







1.分析登陆网址的方式
1.1使用Firefox或者Chrom浏览器F12,以Firefox登陆广工图书馆为例(该网址设计使用Cookie来记录登陆状态)
1.2登陆前
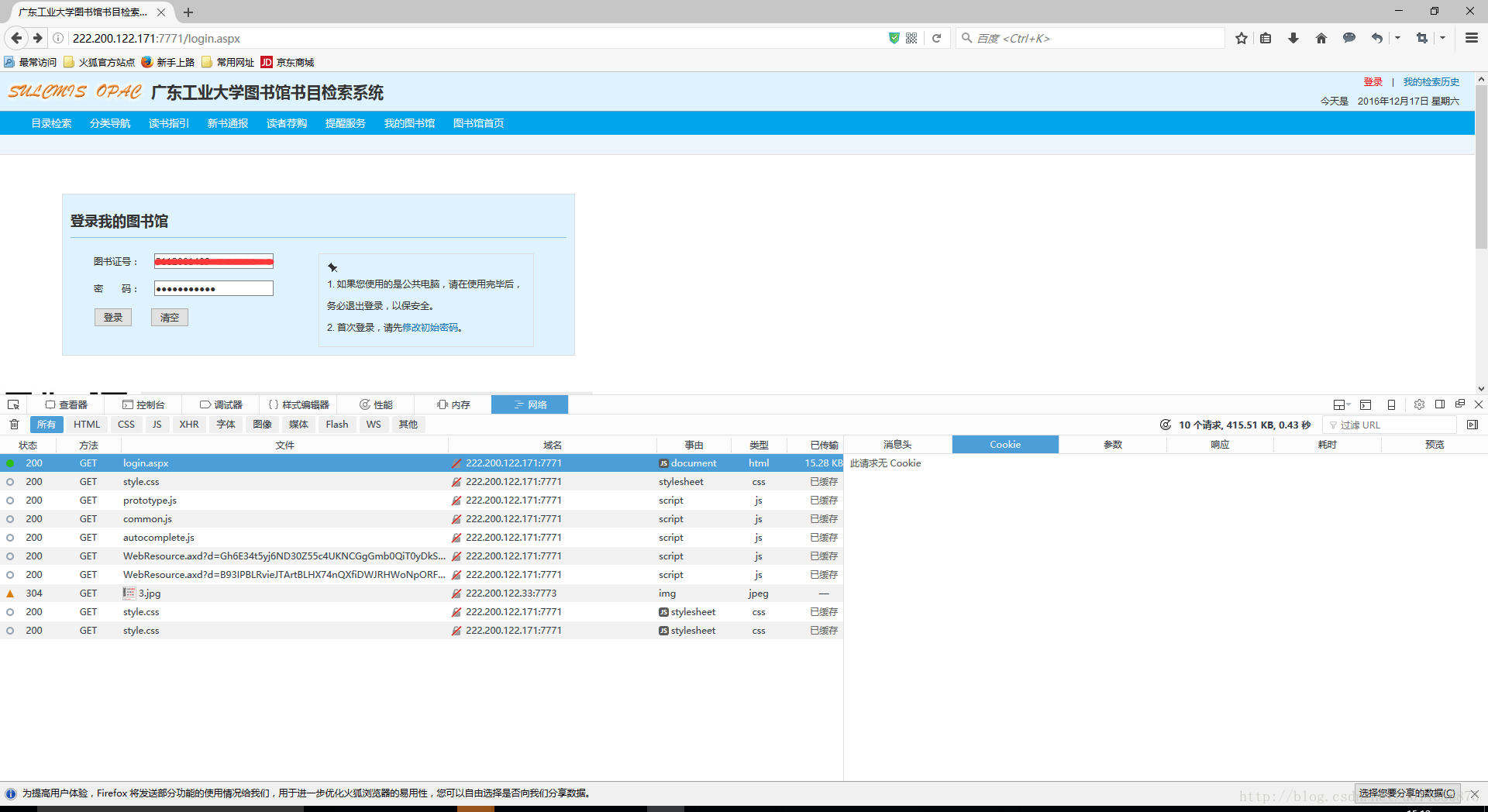
1.3登陆后
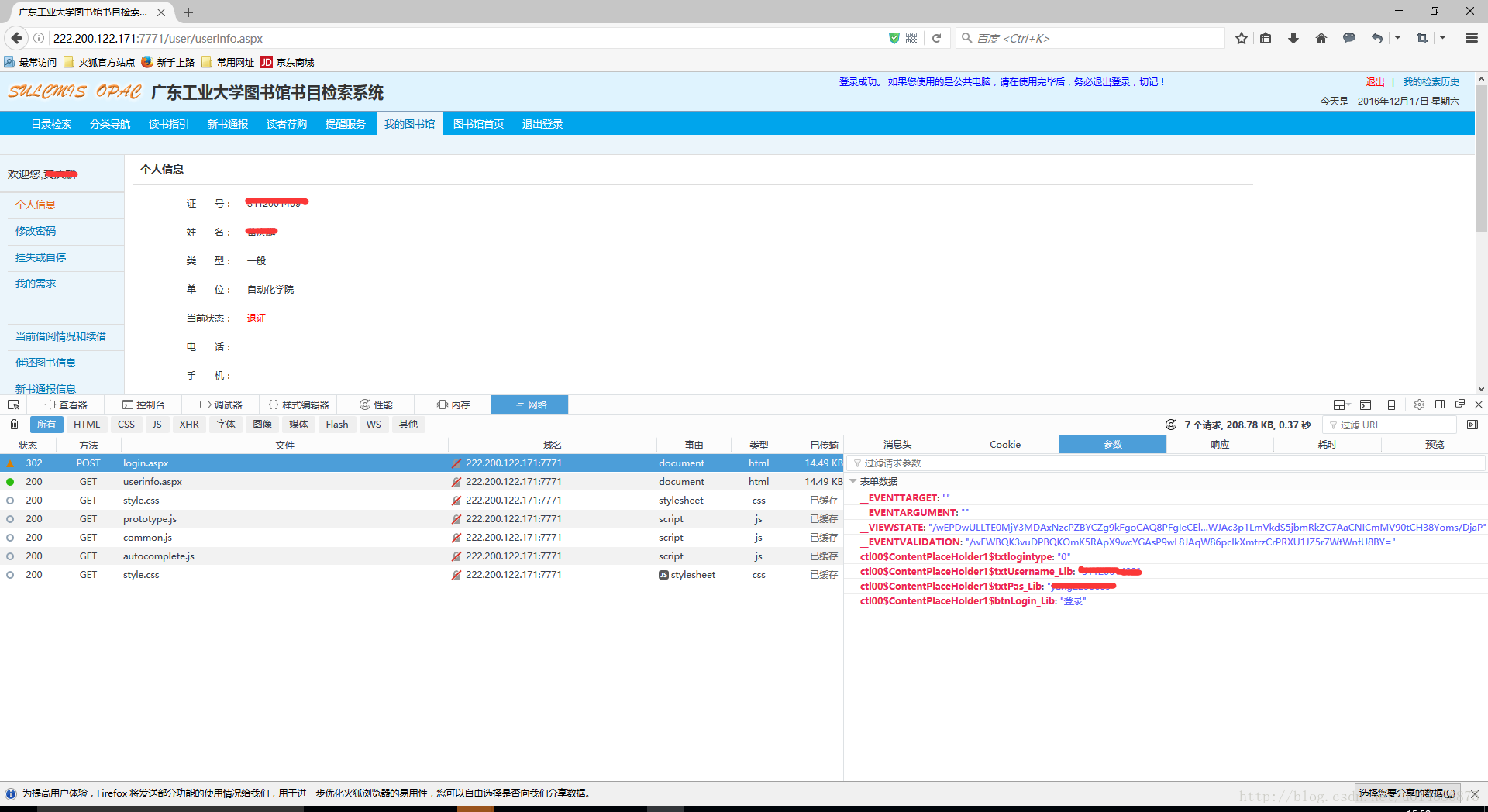
1.4根据登陆后可见POST方法的参数
__EVENTTARGET:
__EVENTARGUMENT:
__VIEWSTATE:/wEPDwULLTE0MjY3MDAxNzcPZBYCZg9kFgoCAQ8PFgIeCEltYWdlVXJsBRt+XGltYWdlc1xoZWFkZXJvcGFjNGdpZi5naWZkZAICDw8WAh4EVGV4dAUt5bm/5Lic5bel5Lia5aSn5a2m5Zu+5Lmm6aaG5Lmm55uu5qOA57Si57O757ufZGQCAw8PFgIfAQUcMjAxNuW5tDEy5pyIMTPml6UgIOaYn+acn+S6jGRkAgQPZBYEZg9kFgQCAQ8WAh4LXyFJdGVtQ291bnQCCBYSAgEPZBYCZg8VAwtzZWFyY2guYXNweAAM55uu5b2V5qOA57SiZAICD2QWAmYPFQMTcGVyaV9uYXZfY2xhc3MuYXNweAAM5YiG57G75a+86IiqZAIDD2QWAmYPFQMOYm9va19yYW5rLmFzcHgADOivu+S5puaMh+W8lWQCBA9kFgJmDxUDCXhzdGIuYXNweAAM5paw5Lmm6YCa5oqlZAIFD2QWAmYPFQMUcmVhZGVycmVjb21tZW5kLmFzcHgADOivu+iAheiNkOi0rWQCBg9kFgJmDxUDE292ZXJkdWVib29rc19mLmFzcHgADOaPkOmGkuacjeWKoWQCBw9kFgJmDxUDEnVzZXIvdXNlcmluZm8uYXNweAAP5oiR55qE5Zu+5Lmm6aaGZAIID2QWAmYPFQMbaHR0cDovL2xpYnJhcnkuZ2R1dC5lZHUuY24vAA/lm77kuabppobpppbpobVkAgkPZBYCAgEPFgIeB1Zpc2libGVoZAIDDxYCHwJmZAIBD2QWBAIDD2QWBAIBDw9kFgIeDGF1dG9jb21wbGV0ZQUDb2ZmZAIHDw8WAh8BZWRkAgUPZBYGAgEPEGRkFgFmZAIDDxBkZBYBZmQCBQ8PZBYCHwQFA29mZmQCBQ8PFgIfAQWlAUNvcHlyaWdodCAmY29weTsyMDA4LTIwMDkuIFNVTENNSVMgT1BBQyA0LjAxIG9mIFNoZW56aGVuIFVuaXZlcnNpdHkgTGlicmFyeS4gIEFsbCByaWdodHMgcmVzZXJ2ZWQuPGJyIC8+54mI5p2D5omA5pyJ77ya5rex5Zyz5aSn5a2m5Zu+5Lmm6aaGIEUtbWFpbDpzenVsaWJAc3p1LmVkdS5jbmRkZAg1DiqmaepeeQ7Rw6kLdb3ah3tb
__EVENTVALIDATION:/wEWBQKNu6LYBwKOmK5RApX9wcYGAsP9wL8JAqW86pcI3FE0WSxHMScWQc3QHyrMix/0xmM=
ctl00$ContentPlaceHolder1$txtlogintype:0
ctl00$ContentPlaceHolder1$txtUsername_Lib:账号
ctl00$ContentPlaceHolder1$txtPas_Lib:密码
ctl00$ContentPlaceHolder1$btnLogin_Lib:登录1.5在登陆前界面(http://222.200.122.171:7771/login.aspx)寻找POST参数,后期使用正则表达式进行筛选
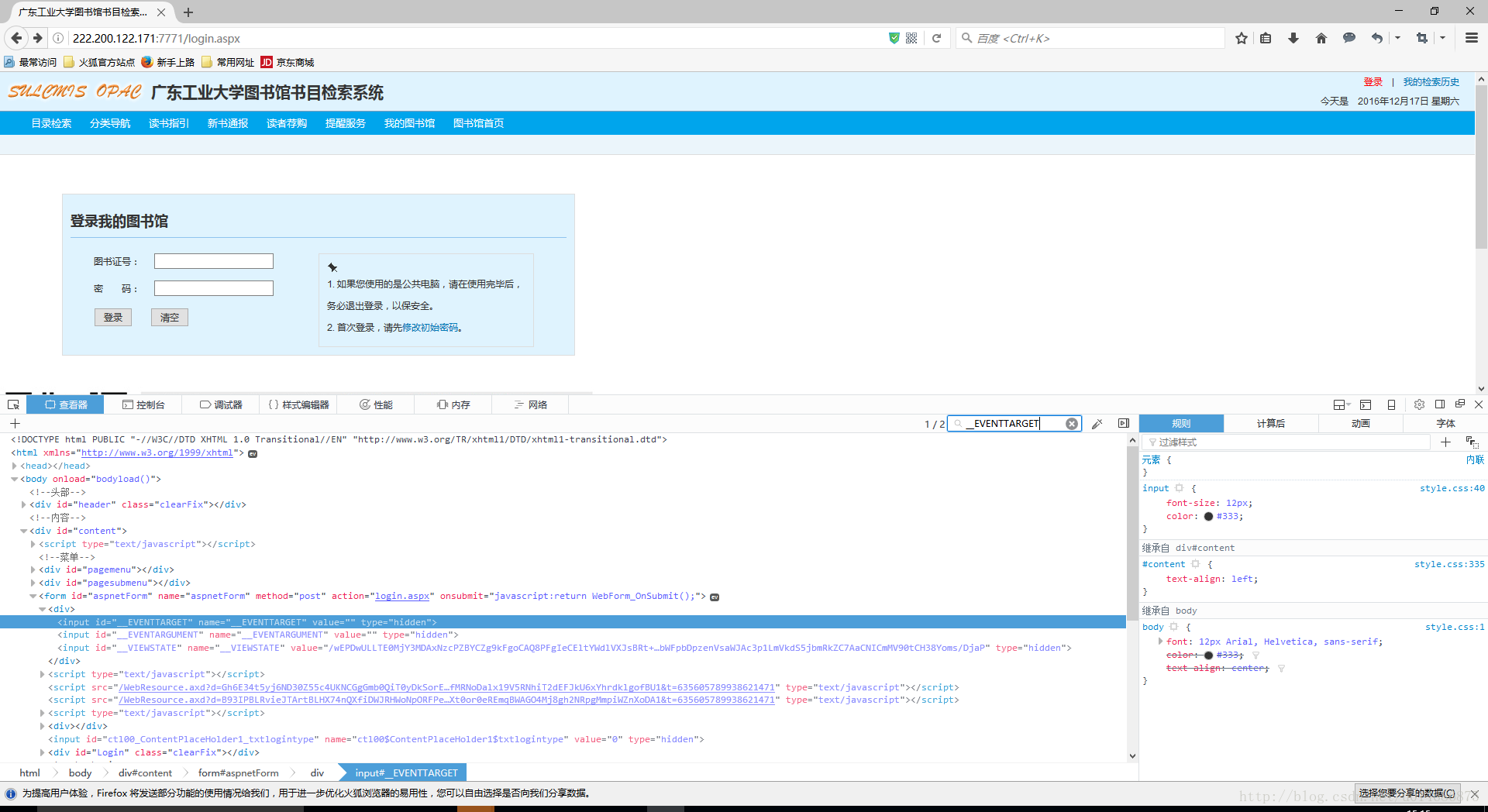
①在登陆界面(http://222.200.122.171:7771/login.aspx)寻找POST参数:
<input name="__EVENTTARGET" id="__EVENTTARGET" value="" type="hidden">
<input name="__EVENTARGUMENT" id="__EVENTARGUMENT" value="" type="hidden">
<input name="__VIEWSTATE" id="__VIEWSTATE" value="/wEPDwULLTE0MjY3MDAxNzcPZBYCZg9kFgoCAQ8PFgIeCEltYWdlVXJsBRt+XGltYWdlc1xoZWFkZXJvcGFjNGdpZi5naWZkZAICDw8WAh4EVGV4dAUt5bm/5Lic5bel5Lia5aSn5a2m5Zu+5Lmm6aaG5Lmm55uu5qOA57Si57O757ufZGQCAw8PFgIfAQUcMjAxNuW5tDEy5pyIMTPml6UgIOaYn+acn+S6jGRkAgQPZBYEZg9kFgQCAQ8WAh4LXyFJdGVtQ291bnQCCBYSAgEPZBYCZg8VAwtzZWFyY2guYXNweAAM55uu5b2V5qOA57SiZAICD2QWAmYPFQMTcGVyaV9uYXZfY2xhc3MuYXNweAAM5YiG57G75a+86IiqZAIDD2QWAmYPFQMOYm9va19yYW5rLmFzcHgADOivu+S5puaMh+W8lWQCBA9kFgJmDxUDCXhzdGIuYXNweAAM5paw5Lmm6YCa5oqlZAIFD2QWAmYPFQMUcmVhZGVycmVjb21tZW5kLmFzcHgADOivu+iAheiNkOi0rWQCBg9kFgJmDxUDE292ZXJkdWVib29rc19mLmFzcHgADOaPkOmGkuacjeWKoWQCBw9kFgJmDxUDEnVzZXIvdXNlcmluZm8uYXNweAAP5oiR55qE5Zu+5Lmm6aaGZAIID2QWAmYPFQMbaHR0cDovL2xpYnJhcnkuZ2R1dC5lZHUuY24vAA/lm77kuabppobpppbpobVkAgkPZBYCAgEPFgIeB1Zpc2libGVoZAIDDxYCHwJmZAIBD2QWBAIDD2QWBAIBDw9kFgIeDGF1dG9jb21wbGV0ZQUDb2ZmZAIHDw8WAh8BZWRkAgUPZBYGAgEPEGRkFgFmZAIDDxBkZBYBZmQCBQ8PZBYCHwQFA29mZmQCBQ8PFgIfAQWlAUNvcHlyaWdodCAmY29weTsyMDA4LTIwMDkuIFNVTENNSVMgT1BBQyA0LjAxIG9mIFNoZW56aGVuIFVuaXZlcnNpdHkgTGlicmFyeS4gIEFsbCByaWdodHMgcmVzZXJ2ZWQuPGJyIC8+54mI5p2D5omA5pyJ77ya5rex5Zyz5aSn5a2m5Zu+5Lmm6aaGIEUtbWFpbDpzenVsaWJAc3p1LmVkdS5jbmRkZAg1DiqmaepeeQ7Rw6kLdb3ah3tb" type="hidden">
<input type="hidden" name="__EVENTVALIDATION" id="__EVENTVALIDATION" value="/wEWBQLL+rWqAwKOmK5RApX9wcYGAsP9wL8JAqW86pcI3+ohGVVAcOzsnECPPKNYB0mRpZ0=">
<input name="ctl00$ContentPlaceHolder1$txtlogintype" type="hidden" id="ctl00_ContentPlaceHolder1_txtlogintype" value="0">
<input name="ctl00$ContentPlaceHolder1$btnLogin_Lib" value="登录" onclick="javascript:WebForm_DoPostBackWithOptions(new WebForm_PostBackOptions("ctl00$ContentPlaceHolder1$btnLogin_Lib", "", true, "", "", false, false))" id="ctl00_ContentPlaceHolder1_btnLogin_Lib" class="btn" type="submit">
②其中:
ctl00$ContentPlaceHolder1$txtUsername_Lib是登陆账号
ctl00$ContentPlaceHolder1$txtPas_Lib是密码2.编写程序
2.1创建myproject的Scrapy工程(参考)
2.2编写\myproject\myproject\spiders\LoginSpider.py
# -*- coding:utf-8 -*-
import scrapy
import re
class LoginSpider(scrapy.Spider):
name = 'login'
start_urls = ['http://222.200.122.171:7771/login.aspx']
def parse(self, response):
print 'befor_login============'
pattern = re.compile(
'id="__EVENTTARGET" value="(.*?)"' +
'.*?' +
'id="__EVENTARGUMENT" value="(.*?)"' +
'.*?' +
'id="__VIEWSTATE" value="(.*?)"' +
'.*?' +
'id="__EVENTVALIDATION" value="(.*?)"'+
'.*?' +
'id="ctl00_ContentPlaceHolder1_txtlogintype" value="(.*?)"' +
'.*?' +
'name="ctl00\$ContentPlaceHolder1\$btnLogin_Lib" value="(.*?)"'
,re.S)
items = re.findall(pattern,response.body.decode(response.encoding))
print ("lin len: %d"%(len(items)))
for item in items:
print ("lin __EVENTTARGET: %s" %(item[0]))
print ("lin __EVENTARGUMENT: %s" %(item[1]))
print ("lin __VIEWSTATE: %s" %(item[2]))
print ("lin __EVENTVALIDATION: %s" %(item[3]))
print ("lin ctl00_ContentPlaceHolder1_txtlogintype: %s" %(item[4]))
print ("lin ctl00$ContentPlaceHolder1$btnLogin_Lib: %s" %(item[5]))
yield scrapy.FormRequest.from_response(
response,
formdata={
'__EVENTTARGET': item[0],
'__EVENTARGUMENT': item[1],
'__VIEWSTATE': item[2],
'__EVENTVALIDATION': item[3],
'ctl00$ContentPlaceHolder1$txtlogintype': item[4],
'ctl00$ContentPlaceHolder1$txtUsername_Lib': 账号,
'ctl00$ContentPlaceHolder1$txtPas_Lib': 密码,
'ctl00$ContentPlaceHolder1$btnLogin_Lib': item[5]},
callback=self.after_login
)
def after_login(self, response):
print 'after_login============'
#查询网址的Cookie
#请求Cookie
Cookie = response.request.headers.getlist('Cookie')
print 'Cookie',Cookie
#响应Cookie
Cookie = response.headers.getlist('Set-Cookie')
print 'Set-Cookie',Cookie
#打印原始数据
print response.body.decode(response.encoding)
#可以自定义Item进行数据处理2.3设置\myproject\myproject\settings.py
# 自动传递cookies与打印cookies设置
# Disable cookies (enabled by default)
COOKIES_ENABLED = True
COOKIES_DEBUG = True2.4执行工程
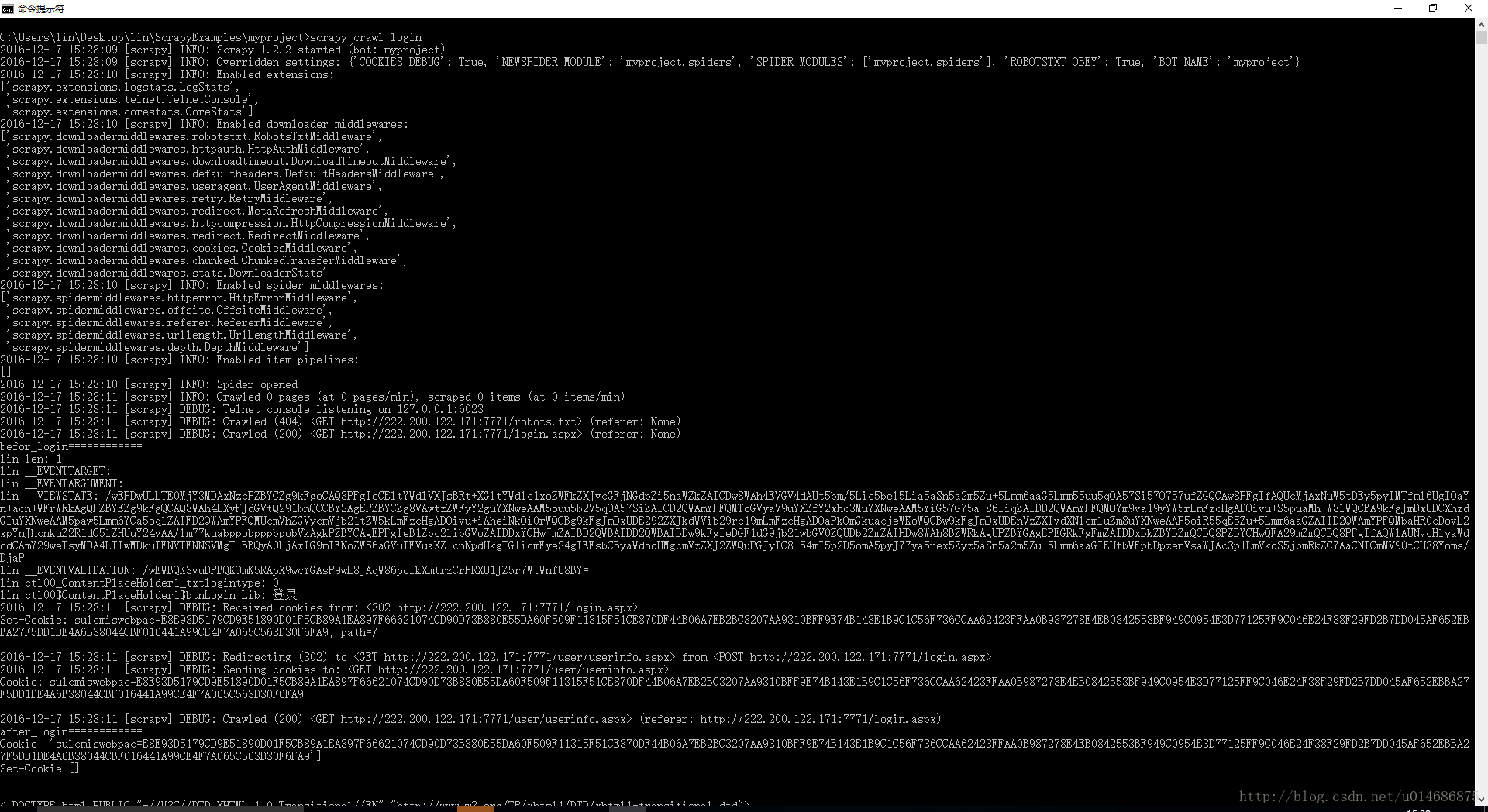
3.总结
3.1正则表达式注意特殊符号需要使用转义符号,如:$。
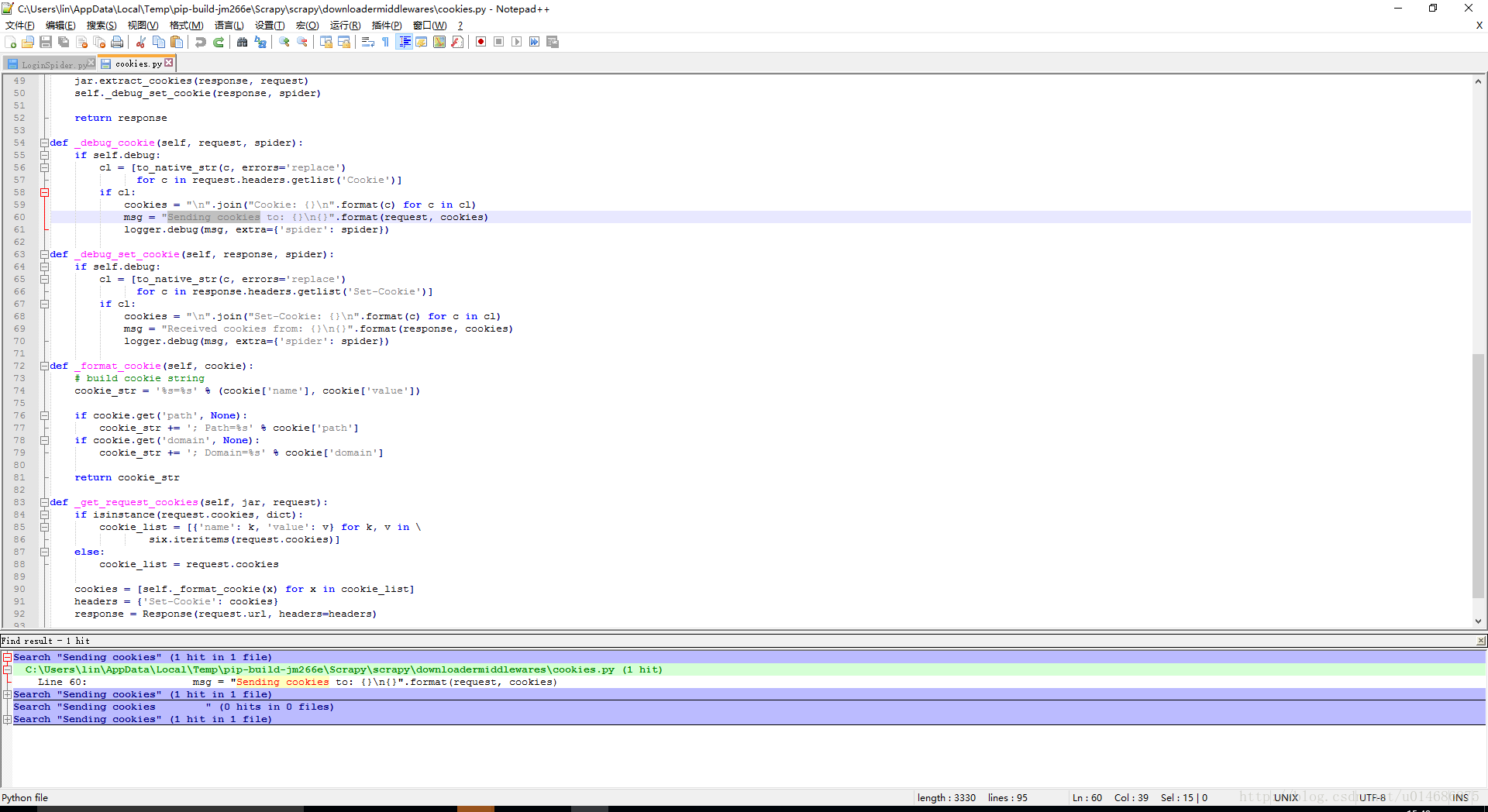
3.2获取Cookie值方法可在Scrapy框架源码中寻找到,使用Notepad++(一般编辑器都有这个搜索功能)在Scrapy框架源码文件夹(如:C:\Users\lin\AppData\Local\Temp\pip-build-jm266e\Scrapy\scrapy)中搜索字符串Sending cookies或Received cookies即可。
3.3 Python爬虫之自动登录与验证码识别
(http://blog.csdn.net/tobacco5648/article/details/50640691)















 334
334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









