【Lucene核心】
lucene-analyzers-3.0.2.jar【分词器】
lucene-highlighter-3.0.2.jar【Lucene会将搜索出来的字,高亮显示,提示用户】
lucene-memory-3.0.2.jar【索引库优化策略】
Luncane索引库
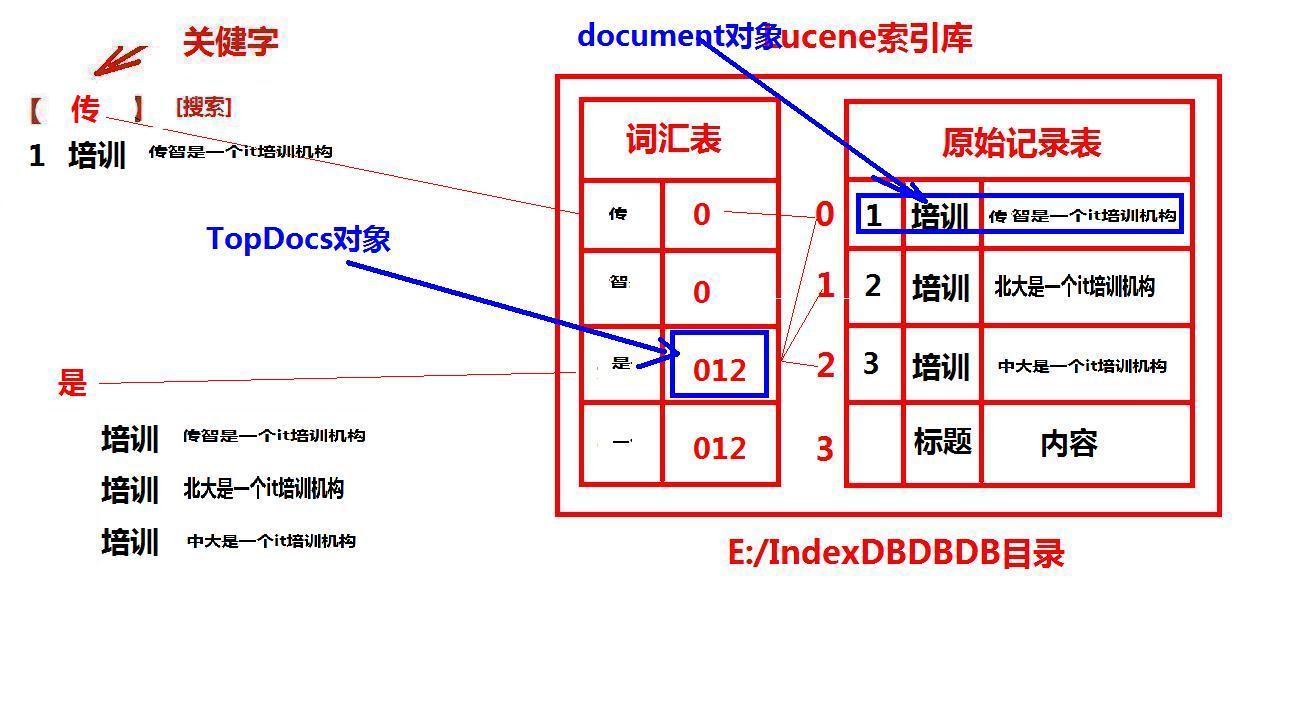
我们从Lucene中搜索数据, 那么数据放在哪呢? -> 就放在索引库中
索引库中存着一系列的二进制压缩文件和一些控制文件,它们位于计算机的硬盘上。
索引库有两部分组成:
原始记录 :存入到索引库中的原始文本。Lucene为存入的内容分配一个唯一的编号例如:传智是一家IT培训机构
词汇表:存放的是经过分词器拆分出来的词汇和该词汇在原始记录表中的编号
分词器:即采用什么策略将被搜索的数据拆分,供用户搜索。
Lucene的简单使用
Lucene的使用主要包括两个部分:
1)向索引库中存入数据(创建索引库)
2)在索引库中搜索数据
创建索引库
从上面的叙述可以看出, 索引库在实际中的体现,即是一个目录,而这个目录下存放在供搜索的数据。
1) 这里, 我们将这个目录看做索引库
Directory directory = FSDirectory.open(new File("E:/IndexDBDBDB")); 2)索引库中包含原始记录表和词汇表, 这两张表可以说是体现在一个.cfs文件中, 而这个文件是怎么产生的呢?
a, 当我们向索引库中写入一个Document对象时(依赖IndexWriter对象),会自动产生这个.cfs文件,
这个文件中包含原始记录表,和词汇表
b, 对于原始记录表和词汇表中的内容,这些内容来自于Document对象。
我们将我们要被搜索的数据封装在Document对象中。
但被搜索的数据在放入document对象中时,应使用Javabean对象封装。
以上用一个图来解释:
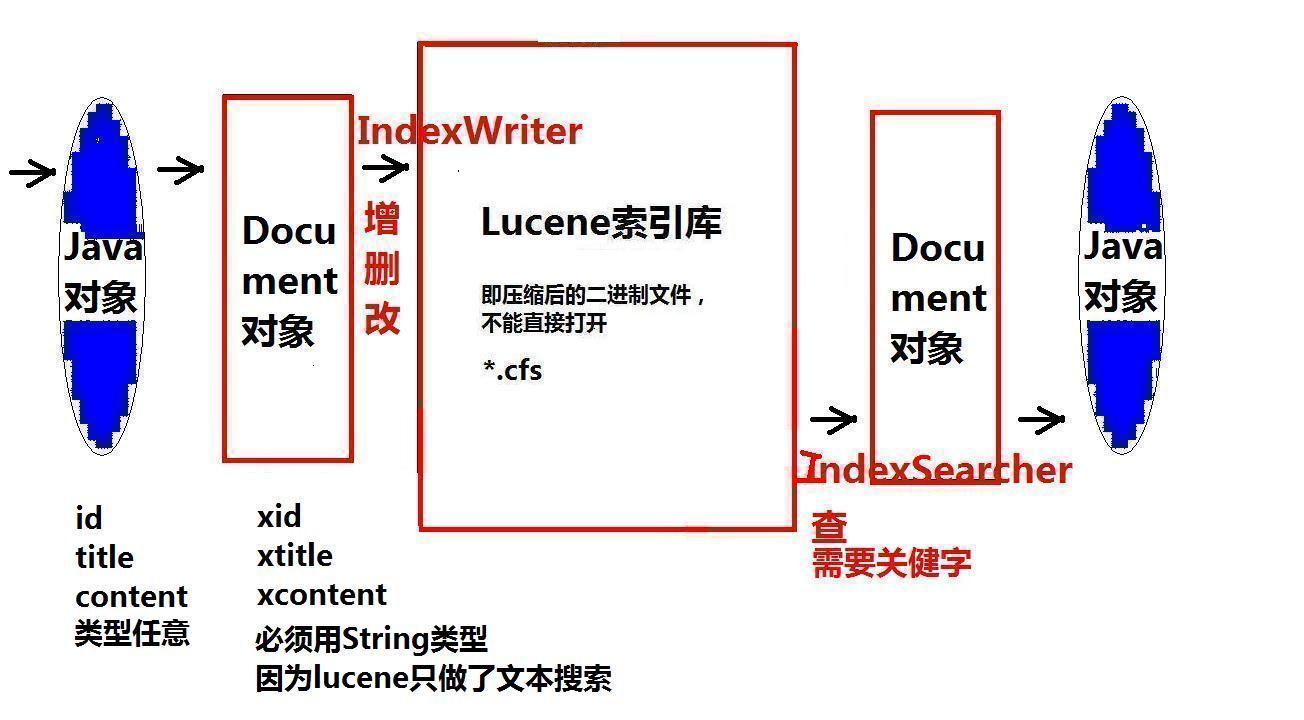
即向索引中存数据,就是创建索引库的过程
看一下代码的具体实现:
//用以封装被搜索的数据的javabean
public class Article {
private Integer id;//标题
private String title;//标题
private String content;//内容
}
public void createIndexDB() throws Exception{
//创建Article对象, 封装数据的对
Article article = new Article(1,"培训","传智是一家IT培训机构");
//创建Document对象
Document document = new Document();
//将Article对象中的三个属性值分别绑定到Document对象中
/*
*参数一:document对象中的属性名叫xid,article对象中的属性名叫id,项目中提倡相同
*参数二:document对象中的属性xid的值,与article对象中相同
*参数三:是否将xid属性值存入由原始记录表中转存入词汇表
* Store.YES表示该属性值会存入词汇表
* Store.NO表示该属性值不会存入词汇表
* 项目中提倡非id值都存入词汇表
*参数四:是否将xid属性值进行分词算法
* Index.ANALYZED表示该属性值会进行词汇拆分
* Index.NOT_ANALYZED表示该属性值不会进行词汇拆分
* 项目中提倡非id值都进行词汇拆分
*/
document.add(new Field("xid",article.getId().toString(),Store.YES,Index.ANALYZED));
document.add(new Field("xtitle",article.getTitle(),Store.YES,Index.ANALYZED));
document.add(new Field("xcontent",article.getContent(),Store.YES,Index.ANALYZED));
//创建IndexWriter字符流对象
/*
* 参数一:lucene索引库最终应对于硬盘中的目录,例如:E:/IndexDBDBDB
* 参数二:采用什么策略将文本拆分,一个策略就是一个具体的实现类
* 参数三:最多将文本拆分出多少词汇,LIMITED表示1W个,即只取前1W个词汇,如果不足1W个词汇个,以实际为准
*/
Directory directory = FSDirectory.open(new File("E:/IndexDBDBDB"));
Version version = Version.LUCENE_30; //一般去最新的版本
Analyzer analyzer = new StandardAnalyzer(version);
MaxFieldLength maxFieldLength = MaxFieldLength.LIMITED;
IndexWriter indexWriter = new IndexWriter(directory,analyzer,maxFieldLength);
//将document对象写入lucene索引库
indexWriter.addDocument(document);
//关闭IndexWriter字符流对象
indexWriter.close();
}从索引库中搜索数据
看下图:
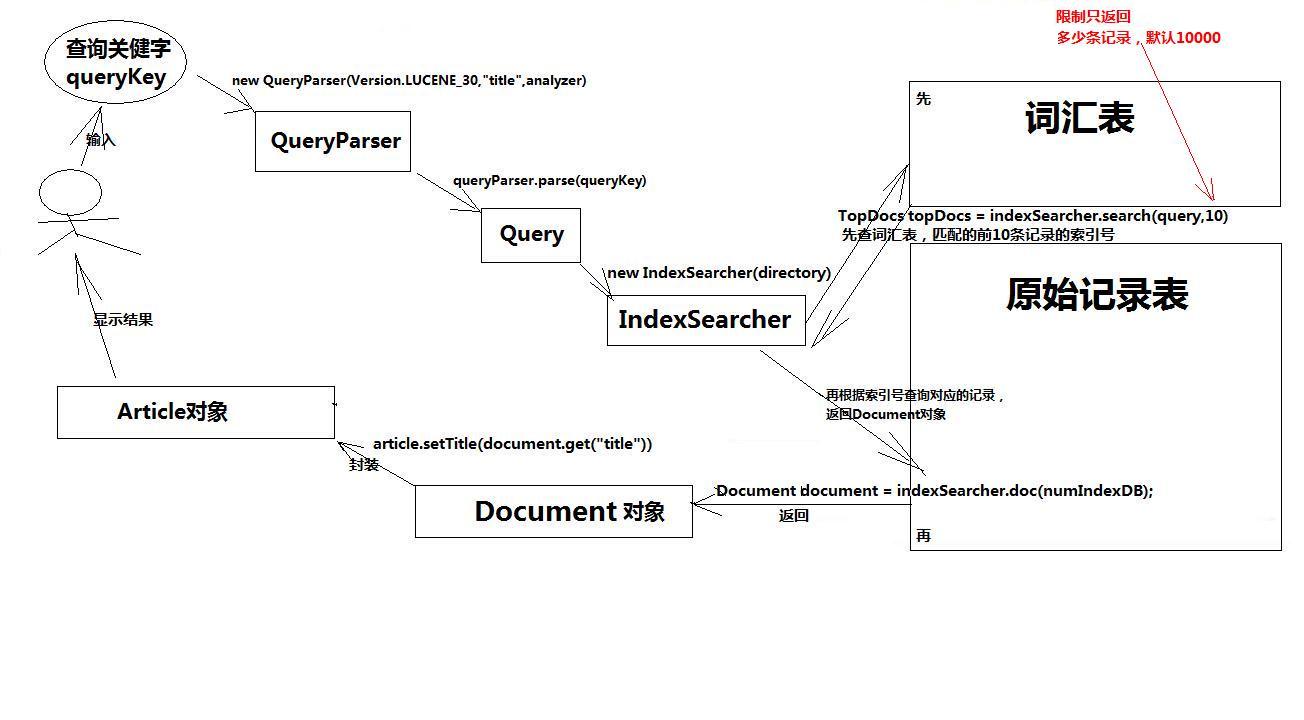
从图中可以看出,在索引库中搜索数据与插入是一个相反的过程。依赖IndexSeracher对象。
代码实现:
public void findIndexDB() throws Exception{
//准备工作
String keywords = "培训";
List<Article> articleList = new ArrayList<Article>();
Directory directory = FSDirectory.open(new File("E:/IndexDBDBDB"));
Version version = Version.LUCENE_30;
Analyzer analyzer = new StandardAnalyzer(version); //分词器
//创建IndexSearcher字符流对象
IndexSearcher indexSearcher = new IndexSearcher(directory);
//创建查询解析器对象
/*
* 参数一:使用分词器的版本,提倡使用该jar包中的最高版本
* 参数二:针对document对象中的哪个属性进行搜索
*/
QueryParser queryParser = new QueryParser(version,"xcontent",analyzer);
//创建对象对象封装查询关键字
Query query = queryParser.parse(keywords);
//根据关键字,去索引库中的词汇表搜索
/*
* 参数一:表示封装关键字查询对象,其它QueryParser表示查询解析器
* 参数二:MAX_RECORD表示如果根据关键字搜索出来的内容较多,只取前MAX_RECORD个内容
* 不足MAX_RECORD个数的话,以实际为准
*/
int MAX_RECORD = 100;
TopDocs topDocs = indexSearcher.search(query,MAX_RECORD);
//迭代词汇表中符合条件的编号
for(int i=0;i<topDocs.scoreDocs.length;i++){
//取出封装编号和分数的ScoreDoc对象
ScoreDoc scoreDoc = topDocs.scoreDocs[i];
//取出每一个编号,例如:0,1,2
int no = scoreDoc.doc;
//根据编号去索引库中的原始记录表中查询对应的document对象
Document document = indexSearcher.doc(no);
//获取document对象中的三个属性值
String xid = document.get("xid");
String xtitle = document.get("xtitle");
String xcontent = document.get("xcontent");
//封装到artilce对象中
Article article = new Article(Integer.parseInt(xid),xtitle,xcontent);
//将article对象加入到list集合中
articleList.add(article);
}
//迭代结果集
for(Article a:articleList){
System.out.println(a);
}
}TopDocs的理解
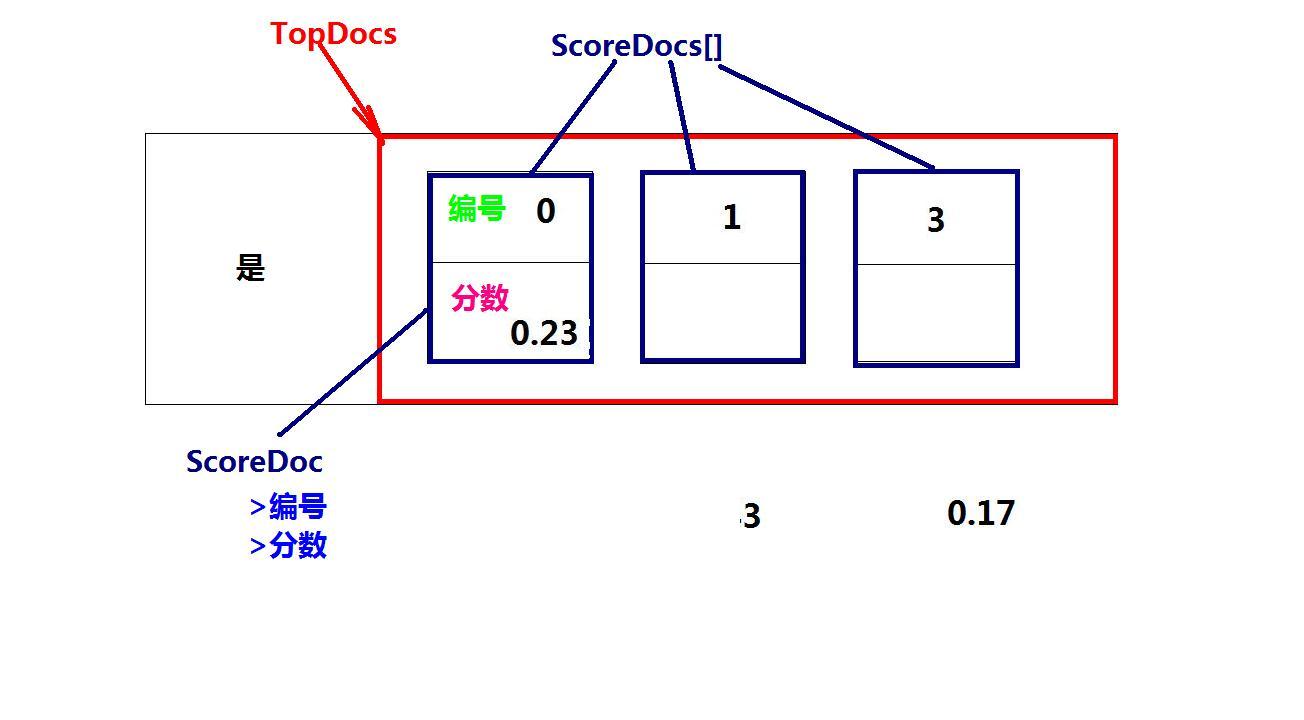
TopDocs的两个组成部分:
ScoreDoc[]:代表从索引库原始记录表中中搜索到的数据的编号的集合, 数组中最多有
indexSearcher.search(query,MAX_RECORD) -> MAX_RECORD个
totalHits:搜索出来的总的数据数量。 不受MAX_RECORD的限制
ScoreDoc的两个组成部分:
doc: 在原始记录表中的编号
score: 编号的代表的记录的关注度(热度),
本文参考自传智博客笔记















 734
734











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









