






一、FaceChian原理
大体上来看,FaceChain所做的是训练出一个包含用户面部信息的LoRA模型,然后在推理阶段将该面部LoRA与风格LoRA进行结合并注入,最终实现风格化照片的生成。
当然实际应用肯定没我说的那么简单,在整个框架中,FaceChain应用了多种SOTA模型来满足各环节的需求:
- 人像美肤:ABPN
- 人脸检测:DamoFD
- 多人人体解析:M2FP
- 人脸属性识别:FairFace
- 关键点置信度:FLCM
- 文本标注:Deepbooru
- 模板脸筛选:FQA
- 人脸融合:https://www.modelscope.cn/models/damo/cv_unet_face_fusion_torch
- 人脸识别:RTS
P.S.之所以使用人脸融合,大概率是SD生成的人脸不像,为了保证相似度,需要从原始图像中切出人脸进行融合。
这些模型共同构成了整个FaceChain的服务框架,并且ModelScope上均有权重提供(有效避免下载痛苦)
至于训练和推理流程,在官方README中均有介绍,这里不做过多赘述。
- 训练:输入用户人脸图像(脸部干净清晰,便于检测);输出人脸LoRA模型
- 推理:输入用户图像与Prompt,输出个人写真图像
FaceChain
整体流程如下: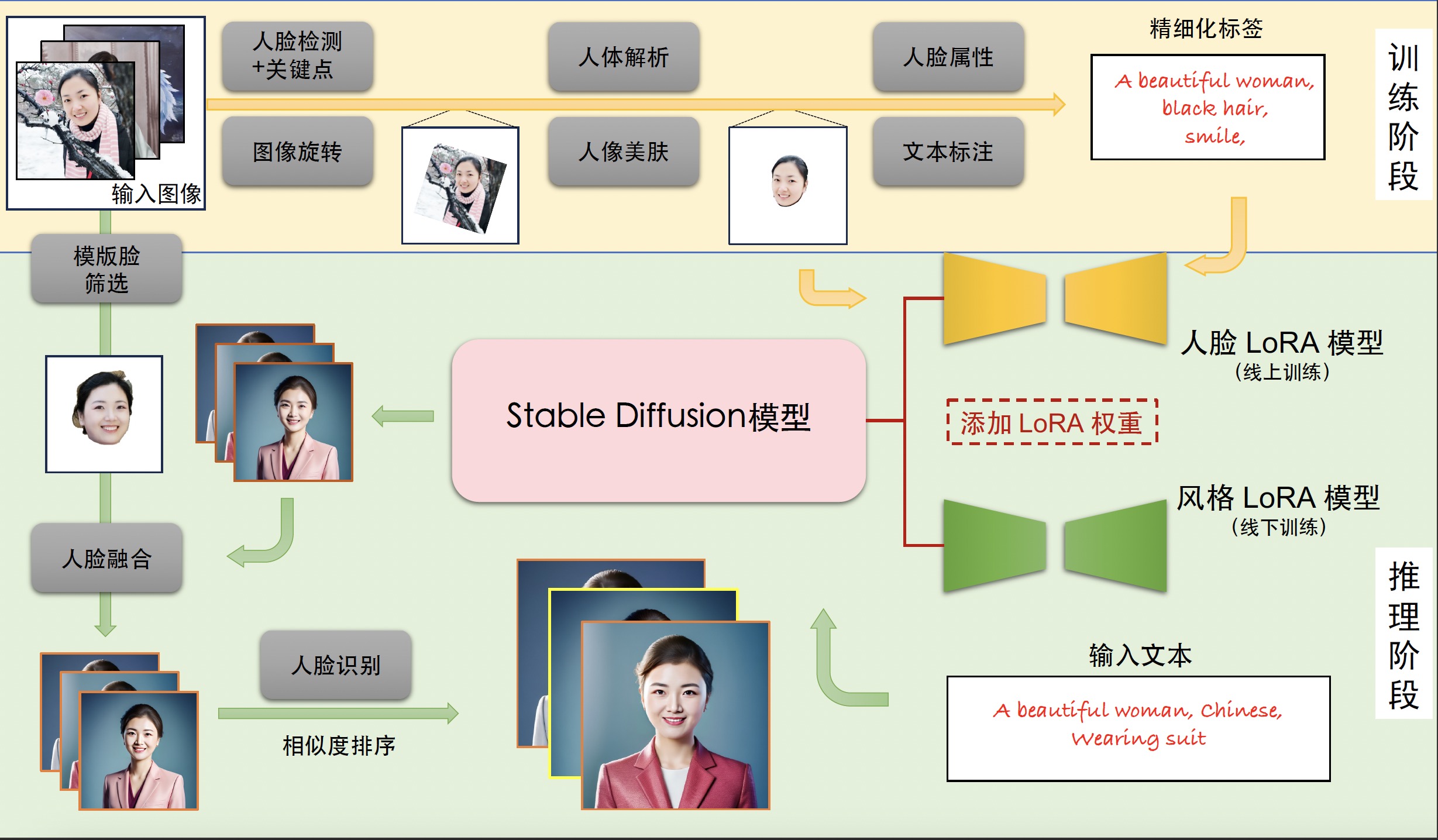
二、基于DSW部署FaceChain服务
这里可以参考DataWhale所提供的部署教程:酷蛙部署-三张照片拥有不一样的你
按流程操作即可,阿里云会送5000核时的A10使用时间
注:个人在应用时偶尔会出现NoteBook中Gradio地址无法点击的情况,换去Terminal中重新运行即可
三、推理尝试
完成部署并正常运行后,点击链接进入Gradio界面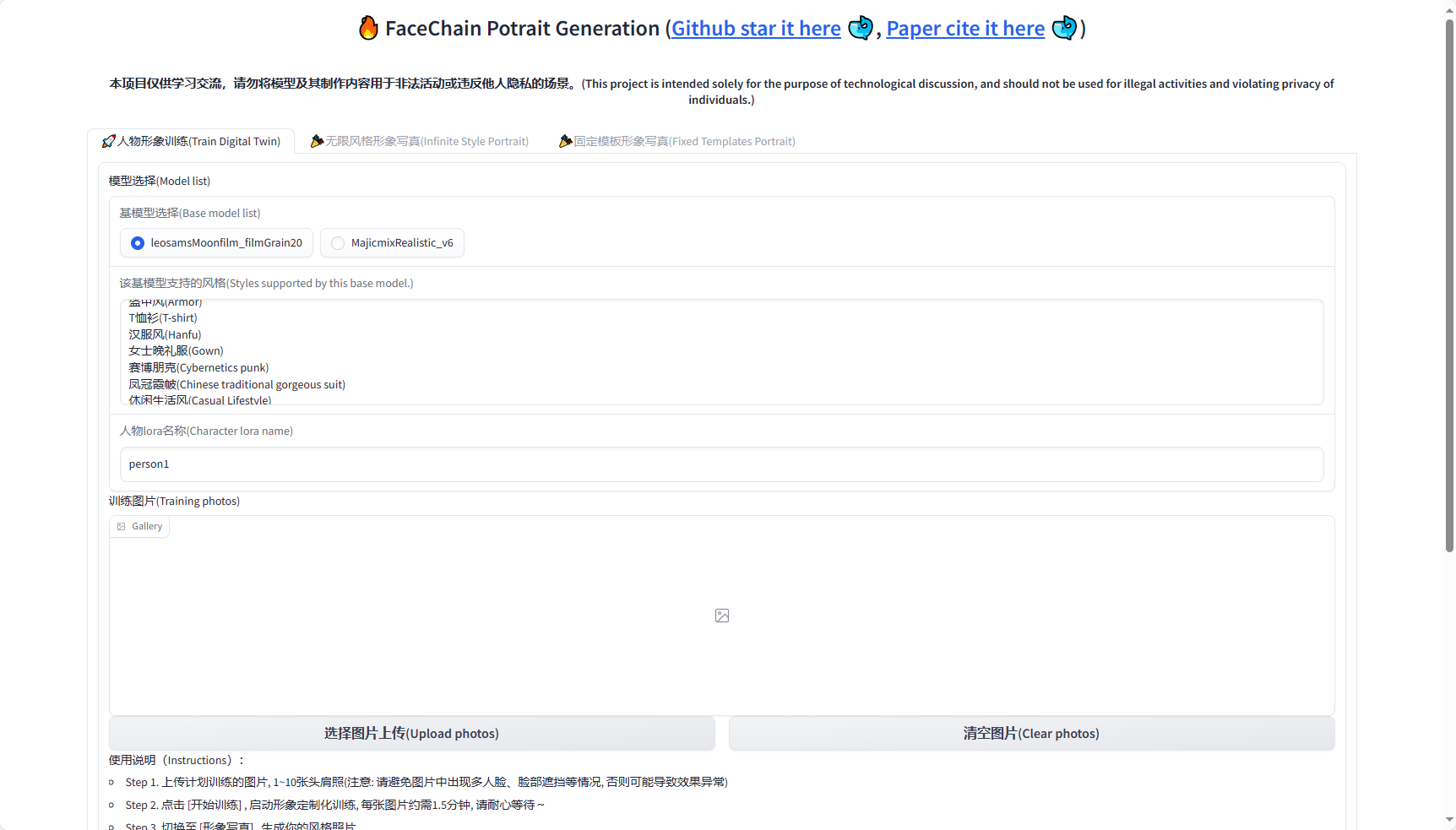
选好基模型并上传图片,进行训练即可。
完成训练后,页面最下方会出现提示信息,切换去旁边风格写真页面。
在风格写真这有几个关键点需要注意:
- 训练时使用的什么基模型,推理时仍需选择那个基模型,不然找不到你的LoRA
- 姿态控制部分如果想使用自己的姿态图像,一定要背景干净,不然会训练失败。
- 这篇博客(https://zhuanlan.zhihu.com/p/655725253)中大佬指出去掉constants.py中第4、5行pos_prompt_with_cloth与pos_prompt_with_style中自带的【slim body】可能会提高一些生成效果。个人测试下来感觉有,但不明显,个人猜测在男性照片生成时且体型较健壮的图像上可能会明显些。
| 原始图像 | 生成结果 |
|---|---|
 |  |
个人感觉还是蛮像的XD
















 4264
4264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











