







//filename: square.cu
// By Seamanj 04/11/2015 @NCCA
#include <stdio.h>
__global__
void square(float * d_out, float * d_in)
{
int idx = threadIdx.x;
float f = d_in[idx];
d_out[idx] = f * f;
}
int main(int argc, char ** argv)
{
const int ARRAY_SIZE = 64;
const int ARRAY_BYTES = ARRAY_SIZE * sizeof(float);
// generate the input array on the host
float h_in[ARRAY_SIZE];
for (int i = 0; i < ARRAY_SIZE; ++i)
{
h_in[i] = float(i);
}
float h_out[ARRAY_SIZE];
// declare GPU memory pointers
float * d_in;
float * d_out;
cudaMalloc((void**) &d_in, ARRAY_BYTES);
cudaMalloc((void**) &d_out, ARRAY_BYTES);
// transfer the array to the GPU
cudaMemcpy(d_in, h_in, ARRAY_BYTES, cudaMemcpyHostToDevice);
// launch the kernel
square<<<1, ARRAY_SIZE>>>(d_out, d_in);
// copy back the result array to the CPU
cudaMemcpy(h_out, d_out, ARRAY_BYTES, cudaMemcpyDeviceToHost);
// copy back the result array to the CPU
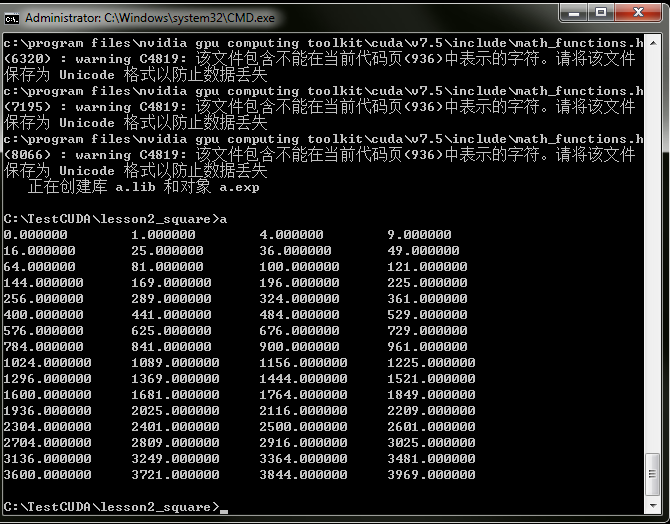
for( int i = 0; i < ARRAY_SIZE; ++i)
{
printf("%f", h_out[i]);
printf(((i % 4) != 3) ? "\t" : "\n");
}
cudaFree(d_in);
cudaFree(d_out);
return 0;
}















 4225
4225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









