







第四章——分治策略
1·分治策略(将问题分解为小问题)求算法时间
2代入法:确定递归式,猜测解的形式,求得解的常数并证明 ,确定边界常数
3·猜测:
- 递归式T(n)总时间=确定渐进上界,猜测解,选择常数c,将T换成c,常数1,减去低阶项d(>=0),猜测总时间的范围:应不是增加而是减少(缩减范围)
- 一个数的分数次方等于这个数的分子次乘方后开分母次方。
- 常数项对结果影响不大
4·改变变量T(n)=T(?n)+??递归式(每次递归)=O(?)解
5.递归树法:
- 1求层数:i=深度(0——??),i对应规模n/4^i,层数=i+1,i=log4^n<=>4^i=n,T(1)=最大深度的规模,n/4^i=1,n/4^i=n=1,层数=log4^n+1
- 2求代价:每层代价=每个节点的代价(c(问题规模*i-1)^2)*每层节点数(3^i),总代价=每层代价和,猜测值为渐进上界,用代入法验证
6·主方法:T(n)=a(>=1)T(n/b(>1))+f(n)(>=0函数),f(n)与n^logb^a比较,f(n)<=>,得到3种T(n)
第二部分
(排序为堆形式)
6.1:堆排序
- 二叉堆(数组)--二叉树:0<=A.heap-size(堆元素个数)<=A.length(元素个数)
- 求节点下标(索引)i的父(i/2向下取整),左(2i)右(2i+1)节点
- 最大堆:A.[PARENT(i)]父节点下标的值>=A[i],所以最大值为root
- 最小堆(上述相反)
- 结点高度:该节点到叶节点
- 堆高度:
,n:1,2,4,8……,高度:0,1,2,3……,即:log2^n的x值
6.2:维护堆性质
- 维护最大堆(从上到下值依次递减)的性质Max-HEAPIFY:原理:在i的本身和左右结点找出最大值的下标存储到largest变量中,若最大值不是i就交换i的值与largest的值。接下来再次调用Max-HEAPIFY,因为largest的下标节点仍然可能违反性质。
- T(n)=递归迭代+第一次调用=T(2n/3)??+
(1)=时间复杂度O(lgn )
6.3:建堆
- 用自i(索引)=n/2(一半处)向上转换成最大堆,循环到i=0终止(i自下到上越来越小),例:n=10,i=5,i+1/2/3/....n都是叶结点
- 排序时间复杂度为深度,构建最大堆需要n次调用,总为嵌套乘法法则
- 总代价:每层*结点数??*高度h某结点代价
- downto表示到什么位置
6.4
- 构建最大堆,循环去掉最大值到2并排序
- 构建最大堆需要时间复杂度n,排序需要深度,总乘法法则
6.5优先队列
- 最大,最小,每个元素的关键字,每个对象有句柄(下标)
第四章
4.5主定理求渐进界
- T(n)递归式f(n)函数,T(n)≡aT(n/b)+f(n)
- 已知函数T(n)求T(n)渐进界,三种情况
- 多项式意义上大于小于
4.6,求b的幂证明主定理?
- 求每层结点数,a^i
- 每个结点代价f(n/b^i),每个叶结点代价t(1)
- 深度log(b^n),叶结点数=a^深度(log(b^n))
- 深度j的总代价:当层结点数*每个节点代价
- 内部总代价(不包含叶结点)g(n):每层代价*总层数
- 已知f(n)3种形式,得f(n/b^i),代入后化简求g(n)
- 向上下去整,递归式用在所有式子上
- 序列中第j个元素(某一j行的某元素代价)nj=向上取整nj-1/b递归,nj=n/b^j,<本身+从0到i-1的i/b^i,<本身+1.5,
- 将j替换为logb^n深度,问题规模至多为常数
- 深度j<=logb^n向下取整,意味着每层数量<n
- f(nj)第j元素总数<=(某j元素+1.5)^深度
第七章--快速排序
7.1.
- 分治:p,q,r循环j(p--r-1(最后一位是主元不用管))。(第一次p-r)q(每次取主元位置的+1)=={排序(p-r)。循环(p-q-1)。循环(q+1-r)}
- 排序(p-r):x=A[r]为主元划分成(所有小于的放左边,大于放右)(如果j<x交换ij)i(<x的最右端)将x放中间
- A[r]:值 i:索引
- 注:函数内部调用自己为递归
7.2性能
- 取决于划分是否平衡,最坏情况(每次递归划分不平衡):T(n)=T(n-1)+T(0)+
- 划分后:总代价设cn(每层都是cn,一层的代表总代价),直到只剩其中一个划分,这时代价<=cn。快速排序的总代价是递归的,所以要求和,nlgn(每层代价*总层数)
- 平均情况,假设所有划分等概率,极好极坏交替出现,总划分时间加法法则n
7.3随机化版本7.4分析
- 加入随机化,对输入重新排列,采取随机主元,将原A[r]更改为随机A[i ]
- 最坏运行时间(每次递归取最大值):区间1(0<=q<=n-1(不包含主元))2(n-q-1(不包含主元的部分-q))
- 代入:右边*c,符号变为<=,根据导数??代入<=n^2-2n+1
- 期望运行时间直观上nlgn客观证明:循环的时间是由排序中for循环(比较)决定的(因为每次随机选主元,就不会再排序中调用,所以排序每次-1,为n次)
- 求比较次数引理5.1:每个元素只与主元素比较,i的范围和j的范围,求ij比较时的概率(当i或j是主元时,ij会比较)(1/j-i+1)*2
- 代入引理5.1,k=j-i,证nlgn??
第八章--线性排序
8.1线性排序8.2计数排序
- 假设互异,=没有比较意义,比较排序:画成二叉树,每个节点i,j,高度为比较次数
- n!叶节点可能??<=l子决策树(每个可以从不同方向延展)<=2^h(总结点数)
- 累加:确定小于x的个数,x=个数+1
- n(0-k)A[]输入B[]存放C[0,k最大值]临时存放,首先C全部设为0。遍历A,获取值,让C中对应的值+1。遍历C让C中每个值为本身和之前的总和(累加:该元素对应的位置)。三个数组互相照应
- B[C[A[j]]]=A[j]:某值A对应的位置C应放在B中=此位置的值就是该值A。若某A值存在,下一个A值等于前一个A值-1。(A中序列小的在B中前面,因为从后往前遍历A,前面相同的元素放在前面)
- 总代价(k+n),当k =渐进上界n,k<n,运行时间为n.加法法则
8.3基数排序
- 对于n张d位数,从低次d位排序,确保稳定性计数排序(相同元素后面出现就排在后面),再排高d位
- 每列(一位)耗时一次计数排序(k(元素取值)+n),总代价:共d位d((k+n))
- b位==d个r位,k==2^r??,代入
- 时间:b<lgn,每列线性排序n;b>lgn,r>lgn,逐步减小,相反增加??
8.4桶排序
- 计数排序元素值在小范围区间(建立==最大值的数组)内,桶的值是随机的(建立==原数组索引的存放链表),对每个桶中进行排序(同一桶(插入排序)/不同桶)
- A中每个元素/n向下取整,放到对应桶B中
- 时间:n(分配)+同桶排序
(i=0---n-1)ni^2(每个桶排序时间和)
- 平均时间(分布有关,随机变量Xi(B桶某i)j:落入桶的):取期望时间,即可得出均值(),求E[ni^2]??,通过将ni=
C3离散随机变量(概率和期望(值))
- 定义(随机变量X=实数x)事件:X的概率密度f(x)=Pr(X=x)(X为x时的概率)=Pr(s):s样本空间的某元素,它的随机变量X=实数x
- E[X]:随机变量X的期望值(多个的均值),总期望值(X可具有多个值)==对应值和*对应值*概率1+……概率2==1
- 线性性质,C.22
第九章——中位数和顺序统计量
9.1最小值和最大值
- 确定最小:n-1次比较。确定小大(同时):奇数确立第一个3
(n/2)(多少对元素,每对3次),偶数确立前两个 3
9.2期望为线性的选择算法(选择给定第i小元素)
- 选择问题的分治,只处理划分的一边(else if;else)(与快速排序,找随机数,随机算法)
- 选择函数:(p,r,i要寻找的第i小元素)当查找p==r,返回A[p]; q==随机主元排序的主元位置; k等于q--p的数量; 比较i与k,如相等,返回A[q],如小于,返回选择函数(左不变,右为主元-1),如大于,返回选择函数(右不变,左为主元+1)递归
- 注:对于比较i与k:k==q--p的数量==主元位置(已确定)
- 求平均时间:定义Xk(1--n)Pr==1/n.求上界(递归式):T(n)<=
- 代入常数a,c,??证明E(T(n))==O(n)
- 注:
- 注:a-b=a--b的差=a--b的个数-1; a--<b,a--b的个数-1=a--b的差; a--<=b,a--b的个数=a--b的差+1;
9.3最坏情况的选择算法
- 划分函数:
- 将n划分
n/a(奇数)(剩下取余)组。对每组插入排序,确立中位数。
- 找出中位数的中位数()(若为偶则为小的中位数)。划分高低区,k==低区数目+1==x。通过比较ik,确定在高低区递归划分函数
- 时间:
- 中位数的中位数:
- 确定>主元x的元素个数的下界(排除主元x本组和mod组)(每组中至少有a+1/2>主元x:小于本组中位数的并不一定>主元x) ; 确定>主元x的元素个数的上界??(主元x本组至多a-x)(mod组至多a-1)(每组中=a)
- 最坏总时间==3个相加,T(n)<=cn,将函数T替换为c,线性的??
15章动态规划
- 分治->不相交子问题,组合(对于重叠,重复计算)。动态规划->应用于重叠子问题(避免重复)
- 长度为n,距离左端的i长度(1--n-1,n个数)->切割方案,n(最优切割方案k)=i1+i2……ik,每段价格不同,rn=pi1+pi2……pik.。
- 对于每个i,划分为两段(i,n-i),求每段的最优收益。Rn=Max(不切割,r1+ri-1 ,r2+ri-2 ,……,rn-1+r1)==(0<=i<=n)Max(pi+R(n-i))选取最优方案。
- 代码实现函数:Cut(p,n)for(遍历n-1次{q==Max(q,p[i]+Cut(p,n-i)}return q(最大收益)
- Cut递归树(当n=4时):
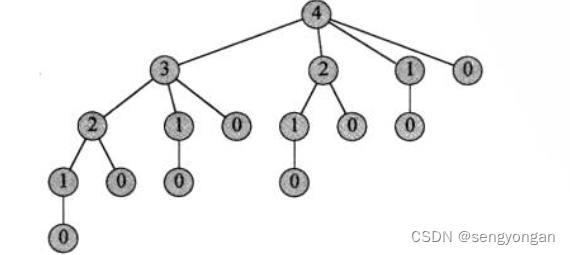
- 时间复杂度T(n)=1(根节点)+
- 子节点重复计算。
- 自顶向下(带备忘录):建立数组r,让所有ri= - 无穷。Cut{判断ri是for大于0,如果是return r[i].(证明ri已经计算过)q==Max(q,p[i]+Cut(p,n-i)。r[i]=q(计算过,将值记录到数组中)
- 自底向上(动态规划):建立数组r,外循环遍历每个数,内循环(1--i),q==Max(q,p[i]+r[i-j])(当选择i时,所有可能的最大收益)r[i]=q记录到数组中。
- 也可让r==Max……,返回r[n],就不用每次存储。
15·3原理
- 最优子结构,对于为n的父问题假定最优选择, 产生(一或多)子问题。总子问题(自下而上)--选择--子问题(条件下)。子问题无关性(互不影响)
- 重叠子问题:矩阵链的递归1--4(k值):11,12,13,23,34,44求时间T(1)>=1,T(n)>=1+
- 因为T(1)>=1=2^0,所以T(i)>=2^i-1,代入上面,T(n)>=2^n-1
- 重构自底向上最优:备忘,将2维ij赋值为无穷,递归函数如果m[ij]<无穷(递归过,即为备忘中)直接返回结果q。否则递归以k为分界的左右部分,+两者*。(p为矩阵规模)
- 每个m[ij]都要遍历完所有k种可能,求出最小值。最后回到父问题的最小值。
15`4最长公共子序列LCS
- 满足为序列Xi的子序列Zj条件:i下标(1--k)(严格递增:只能>,不能>=),对于所有j(1---k),满足zj(z中某元素)=(对应)xi下标j(x中i下标j的序列,因为是严格递xij<xij+1)(ij代表x中某一个元素,未知)
- 简单说:子序列所有元素按顺序的包含在序列X里面
- LCS:对于两个序列中最长的公共子序列。XYZ。父(下--上:子问题)--选择--情况下的子问题
- 字符子串:指的是字符串中连续的n个字符 。字符子序列:指的是字符串中不一定连续但先后顺序一致的n个字符
- 如果用穷举,要找X的所有子序列,2^n种:每个元素取1/不取0,对于十进制,每个元素有10种可能,00……0到10……0=10^n。对于二进制,每个元素有2种可能,00……0到11……1=2^n。例:n=3时:000,001,010,011,100,101,110,111共8种
- 父(0--i)--选择(0--j)--2种情况(0 , x=y , x!=y)下的子问题:0 ,左上+1,上/左中取max
- xm,yn为两序列XY中前m和n项构成的子序列中的最后项,Z(1--k):XY中的LCS。
- 情况1:xm=yn,那么=zk,并且zk-1=xm-1=yn-1:
- 反证:如果zk!=xm=yn,那么两种情况:
- 1:!=z中任何元素:根据xm=yn可以追加到lcs中,k+1>k,矛盾。
- 2:=z中!k元素:因为xm=yn是末尾元素,按照递增原则,zk不可能有值,矛盾。
- 假设存在>/<k-1的lcs,因为xm=yn,追加到lcs中,得到的结果</>k,与lcs=k矛盾
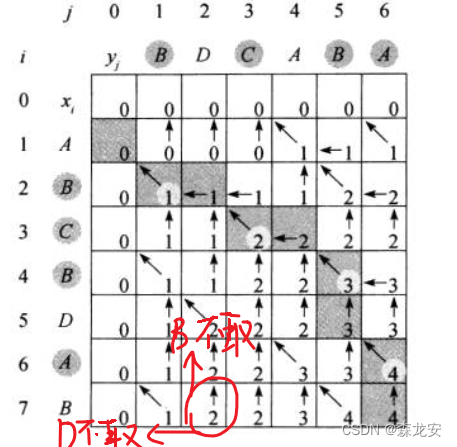
- 情况2:xm!=yn(至少有一个成立,因为它们不可能相等),可以令zk元素往zk!=xm/zk!=yn:上/左找MAx。
- 最后输出,只要从最后判断箭头方向即可。
15·5最优二叉搜索树
- 给定n个不同关键字序列(k1……kn),每个都有搜索概率pi。构造一棵二叉树T。有n+1个伪关键字(d0……dn)!在k中,搜索概率为qi。一次搜索(一次成功)的期望为深度+1(深度:0……n-1),注:T的搜索期望(贡献和):
- 最优的为期望最小的,让概率大的出现在靠近根的位置(搜索=深度+1,值较小),但是最高概率的也不一定在根结点。
- 对于ki……kj(1<i<j<n),最优T包含最优子树(反证)。选择kr根节点,出现子问题(左右子树)。空子树:如果ki为根节点,ki-ki-1不包含k,伪关键字di-1;如果kj为根节点,kj+1-kj不包含k,伪关键字di。
- e(i,j)为一次搜索的期望:pr(根结点概率)+e(i,r-1)(递归)+(增加)w(i,r-1)(成为子树的增加值=概率和)+e(r,j)+w(r,j)
- 递归(备忘),e(1--n+1(空子树dn),0--n(空子树d0)),root(i,j)=根,w(i,j)。递归过程近似矩阵乘法。
- (tab)例:w1,0=d0;2,1=d1;3,2=d2;1,1=d0+d1+k1;2,2=d1+d2+k2;1,2=d0+d1+d2+k1+k2(左+右+本身值
- e1,1=(左子+右子+本父树)=d0+d1+(d0+d1+k1)
- 注解:ki*pi深度相当于遍历次数,是什么层数就*几次,例:e1,1=d0*2+d1*2+k1*1
16章贪心算法
16·1 活动选择
- 有n个活动a1……an,按照f递增排序,每个活动的开始s结束 f,每个时刻只能有一个活动使用,如果两个不重叠的活动兼容的,选出最大的兼容集合。
- sij在活动ai结束在aj开始之间的活动,设aij是最大兼容的子集包含活动ak,划分为k左右的两个子问题,。令aik=sik与aij的交集=aij中在k前的子集,akj……。
- 贪心证明最早结束的为最优选择:令sk为ak结束后开始的活动,am是sk中结束时间最早的,证明am在最大兼容中。
- 递归:首先建立a0,令m=k+1,如果m<n(活动结尾)&开始位置<上个k的末尾(两活动重叠),那么m++,直到不成立(加入活动中,递归)。否则递归从新m开始,返回am
递归(m,n)。最后返回所有am的
- 迭代:a=a1,k=1,form=2--n,如果开始位置>上个k的末尾(可以加入结果中),a=a
- 注:最大兼容的活动集:有几个活动(场次),不必看总时间。
- 贪心算法正确性证明:
- 命题:最早结束活动,是最优解一部分:
- aj是ak(最大兼容)中最早结束的活动,如果aj=am,am则在最大兼容中
- 替换法:如果aj!=am,集合ak‘=ak-aj+am(替换)。因为ak中活动不相交,并且am是sk中结束时间最早的,所以fam<=faj,所以替换后也不会和后面冲突<saj+1。替换后ak'=ak,所以也是最大兼容,(包含am)am在最大兼容中。
- 并不能保证在所有情况下都能获得最优解,所以需要正确性证明:归纳法和交换论证法。
- 数学归纳法:
- 建立命题。论证:当n=1时命题(算法)成立(基础成立),假设(m时也都成立)(n=m+1),将n代入命题,若==命题右侧结果,则命题成立。
- 例:命题:1+2……+n=(n*n+1)/2。论证:当n=1时假设命题成立,代入命题=1,符合命题右侧结果论证成立。当n=n+1,假设n时命题成立,将n代入命题中,,符合结果论证成立。
- 例:最小生成树:每两个点构成边,有各自权重,求最小生成树(权重最小)。命题:每次选权重最小的边,如果点已被选中则舍弃边,未选中则加入,可得最小生成树。
- 证:当n=2时命题成立(两点直接相连)
16·2原理
- 共同点:由子问题构成父问题。递归式 / 迭代。最优子结构。
- 动态规划:子问题--决定--选择。自底向上/自顶向下(备忘)。通过选择产生多个子问题。要遍历所有子问题求原问题。
- 贪心:选择---决定--子问题。需证明选择能生成全局最优解。自顶向下。通过选择产生一个子问题。不必遍历所有问题。
- 如果一个问题的最优解可以通过最优的子问题求解,为最优子结构
- 动态规划:子问题的最优解+子问题的最优解=最优选择=全局最优解
- 贪心:证明子问题的最优解 +选择 =全局最优解
- 设计步骤:
- 动态规划:假设对于n元素某种选择为最优选择,确立划分的子问题。递归式:从1--n子问题,划分1--k的选择,划分为dp(子问题)+dp(子问题)
- 贪心:递归式:猜想某种选择,产生为一个子问题,对这个子问题dp。证明选择成立。
16·3赫夫曼编码
- 对于一种字符c,用唯一二进制表示,叫码字(为压缩文件),为减少存储成本,不适用定长编码(固定码字数),使用变长编码,求代价:需要
- 前缀码:每个码字互不包含其他码字,可以进行解压文件。
- 编码树T:通过二叉树表示,叶节点为字符及频率,内部节点(n-1个)为频率和,深度为码字数。
- 求最优前缀码编码树:代价B(T)最小
- 贪心选择:每次选最小频率的两节点求和:建立最小优先队列Q,进行n-1次循环,x,y分别为队列中最小的频率frep元素,z为两者频frep率和,将z放入Q中。
- 证明具有贪心选择性质:如果令x,y分别为最小的频率,那么将存在最优前缀码,且两者长度相同(深度相同)
- 如果可以证明:xy替换深度最大的两个节点,代价仍是最优前缀码编码树。
- 令T是最优前缀码编码树,令ab是深度最大的两个节点,令T1树为X与a替换后,T2树为X与a替换后和y与B替换后。
- 根据求代价公式,可以证明T-T1为非负,T1-T2也为非负。则T1<=T,T2<=T1则T2<=T。
- 因为T为最优前缀码编码树,所以T2也为最优前缀码编码树
- 证明具有最优子结构:合并两个最小频率的字符,具有最优前缀码编码树
- 让T1为字母C中xy合并为z的最优前缀码编码树,T为z替换为xy最小的频率。
- 首先看代价B(T1)与B(T)的关系,可以推论dr(z)+1=dr(x)=dr(y)。B(T1)=B(T)-x的频率-y的频率。
- 如果分解后的树T不是最优前缀码编码树,那将存在T2<T。即合并后的B(T3)=B(T2)-x的频率-y的频率 < B(T1)=B(T)-x的频率-y的频率。也就是B(T3) < B(T1)。T1就不是最优前缀码编码树。与假设不成立。所以T必须是最优前缀码编码树。
16·4拟阵
- 拟阵M的3个性质:m(s,t)——有限独立的集合
- s是有限集
- t是非空子集,且是独立子集。遗传性:a属于b属于t,a属于t。
- 交换性:a属于t,b属于t,a<b,存在x=b-a,a
- 无向图:边没有方向
- 无向树:连通(从任何一个顶点可以到达任何顶点)无回路(无圈)。
- 有圈:每个临界点相连,首尾相连。
- 森林:不连通,但每个连通分支都是无向树(即无回路)。
- 图拟阵(并非拟阵):g(v,e)(顶点,边)m(s,t):
- s为e
- a为边e的子集(一条或多条边),当a是无圈时(即a的子图是森林时)a属于t(即a是独立子集)
- 证明无向图的图拟阵是拟阵
- 首先s为e,所以s是有限集
- 符合遗传,因为森林的子集为森林
- 交换性:对于两个为森林的子图ga(V,A)gb(V,B),B>A,意味着gb有更多的边。
- 首先证明图的树=V-E(某图总共t棵树,第i棵树,vi该i树的所有顶点,ei该i树的所有边):
- 总e=
- 那么图总共包含t棵树=总V-总E
- ta=V-A,tb=V-B,因为V相同,B>A,所以tb<ta(图b的树少于图a的树)。那么由于V相同,树总数不同, 边数不同,那么图b中必然包含一条边,连接了图a中不同树的顶点。
- 将这条边加入图a,不会产生圈,因此有交换性。(即b中比a多的部分,加入a中也是独立的)
- 无向图的图拟阵M中(有三性质)如果x不属于独立集合a,把x加入a中,集合a依旧独立,则x为a的扩展。如果独立子集a不存在扩展,则称a是最大的。
- 证明:所有相同最大子集都有同样大小
- 假设存在独立集合b>a,将b-a=x加入到a中,那么新的a>a,与a为最大子集矛盾
- 最大独立集合a边数为V-1,即连接了所有边
- 加权拟阵:w(a)集合a的权重=
- 对于最小生成数:w(e)表示边的长度(每个边长度不同)(代替权重)希望找到子集能连接所有节点,并且有最小长度(权重)
- 寻找拟阵最优(权重最小)子集:对于独立集合A,所有边的长度差和w':
- 求最大权重:对于集合a的每个元素,按权重递减排序。循环n次,判断如果加入x,集合仍独立,则加入。
- 时间:排序:nlgn。循环n次,每次判断:f(n).即nlgn+nf(n)
- 替换法证明:选择最大权重一定在最优解中——拟阵的贪心
- 如果x是权重最大的,存在一个最优解a包含x(需要证明是否存在)
- 存在最优集合b,不包含x。因为独立性质,b中所有元素y均小于x的权重。
- 现在构造集合a,加入x,其余在b中寻找可以保持独立性的其他元素,使a=b
- 因为b是最优,a=b,所以a也最优,且包含x。
- 如果x是a的扩展,那么也是空集的扩展。如果不是空集的扩展,那也不是a的扩展。
- 如果选出x元素,剩下的选择s(包含x)t(排除x,且能和x组成独立的)
16·5用拟阵求任务调度
- 每个任务a有截止时间d和非负权重惩罚值w,将其转化为拟阵并用贪心求解
- 在任务之前完成时间k,任务a称为提前任务,反之为延迟任务
- 寻找最优方案(权重最小):
- 将ai提前任务都置于aj延迟任务之前(交换:指交换完成时间将提前)。提前任务按照截止日期递增排序。
- A为提前任务子集,如果某个选择方案,使A中所有任务都不延迟,则A是独立的。令Nt(A)为截止时间<=t的任务数。对于N0(A)=0(截止时间<=0没有任务数)
- 满足以下条件即证明提前任务A集合是否独立(没有延迟的任务):
- A是独立的
- Nt(A)<=t(任务数<=t个)(其中每个任务的截止时间<=t的任务数<=t)(且t的范围0---t)
- 如果增序顺序调用,就不会有延迟
- 反证由2--1(因此可由1--2):如果Nt(A)>t,则必定有延迟。证明:每个任务都是一个时间单位,那么总时间一定是超过的,则一定有延迟(最后一个的完成时间超过t)
- 2成立3必定成立:对于每个完成时间下截止时间<=0--t的任务数<=0---t,递增下每一次满足最后就满足(任务数多余的即延迟任务)。由3可以推出1是否成立
- 最小化延迟任务(减少惩罚)和最大化提前任务(避免惩罚)等价。
- 证明使用拟阵并用贪心求解可以求出惩罚最大的独立集合A:——首先证明s(由截止时间的集合),t(所有独立任务)是拟阵(即我们的任务符合拟阵,即可根据上节的,拟阵可以使用贪心)
- s有限,连通性:独立集合A,子集也是独立。
- 证明交换:假定a和b是独立集合(无延迟),b>a即任务数多,让完成时间k为Nt(b)<=Nt(a)的最大t(即在n时间下,b中满足的任务<=a中满足的任务个数,满足这个条件取最大t,最小为N0(b)=N0(a)=0)那么k+1即b中>a的任务个数。
- Nn(b)=b,Nn(a)=a,但b>a,对于完成时间k<=j<=n+1,必然有k<n(交换1)且Nj(b)>Nj(a)。因此包含ai=更多的比a多k+1时的任务。??为什么找这样的k
- 需要证明a
- 证明独立集合A为拟阵(即我们的任务符合拟阵,即可根据上节的,拟阵可以使用贪心)
17·章摊还分析,所有操作平均时间
17·1聚合分析
- n序列操作最坏时间为T(n),摊还代价为T(n)n个操作最坏时间 / n。
- 栈操作:
- 新的栈操作——删除k个元素:将栈顶k个元素全部弹出。时间代价:min(s当前栈中元素,k)
- 在空栈中,由n个操作组成的序列,一个删除k操作最坏情况为n(最大情况即最坏情况),n个操作最坏情况可能都为删除k个操作,即每个最坏情况*n个=n^2。
- 聚合分析:在空栈中,考虑由n个操作组成的序列下,要考虑到每个操作,当push后每个元素只能弹出一次,不可能对于每个元素删除k个操作执行多次。则最多花费n??(n+n)
- 每个操作摊还代价:n/n=1
- 二进制转十进制:从二进制右端往左写,每个0/1*2^i(i=0---1)
- 二进制计数器(二进制表示值):由k个长度,保存的值为二进制值为x时,存储数组递增(a[0]低位--a[k-1]高位),十进制x=
- 将二进制数组a[0]=0。每次调用翻转函数(即每一次十进制计数+1):索引i=0。循环如果i=1,就翻转为0,i++。翻转结束 / 当前为0,并让当前i的位置=1(即翻转1--0后的下一位)
- 1个翻转操作最坏情况为都是1,即时间=k。n个翻转操作最坏情况为=n*k。
- 聚合分析:不可能每次翻转所有。对于每个二进制位,翻转次数=n/2^i(i=0---1)次。所有二进制位,翻转次数=
- 时间复杂度位n,每个操作摊还代价:n/n=1
17·2核算法
- 实际代价:对于某个操作一次时最坏情况运行时间。
- 不同操作不同费用也称摊还代价,当摊还代价超出实际代价,将差额存入特定对象作为信用,当小于,用信用支付差额。
- 如果想证明每个操作平均代价很小,要确保总摊还代价给出上界,插值即为信用
- 对于栈操作,用1支付push的代价,用1为存入作为信用。当pop时用用信用支付差额。
- 对于二进制计数器,置位时,用1为存入作为信用。当复位时用用信用支付差额。
17·3势能法
- 数据结构D0执行k个操作,ci(不是指第i位,指操作)为操作的实际代价,势能将每个数据结构DI映射到实数
Di。
- 第i个操作的ci^摊还代价=ci实际代价+第i个操作和前一个操作的势差。
- 总摊还:
- 让总摊还>总实际,也就是
- 对于势差i-(i-1):如果为正多付费,如果为负,支付了操作的代价。
- 栈操作:
- multipop:势差:=- min(s,k)=-k'。该操作摊还:k'(实际代价)-k'(势差)=0。
- pop摊还=0。总摊还=n,因为摊还为实际的上界,即将摊还作为实际的最坏运行时间即
上界(n)
- 二进制:
- 将势能bi定义为:当前i次操作的1的个数。如果bi=0,则k个全部复位=ti=bi-1上一次的1的个数(需要这次复位的个数)。如果bi>0,则没有全部复位。bi <= (??)bi-1上一次的1-ti复位数+1置为
- 实际代价:ti复位数(1--0)+1置为(0--1)
- 势差:<= bi-1上一次的1-ti复位数+1置为-bi-1上一次的=计算1-ti
- 第i个操作的摊还ci^:(ti+1)+(1-ti)<=2
- 总摊还为上界:因为
- 因为摊还<=2,
17·4动态表
17.4.1表扩展
- 建立一个表T后插入对象后表会扩展或收缩。装载因子为表中数据项的数量 / 表规模(槽的数量),赋予空表规模0,因子1.
- 扩张表:原表为1。如果表的数据项的数量 =表规模,就分配newtable为原表2倍(即2^n),将旧数据复制到新表中。让变量为新表,向新表插入新的数据。如果表不是满的就直接插入。
- 一个操作在表非满时为1,没有满为i-1复制+1基本插入。分析n个操作的代价,为n^2。
- 聚合分析的n个操作:一次插入一位,只有当当前i为2的幂时本次代价才为i,其余为1。总代价:n(无论是否为2的幂都会插入)+
- 核算法:每个插入操作摊还为3,第一个为支付本次插入的代价,第二个为本次的信用(作为下一次扩展),第三个为2/n中的一个数据项的信用(作为下一次扩展)
- 势能法:
- 摊还代价:没有扩张时:1+
17.4.2表收缩和扩张
- 为了限制浪费的空间,进行表收缩,确立装载因子a的下界(在什么时刻收缩)
- 当将收缩定义为a1/2:现在看将表T,前n/2个操作为插入,总插入代价为n,后n/2个操作为两插入+两删除,每次扩张和收缩的代价为n(复制当前到新的表中),n个操作扩张和收缩次数为n,即总代价为n^2。
- 这时没有足够多的费用??
- 势函数为实际+变化差
- 当将收缩定义为a1/4:
- 势有足够支付收缩扩张的代价
- 分析插入操作摊还代价(因为这次有删除操作,所以num<=1/2):当上一次操作>=1/2时,插入的代价和上一节一样都为3(无论是否扩张)。当上一次操作<=1/2时,且这一次<=1/2时,代价=0。当上一次操作<=1/2时,且这一次>=1/2时,代价=3.
- 分析删除操作摊还代价:当上一次操作<=1/2时,且本次没有触发收缩,则numi-1=numi+1,则2。当上一次操作<=1/2时,且触发收缩,则本次实际代价numi+1,则1。
18章B树
18.1定义
- 通常比红黑树高度小,但孩子节点大。n个关键字有n+1个孩子。主存通常要比其他存储容量高。对于较慢的磁盘以B树形式存储多个数据项。用读出写入作为存储次数,定位和读取要比计算时间长。
- 如果在主存中,可以引用属性。如果在磁盘,要先存入主存
- 每个节点存放卫星数据和关键字和指针。当关键字移动令2个一起移动。B^+为变种,卫星数据在叶节点,内部存放关键字和指针。最大化分支因子??
- B树性质:
- 当前节点属性:关键字个数x.n。关键字本身x.key(1---n)(在结点x上面写:abcd英文字母)(对子树关键字分隔:ki表示x的某个孩子种的关键字:将父节点的每个关键字作为对应子节点关键字的分割c1.k1<=k.key1<=c2.k2<=k.key2)。bool x.leaf如果x为叶节点为true。
- 孩子/指针个数x.n+1。孩子本身x.c(1--n+1)(叶节点没有定义)。
- 叶节点有相同深度h。关键字是有范围的:上下界,可以用固定变量--度数 分别表示每一个:t>=2
- 非空树,根下界为1,内部节点下界为t-1,则对应t个孩子。关键字上界2t-1,则对应2t个孩子。当恰好有2t个为满的。t越大能包含的关键字越多,树高度越小。(高度越大,磁盘存取次数越多)
- 指数:a^x=y对数:loga^y=x -> a^x=y(ay正比,ax反比,xy正比)树的高度:h<=log t^(n+1)/2(th相当于ax反比关系)
- 证明高度公式:
- 除了根节点每层节点数=2t^h-1(h:0--h):相当于=t^h
- 总关键字的个数(和树的高度和度数和每个节点可能包含的最小关键字数有关)n>=
- 1()根节点+(t-1)(每个结点最小关键字数)
- 再n>= 2t^h-1。t^h<=(n+1)/2,两边取对数(左边相当于a^x=y,变为log形式)可证明。
18.2操作
- 约定:如果根在主存种不需要read,当被改变需要write。结点被当作参数之前,要做read。所有操作都从根向下。
- 搜索关键字(区别在于要遍历n+1遍)(x当前节点,k要查找的):
- 遍历当前节点的关键字次,直到k<=当前某个关键字。当==即找到,返回当前节点和关键字的索引。如果当前为叶节点,则没有找到return null。
- 当<当前某个关键字,那么就查找(x.ci)(因为父节点key作为划分,查找子树相同索引的c1.k1<=k.key1)(第一个关键字>第一个子节点中所有关键字)(小于这个关键字即查找小于它的关键字)
- 访问磁盘的次数=高度=logt^n(因为2t^h-1相当于=t^h)(让每个节点关键字数相等所以为=号)每个节点搜索关键字花费Ot的时间,那么总cpu时间=t*logt^n(每层只需要遍历一个节点)
- 创建空树:
- 使用内置分配磁盘,和设置属性。
- 向非满x插入关键字(x,i):(书上图错误)
- 不能创建一个叶节点将关键字插入,这样违背B树性质。所以只能在已有且非满的叶节点。对于满的叶节点y,按照中间关键字y.keyi分解为两个包含t-1个关键字的节点(因为满的为2t-1)。
- 中间关键字y.keyi提升到父节点,作为划分两个节点的划分点。那如果父节点也是满的呢?从根节点往下遍历,对每个遇到的满的节点分裂。那么当在满的叶节点插入时就能确保父节点不是满的。
- 分裂:如果要分裂满根,要建立新的空根,原根成为新根的孩子。实现:x为父节点。分裂y,创建叶节点z数量为t-1,循环i总t-1次向z.keyi第一位= y.keyi+1分割点i的后面。循环i总t次向z.ci = y.ci+1 将孩子移入。调整y关键字个数。
- 将中间关键字插入到x中,将x的从i+1后孩子整体向后移,x的i+1为z。将x的从i后关键字整体向后移,将y的i插入到x的i位。将xyz write。
- 执行一次磁盘,树高1。cpu占用t。
- 向满x插入关键字:
- 主函数(应对根为满)(每次插入关键字都要检测,根满立刻分解):变量为当前遍历的树的根。如果==2t-1,就建立新根,(对根分解会增加高度) 设置s.n=0,s.c1=原来的根,分裂函数(新根,k),调用辅2(新根,k)。如果不是满,直接调用辅2。
- 辅2函数(当前节点,k)(将k插入到叶节点):如果当前是叶节点,并且如果当前节点关键字>=1并且k小于当前关键字(从后往前)循环,i--,直到k>=当前关键字。循环结束让k插入到 i+1。
- 如果当前不是叶节点(递归,直到叶节点为止),再次找到k>=当前关键字,索引位置为i+1.(寻找对应子树),如果子树也是满的,就分裂当前结点。分裂后再次递归。
- 时间和搜索时间一样
18.3删除
可以从任意节点删除,当从内部节点删除要重新安排孩子,关键字不能少于下界。
- 情况:
- 如果k在叶节点,且父节点x有>=t(之后从内部节点x可以删除),则直接删除。
- 如果k在内部节点x中,有3种情况:
- 如果前于k的子节点包含>=t,则找到子树中k的前驱替换到现在的位置
- 如果前于k的子节点包含=t-1,则找到后继替换
- 如果都=t-1,则合并
- 如果k在叶节点,但只有=t-1(因为至少t-1)有两种情况:
- 如果k所在的子树,只有=t-1个关键字,则将x中某节点移到子树中,并将x的左/右兄弟升至x
- 如果k所在的子树,只有=t-1个关键字,左右兄弟也都只有=t-1,则……??
19·章斐波那契堆
19.1斐波那契堆
- 7种操作称为可合并堆,可以在常数摊还完成。遵循最小堆性质——关键字>=父节点关键字。
- 每个节点x包含父指针和孩子指针(多个父多个孩子)。某节点的所有孩子y被连接为环形双向链表(可以在常数时间插入/删除),y的左右指针指向左右兄弟。如果y唯一,那左=右=y。称为孩子链表。
- 节点还包含两个属性,孩子个数x.degree。x.mark是否失去过孩子,若失去过标记--true,其中新产生的节点未标记,并且当成为另一个的孩子时也未标记。
- 斐波那契堆H,通过H.min访问最小关键字节点即根节点。树根也用左右指针连接为环形双向链表,称为根链表。H.n表示节点总数。
- 势函数
- 最大度数Dn——孩子个数(注意为该节点的下一行的所有结点,多次搞错)(以下如有错误并未改正)
19.2可合并堆操作
- 如果在根链表插入结点,需要常数时间。不同操作间可以性能平衡。创建空树所有参数为0,摊还=实际代价=1
- 插入:初始化x属性。如果H.min==null即空树,则让H.min==x。否则将x插入到根链表,并且如果x的关键字<H.min的关键字,则让H.min==x。最后让H.n+1。
- 插入的摊还:实际代价+(tH+1(树总数+1)+2mH)- (上一次的……)=1
- 寻找最小节点为1,即根。由于势差无变化,摊还=实际=1
- 合并堆:建立新堆,找出前两堆最小值,更新新堆的min和节点数。
- 合并的摊还:由于势差无变化,摊还=实际=1
- 抽取最小节点:
- 加入:如果最小节点不为空,就遍历每个孩子加入到根链表中,父指针为null。如果要被删除的最小节点没有右兄弟,min=null,否则min=右兄弟。
- 合并(让所有根度数不同):
- 建立数组A(被某树的孩子个数填充值)大小为最大度数+1(0--度数)。外循环每个w节点,让x=w(记录当前根的位置),d=x的孩子树(记录当前根的孩子树)。
- 数组A+1的作用:最大度数的根可能有多个和其度数一致,当两个合并后,每次合并根孩子数都会+1,即存放到孩子=度数。且其余原来一致的根将 !=现在的合并度数。所以孩子数量最大==度数。
- 内循环:当Ad有值(即上一次初始化过)则内循环:不断遍历x的Ad直到为null(x根每次合并都会孩子数+1,新的Ad若不为空,继续内循环)。让y=数组Ad指向的节点。比较两者关键字大小,若x>y将两者交换并链接。因为合并后x指向的Ad向后移动并+1,所以当前Ad=null,且d+1。 若没有初始化,则初始为x。然后外循环迭代下一个x。
- 迭代=遍历一次=外循环1次=内循环n次
- x作用:x记录当前根的位置,暂时被赋值为w,w记录当前根。若x所在的根,被移到其他度数一致的树下面,xw将不同,w跟随根移动,而x因为缺少根指向,被移到原来根的左兄弟若存在,不存在更新到右兄弟。
- 外循环遍历到最后一个x时(前面根都已不同),若Ad=null(当前根没有相同),则初始化Ad,并退出外循环,循环结束。
- 更新:遍历每一个,不断更新min。
- 抽取摊还:
- 实际代价:加入操作:最多Dn个孩子,因为高度不能超过最大度数。合并:根链表的大小至多:tH(原来根链表节点数)-1(剔除min)+Dn(min的孩子数),而内循环取决于根链表数,因此=根链表数。
- 势差:抽取后根链表的结点数至多Dn+1,因为建立的A=最大度数+1,对于每个度数至多存在一个根。
- 因此摊还代价为O(Dn)。
19.3关键字减值和删除
- 如果新的关键字小于x的关键字,可以发生减值。让y为x的父亲,如果y存在,且x小于y(即不符合堆的性质)就需要切断和级联切断。最后更新min,因为x是唯一被改变关键字的元素,所以min只能在原min和x之间。
- 切断:当x小于y,就需要切断xy的链接,并让x成为根节点。并将mark标记为false(未标记,图中白色)(因为这是创建的新关键字不用标记)。
- 级联切断:当x为父节点被切掉的某孩子后剩余的孩子,即父节点被标记,则要将被标记的父节点执行切断(),并递归父节点的上一级。直到遇到未被标记的 / 根节点。
- 摊还:切断实际代价为1,假设需要调用c次级联切断,c-1次的递归调用,实际代价为c。切断让x成为根并切断链接,除了最后一次级联切断每一次使某节点成为根并切断链接。
- 那么根节点=tH(原来根链表节点数)+c-1(除了最后一个其余都调用切断)+1(x)。除了最后一次级联切断其余均被清除标记,最后一次可能标记了节点(不为根且未被标记),mH - (c-1)+1=mH -c+2
- 解释2*mH(被标记节点):2的作用,当标记清空,即执行切断,一个分配给将标记为清除,另一个补偿成为根。
- 将负无穷赋值给要删除的值,min=x。摊还时间为减值和剔除最小值的和,Dn
19.4最大度数界
- 证明有n个节点的堆,任意节点的度数上界Dn=lgn。size表示x本身+以x为根的树的所有节点。
- 引理1:x任意节点,设x的孩子数为k个,y1--yk为x的孩子,这些节点树是被链接到x中的,即它们的树度数相同。要证明y1的孩子数>=0,且i>=2时,孩子数>=i-2。
- 证明:首先孩子树至少为0。对于yi要被联入时,x有i-1个孩子节点,那么yi必然也有i-1个孩子节点。在联入后,至多失去1个孩子,因为如果失去两个孩子,将会执行级联切断。??
- 引理2:3`2节对于第k个元素的斐波那契值Fk。命题:堆k>=0时Fk+2=1+
- 引理3:对于所有k>=0,Fk+2的值>=黄金分隔比1.618……^k。归纳当k=0/1,代入命题,符合命题右侧结果,成立。假设k>=2,代入命题,符合命题右侧结果,成立。
- 引力4:证明size>=Fk+2:
- 让sk表示度数为k的任意节点(孩子数与x的孩子数k一致)的最小size(节点数),当k=0/1孩子的孩子没有 / 确定只有一个 =1/2,sk<=sizex(孩子数最多为x根的节点总数)。
- 让节点z的孩子数=k,且节点数为sk最少节点。现在要求sizex(x的节点数下界范围)即根据堆中的z节点。假设yi被链接到x作为孩子,sizex>=sk相同孩子数的最少节点数>=2(z和z的y1第一个孩子)+
- 假设命题sk>=Fk+2,对于k=01代入命题成立,假设……,转为Fi??代入命题(引理2)
- 证Dn=lgn。n>=size,因为size>=Fk+2,Fk+2的值>=黄金分隔比^k,取对数k(即Dn)<=lg黄金分隔比^n,所以最大的度数为……。
20·章van emde boas树
20.1动态存储方法
- 限制关键字为0---n-1的无重复整数
- 直接寻址:创建位向量数组A(0——n-1)存储全域的关键字(0——u-1)。如果x属于集合,数组A中x为1,否则为0。
- 时间:对于插入/删除操作为1,但其余操作为n
- 叠加二叉树(在A上方,每两个关键字产生一个父,每一个父增加一层高度):数组A作为叶节点,每两个孩子(叶节点)建立父节点(逻辑或)。对于搜索最小/大关键字,从树根按最左/最右搜索包含1的。查找后继/前驱,向上寻找,直到右/左孩子包含1,向下按照最左/右查找包含1的。
- 时间:查找至多两遍树高即lgn
- 叠加高度恒定(所有合并为父的节点与下一层根节点相连,所以结果树的高度总为2)二叉树:让A中全域关键字大小/数量u=2^2k(2的整数倍,即偶数),则可以分解为2^x *2^x=2^x+x(x+x=2k=偶数,这让父的节点树
可以分解为整数值。
- 将
- 搜索最小/大关键字,从树根按最左/最右搜索包含1的。查找后继/前驱,直接在x的簇内查找右/左,若没有找到,对于x的簇i的右/左查找其子数组的左/右。
- 时间:最多
20.2递归结构
- 让全域大小u=2^2^k。
- 我们递归全域结构,以平方根缩减全域,最终降低为2项(基础大小)为止。证明时间:对于递归式全域的时间Tu=T
- 证明时间:顶层需要x=lgu位(2^x=全域u)替换树位,让替换树的大小=x。进行n=lgx次递归后,只剩余1(2减一半=1)(但是对于最小
即为A数组)个节点(因为2^n=x在2的每次平方*2都会为原来的2倍,所以x位需要lgx次变为1),那么lglgu之后,u=2。(将b位大小和全域u关联,lglgu=lgb,即当b位降为1,全域u降为2.
- x的最高位(向下取整)lgu/
20.2.1proto-veb结构20.2.2操作
- 该结构达不到lglgn。对于基础大小:有两位数的组A(表示全域中的每个值是否存在)。其他:某节点的s指针,指向簇。存储数组
- 建立VEB树V和参数x
- 所有递归和参数都不明白含义 ??
查找:
- 如果第一个参数的全域为基础情况,return x位的值。否则递归查找(x所在的簇,和下一次要查找的位)
- 时间:每次查找符合递归式
寻找最小值:
- 基础情况:如果A0为1,返回0位,表示0位有,1同样。 否则让参数=递归查找最小簇V.s号。如果参数为空返回空,否则让偏移变量=簇内最小值(存储数组[参数]), 返回计算(簇,偏移)计算(簇的编号*簇大小=基础位置 +在簇中的偏移=全域中位置)
- 时间:每次调用两次递归 。 主定理:lgn
查找后继
- 基础情况,如果x在0位和1位存在,返回1位,否则为空。非基础:偏移量变量=递归(直到子递归返回值--后继值,回到父递归执行之后计算内容=x索引),如果不为空,返回所在的簇和偏移。否则递归其他簇,如果其他簇为空返回空,否则寻找最小值作为偏移量,返回x索引
- 时间:lgulglgu
插入
- 基础情况,Ax=1.非基础:递归到x的位置,设置为1.回到父并递归插入(s)即把s数组设为1。时间:lgu
20.3VEB树结构即操作
- 全域u=2的幂,当叠加树的大小为非整数,即幂为奇数,下次的叠加树大小分解为上下取整。每个节点有最小值(不出现在节点的簇中)和最大值。对于节点的元素=min+其他存在的元素(包括max)
寻找最小值:直接返回
查找:如果为最大/小值,true。基础情况:false(??没有其他元素),否则递归查找位置
查找后继:
- 基础情况:x为0位,最大值为1,返回1,否则为空。如果x<min,x的后继为min。再否则变量=x簇内最大值,如果最大存在,x在所在簇要查找的偏移量<最大,就递归查看x的后继,返回x的索引。
- 否则说明x>=max,查找其他簇:后继??(节点.s的x的簇位),返回最小偏移。
插入:
- 如果最小为空(max也不存在,否则更新为min)直接插入。
- 否则树不为空,如果x<最小(min应被更新为新的最小),交换两者。如果不为基础情况,并且x所在的簇为空(不包括minmax)那么插入到s数组和所在簇中。如果x>max,max=x。
- (伪代码中else if与下方if并列,而elseif相连的为否则如果)
删除:
- 如果只有一个元素,让min和max为空。基础情况:让min/max只留一个(x可能为0/1)。当簇中有两个及以上:如果x=min(特殊情况),找到参数=min(V.s)树的最小簇,找到参数2=min(存储数组.参数)簇内最小,让min=计算(参数1,参数2)(即x的索引),然后从x所在簇删除x的偏移位置。
- 如果x所在簇删除后为空,将删除V.s中的簇号。如果x=max,参数=最小簇,如果簇为空,就max=min,否则就max=簇内的最大值
- 否则如果x被删除后,树!=null并且x==max,max=计算(簇,簇内的最大值)
21章不相交集合
21.1操作
- 结构:用代表表示每个集合S1---Sk
- x为集合中的元素,支持的操作:
- 创建集合():建立新集合x是唯一元素(集合不相交)
- 合并(x,y):并级,将包含x,y的集合合并
- 返回():指针指向x的集合代表成员
- 时间:n为创建集合操作的总次数,m为所有操作的总次数
- 实例:判断图的两个顶点是否是同一连通分量
- 为所有顶点创建集合,遍历每个边,如果uv两顶点!=,就合并集合。判断,如果两顶点所在集合相等返回true,表示连通
21.2不相交链表
- 每个集合都是一个链表,包含next指针和返回指针(指向集合对象)。合并操作的y中所有元素合并到x的tail,更新所有y对象指向集合代表指针。
- 对应m个操作,中有n个合并(对多执行n-1次合并n个元素)操作,每次合并需要i个对象更改指针,总共需要n^2。总共有m=n(创建)+(n-1)个操作,摊还为n^2 / n=n
- 启发式:加权合并:短表合并到长表。m个操作时间为m+nlgn。证明:因为x在最小表中,如果x被更新指针,说明另一个表>=x的表,则新表至少为原表的2倍。对于lgn(每次是2的平方即翻倍)次后至少有n个成员,则对于每个成员至少被更新lgn次,n个对象时间为nlgn。其余操作时间为Om,则可证
21.3不相交森林
- 没棵树代表一个集合,根节点为代表,指针由叶节点一路向上,根节点的父节点是本身。
- 启发式:短树合并到长树。每个节点直接指向根,且不改变秩。
- x的rank为秩(从叶节点到x本身的高度)。创建为初始秩0。合并:如果秩不同,秩不变。如果秩相同,秩+1。
- 对于查找操作,会不断沿x递归向上查找,直到返回值,回溯将每个x的p更新为最终查找到的根。
- 当同时使用两启发式,时间将为man
21.4时间分析
- 定义作用于x的秩函数Ak(j),1` 当k(操作次数)=0,函数Ak(j)=j+1(上标),2` k>=1,函数Ak(j)=Ak-1^j+1(j)。3` Ak^0(j)=j 4` i>=1时,可分解为Ak-1^i(j)=Ak-1(Ak-1^i-1(j))
- 5` A1(j)=2j+1归纳证明:先证明:A0^i(j)=j+i,对于A0^0(j)=j(根据3`)=j+0(转换),假设A0^i-1(j)=j+(i-1)(满足命题),A0^i(j)=A0(A0^i-1(j)(根据4·)=A0(j+(i-1))=(j+(i-1))+1(根据命题)=j+i(命题成立),因此A1(j)=A0^j+1(j)(根据2)=j+(j+1)=2j+1命题成立
- 6` A2(j)=2^j+1(j+1)-1归纳证明:先证明:A1^i(j)=2^i(j+1)-1,基础A1^0(j)=j(根据3`)=j+2^0(j+1)-1(转换),假设A1^i-1(j)=2^i-1(j+1)-1(满足命题),A1^i(j)=A1(A1^i-1(j)(根据4·)=A1(2^i-1(j+1)-1)=2*((2^i-1(j+1)-1+1)-1(根据命题)=2^i(j+1)-1(命题成立),因此A2(j)=A1+j+1(j)(根据2)==2^j+1(j+1)-1命题成立
- 逆函数变化情况:对于j=1时,k=0,函数=2,k=1,函数=3,k=2,函数=7,k=3,函数=2047(根据2),k=4,函数=10^80。让逆函数an=k=MIN(Ak(1)>=n)(n为函数的值),所有在n<=10^80前,an<=4。
- 性质1·:x.rank<x.p.rank,x的秩随时间增加,直到x不为根,x的秩不发生变化,而x.p随时间增加。
- 性质2:秩最大为n-1:秩从0开始,最多执行n-1次合并,每次合并x的秩不变,而x.p随增加1,所以对于某节点,秩最大为0+(n-1)次=n-1
- 性质3:假设将合并替换为两个查询根节点和和一个链接操作,记前一个操作总和m',记后一个操作总和m,则m'<=m<=3m'。因为m=Om'??,所以时间界man=m'an
- 势函数证明时间:x的势
- 辅助函数1level(x.rank>=1):=k=MAX(Ak(x.rank)<=x.p.rank),证明界:x.p.rank>=x.rank+1(性质1)=A0(x.rank)(函数定义),所以level=MAXk>=k(A0(x.rank))>=0。Aan(x.rank)>=Aan(1)(严格递增性质)>=n(逆函数定义,因为an时MINk,但仍>=n)>x.p.rank(性质2)
- 辅助函数2iter:=i=MAX(Alevel(x)^i(x.rank)<=x.p.rank),证明界:x.p.rank>=Alevel(x)(x.rank)(辅助函数1)==Alevel(x)^1(x.rank)(迭代定义),所以iter(x)>=1。Alevel(x)^x.rank+1(x.rank)=Alevel(x)+1(x.rank)(根据2·)>x.p.rank(辅助函数1),所以iter(x)<=x.rank
- 性质4:由于x.p.rank随时间递增,level(x)也递增。若iter(x)减小,level(x)需要增加。若level(x)不变,iter(x)会不变/增加
- 性质5:势函数:当x是树根,
- 性质6:如果操作为链接/查询,
- 求每个操作的摊还(实际代价+势差):创建:代价1。链接:因为x在连接到y前,这两个节点都是根,
- 查询:查询实际代价为s个路径节点。摊还为s-(an+2)(除了??an+2(2是根节点)个其余都x.rank>=1,所以势会改变)个,且每个减少1,所以=s-(an+2)。现在将x和同路径y(即level操作次数相等)分别转为辅助函数形式,根据严格递增,和3·的性质可的……导致势下降1.
- 因为每个操作摊还Oan,m操作=man
23章最小生成树
23.1形成
- ??对于归纳法理解:证明基础情况成立,假设n情况成立,证明n+1情况将前面两等式代入,符合命题可证,因为代入相当于将式子替换为另一种形式,假设n情况成立,那n+1就可以转化为这种代入后的形式。
- 对于连通(所有节点相连)无向图,每个边包含权重w(长度),求最小(长度最小)生成树(所有节点连通的无环图)。让集合A作为作为最小生成树的子集(长度最小的连通无环图--边集),如果加入的边不会破坏A的性质称为安全边。
- 切割图的点:分为S和V-S部分,如果边连通两部分,称为横跨切割,如果权重最小,称为轻量级边。如果集合A内不存在横跨切割的边,则划分的切割尊重集合A
- 判断是否安全边:假设A最小生成树的子集(连通部分节点),设切割尊重A(A可能为任意一部分),设u,v是横跨切割的一条轻量级边,则对于A是安全的(边加入树T依旧最小,且不会形成环)。
- 证明:
- 设最小生成树T(全部节点被连通)包括A,且不包含轻量级边u,v(分别在切割的两端)。设一条x,y横跨切割,切割将不在A中,如果x,y是唯一横跨切割,那么将u,v替换x,y=T‘。
- 因为u,v是轻量级边,替换后wT'<=wT,则仍是最小生成树(符合安全边的第一性质)
- 因为x,y不属于A,所以A也在T'中,因此加入u,v将属于T',因为是最小生成树,A依旧保持子集性质,所以u,v是安全边
- 对于图的每个节点首次更新为一棵树,每次循环-1棵树,当仅剩一棵终止。
- 判断是否安全边:两棵树(其中一棵是A)的连通边u,v,边相对于被尊重的A是安全的。证明:设切割将划分一棵树尊重A,u,v是是横跨切割的一条轻量级边,那么满足上述证明。
- 也就是说,选择什么样的边能让A保持安全性质呢?需要符合u,v。对于两颗不连通的树,连通后符合无环,如果为轻量级边,则符合最小树。
23.2两种贪心算法
- 算法1
- 在所有连接不同树的边里找到w最小的,加入A中。用不相交集合,将所有顶点建立各自树,对所有边按小至大排序,对于每个边,如果不属于同一棵树,就让边加入到集合A中作为最小生成树的一员。
- 有V个创建,E个合并,所以总时间V+Ean==OElgV??
- 算法2
- 从一个根节点开始找到相邻节点W最小的,加入A中。 节点v.key属性存放连接v的所有边的最小W。和v的属性父节点。最小优先队列Q根据边的W存放。集合A=V-Q。
- ??让所有节点权重为正无穷,父节点为空,让根节点权重为0,在Q中压入所有V。当Q不为空时循环,从Q中选取key值最小节点并弹出Q,遍历每个邻接节点,如果u,v权重小于v.key,就更新v的key值和父节点为u。
- 时间:Q为二叉优先队列,每个查询最小为lgv,那v个需要vlgv,对点的更新需要E次,隐含操作lgv,则时间和vlgv+elgv=elgv。如果用斐波那契,为vlgv+e。
24章单源最短路径——贪心
24.1定义
- 对于带有边权重的有向图,路径的权重wp是路径所有边的权重和。
u,v是两点间的最短路径的权重,当两点间没有路径
正无穷。
- 命题:最短路径子路径也是最短,证明(剪切替换法):假设最短路径p包含子路径p‘,假设wp"<wp',则替换后的p<原p,与假设矛盾,所以不存在更小的子路径,即命题成立
- 对于包含负权重的边,存在最短路径,但如果包含负环路(可以无休止循环达到更小),则无法找到源节点s到其他节点v的最短路径,则v的值记为-
- 对于包含正值环路不是最短路径,对于0环路一定存在其他路径。
- 前驱子图G
,V
- 最短路径树:由s到每个可达到点的一条最短路径。3性质:结点满足s可以到达。子图是以s为根的树。子图上的唯一路径,是原图中最短的路径。
- 建立每个结点的最短路径估计v.d(根据每次寻找更短的路径更新)初始化:v.
24.1算法1,边权重可以为负值
- 初始化,遍历每个点,对点的关联边u,v进行松弛(松弛v),共进行E次。再对边检查是否存在负值环路,如果v.d>
- 证明算法正确性:如果没有负值环路,算法可以计算每个节点的最短路径。对于任意节点vi,代入路径松弛性质,p为(v0---vk)(vk=vi),那么替换则可证所有s可以到达的节点都是最短路径。
- 性质1:算法终止时所有s可达的节点均<
- 性质2:前驱子图是以s为根的最短路径树。证明:性质1:v.d=
- 性质3:如果不包含负值环路将返回true。证明:v.d=
- 性质4:如果包含负值环路将返回false。反证法:假设包含情况返回true,将所有节点求和,(因为返回true,所以满足算法的条件)
24.2拓步排序法
- 拓步排序:从左到右按照边uv依次写出节点。过程:先拓步排序,在依次按顺序遍历每个点的u,v,松弛u的边,从而更新v.d。时间:排序v+e,松弛:e,总时间:v+e
- 证明算法正确性:算法可以计算每个节点的最短路径。因为按照拓步排序,根据路径松弛性质,可证。根据前驱子图性质,将是最短路径树。
24.3算法2边权重为非负值
- 在最小优先队列Q(V-s),将最小的松弛,再加入到s集合中进行松弛。因为每个节点加入到s中只有一次,所以循环次数v次。
- 建立循环不变式证明算法正确性:v.d=
- 初始化成立。保持:反证法:假设u被加入集合,即u不是最短路径,因为一定存在su路径(不存在为
- 时间:加入队列每次需要v,共v个点。和松弛需要e次,v^2+e
- 如果使用二叉堆:剔除最小值需要lgv,共v次。和松弛需要e次,每次lgv,总:(v+e)lgv
- 如果斐波那契:松弛需要e次,每次1.总vlgv+e
24.4差分约束和最短路径
- 线性规划矩阵A(包含-1和1)*x满足<=bk(约束条件),根据矩阵乘法,转换为列个数的等式,矩阵x可以有多个可行解xi--xj
- 约束图:顶点除v0外其余满足x(作为v.d),如果约束条件为xj-xi<=bk,边权重满足约束条件(从xi--xj的关系)wu,v,=bk
- 性质:如果图中没有负值环路,则可找到可行解x(v0到每个节点的最短路径)否则没有可行解。证明:根据三角不等式
- 性质:如果图中有负值环路,则不可找到可行解x。证明:建立负值环路c,把上述不等式求和,0<=wc,但对于负值环路wc<0所以矛盾,因此不满足约束条件,所以不存在可行解
24.5证明
- 三角不等式:对于任何边的
- 上界性质:总有v.d>=下界
- 非路径性质:如果sv不存在路径,则v.d=
- 性质1:如果松弛前v.d>=u,.d+wuv,松弛后v.d=u,.d+wuv(需要变为更小的路径),如果松弛前v.d<=u,.d+wuv,松弛后v.d<=u,.d+wuv(本身为更小,不改变)
- 收敛性质:如果suv是一条最短路径,如果松弛前u.d=
- 路径松弛性质:如果p(v0---vk)是一条最短路径,那么vk.d=
- 前驱子图性质:如果所有节点v.d=
- 性质1:总是形成有根树:
- 性质2:假设不包含负值环路,子图是无环图。假设法:假设再图中创建了环路,那么如果v.d发生变化,根据外侧性质1,v.d>=u,.d+wuv(因为负值的情况,只会不变/减少),求和后0>wc,因此环路为负值,所以如果存在环路就不满足条件。
- 性质3:每个节点都有s到节点的唯一路径。唯一性证明:假设存在x!=y,u.
- 性质:图将是以s为根的最短路径树。对于最短路径树3性质证明:从s可以到达的节点是对于赋予d值的节点,当u!=null时被赋予,所以性质1成立。性质3:假设子图有一个简单路径,根据求和再抵消=
25·uv最短路径——动态规划
25.1矩阵乘法
每次检查边数增加,矩阵内部每行以每个点作为根,每个以n次遍历更新最小
- 邻接矩阵表示n个节点图的边权重W,每个值=wij。最短路径矩阵D=dij,dij表示ij的最短路径权重=
=paiij(ij节点的j的前驱:当不存在路径为null,否则j的前驱),那么第i行由前驱节点构成将是以i为根的最短路径。对于以i为根的前驱子图,V属于paiij!=null,E(i,j)中j不包含i。
- 打印最短路径的所有结点:如果i=j就打印i(只有一条边),否则递归打印路径的前驱结点。
- 分析最优解(递归)结构:根据最短路径p的子路径也是最短路径,假定p包含m条边,那么从K分解将最多包含m-1。
- 定义:l^m(ij)=ij的至多m条边最小权重,l^0(ij),如果相等=0,否则没有路径=
- 性质:l^m(ij)=l^m'(m'>m)(ij),因为ij间最短路径p最多包含m条边,那么包含更多边后,不可能比最短路径边数要多(将取最小),也不能少(路径越多,边数应增加)
- 动态规划:建立最短路径矩阵:L^m=l^m(ij),初始化:当1条边时ij的最短路径=wij(根据m>=1时,(l^m-1(ik)+wkj),因为l^m-1(ik)不存在,所以m=1时=wkj。
- 外循环i每个值(每行表示以i为根),内1循环j(i到j最短路径),首次赋予
- 替换为矩阵乘法:c=a*b,cij初始为0,cij=cij+cik*ckj对应l^m(ij)=l^m-1(ik)+wkj)
- 计算矩阵:循环n-1次(边次),每次L^m矩阵将调用(L^m-1,w),以m条边更新最小值。时间:n^3
- 重复平方矩阵:循环直到m>=n+1,每次循环让m=2m,翻倍增加。L2m=Lm*Lm,当m=n-1时,m共进行lgn次,每次矩阵需要n^3,共lgn个矩阵,也就是n^3lgn
25.2Floyd算法2
每次检查节点数1——k,当检查第k位作为中间节点,前面已经将1——k-1时计算过了
- 最短路径p的ij中间结点(不包含ij)取自1——k(k<n结点数)(结点序列为1——n,中间结点取自意思:不包括k序列以外的结点)。关于k是否取自ij路径上中间结点,没有取自(i到j没有路径),当取自路径p,由于ik取自1——k-1,kj取自1——k-1。
- 建立递归,d^k(ij)=所有中间结点取自1——k的最短路径权重,那么当中间结点取自n个节点时(第n次更新,k=n时),矩阵(每行以第i序列节点作为根)将获得最小权重。
- 外循环n次,并建立相应矩阵,内双循环ijMin((d^k-1(ij),(d^k-1(ik)+d^k-1(kj))),初始化d^0矩阵,均更新为wij。
- 前驱矩阵
权重=
权重<
- 闭包图:如果包含ij路径则作为边e(图G的边),则t^k(ij)将d^k(ij)的关系转化为逻辑
25.3johnson算法3
- 如果边为负值,要另外计算一组非负值边进行算法,以便可以用dijkstra算法(不能求带负权边)(如果直接在每个边加上正数并不合法)。边的新权重性质:如果在p时的最短路径,也是p'时最短路径。边的新权重均为非负值。
- w'=w+hu-hv(到源节点u和v的最短距离),首先证明性质1,让p作为最短路径,w'p=
- 证明当G图有负值环路,G‘也有负值环路。证明:u=v,所以w'c=wc(c为环路的边),所以也存在环路。
- 证明性质2:根据三角不等式,hv<=hu+wuv,所以w'uv>=0,所以新权重一定为正。
- 计算:先建立v0节点,到每个节点权重=0,通过bellman算法将原来的权重进行计算,得到
- 时间:v^2lgv+ve
26最大流
26.1流网络
- 流网络G:有向图(v,e)所有节点,和边每条边有非负容量c,如果包含u,v则不存在v,u.。每个节点都在源s汇t路径上,因此每个节点都与st相连,是连通图。除s外每个都有进入边,所以共v-1条。
- 流f满足两性质:容量限制:(非负性)0<=fu,v<=cu,v。流量守恒
- 反向边/返平行:u,v(属于e)__v,u(不属于e)。具有多个st时,定义超级st,容量
26.2ford方法
- 形象例子:s工厂t仓库,c道路容量f货车运送总量。每当运行一次,途径的道路f都要增加。f可以增加也可以减小,目的是让更多的流发送到t。那么当无法再发送时,就是最大流(最大发送量)。因为当选择路径p货车运送量中途不应该改变,所以每次发送时需要以道路的最小余额作为发送量,否则其余道路将溢出。
- 残存网络Gf:边=为fu,v正向边<cu,v时的额外流量(cfu,v>0&&!=0)。残存容量cfu,v=cu,v-fu,v原边(当u,v属于e)(作为正向u,v方向,原u,v变为反向(暂时不用)),fv,u反向边(当v,u属于e)(将原正向u,v删除,在图Gf中用v,u替换),否则为0。
- 反向边:对于fu,v=cu,v的正向边,包含不存在的反向边(目的对流缩减),反向容量cfv,u=fu,v。图中e对于每边至多2条,ef<2e
- 定义Gf的流为增加流:当u,v属于e,f增f'(f'对f的增加)=fu,v+f'u,v-f'v,u。
- 性质:|f增f'|=|f|+|f'|首先证明:
- f增f'满足容量限制:根据反向边f'v,u(容量限制)<=cfv,u=fu,v,因此f增f'替换后>=0,<=c.成立
- 流量守恒:因为流单独都遵循,求和运算可证
- 计算|f增f'|:根据求值公式和增公式,通过计算可合并为|f|+|f'|
- 增广路径:
- Gf图中的st的简单路径p(无环路回路),cfp(p路径上可以增加的流量最大值)=min(cfu,v(最小正向残存容量)&&u,v属于p),因为fp(p路径的一个流=cfp>=0,所以|f增fp|=|f|+|fp|(正值)>|f||
- 切割:
- 划分S(包含s),和T(包含t)横跨切割净流量:fSt=fu,v-fv,u(u属于Sv属于T)(节点符合的边的流),切割容量:cST=cu,v(u属于Sv属于T)
- 性质1:任意切割的净流量=|f|证明:任意节点(!=st),根据流量守恒移项=0,代入流的值,展开合并,因为v属于S与T,且ST交集null,所以可以分解=fSt 。
- 性质2:通过移除项可得|f|最大流<=cST
- 最大流最小切割:
- 性质3:如果f是最大流则不包含增广路径。证明:如果包含增广,那么fp将对f增加,与f是最大流矛盾。
- 性质4:如果不包含增广则|f|=cST。证明:定义S(s到v路径)T,因为不存在增广,则不存在st路径,因为s属于S,没有路径则t不属于S,则ST为切割,根据性质1|f|=fST 。
- 证明:根据切割公式:(不存在增广意味着没有残存容量)(u属于Sv属于T)fuv=cu,v,和fv,u=0,否则边将属于残存网络的边 ,会产生st路径,会将v至于S中,这会矛盾,所以必须符合条件。代入条件则可证=cST
- 性质5:如果满足|f|=cST则包含最大流,证明:根据性质2,条件满足性质2,则包含最大流。
- ford算法:
- 过程:将所有流初始0,循环在Gf残存网络中寻找增广路径(可能是原来的f<c的u,v边,或者f=c的v,u反向边),每当寻找到一条,找到cfp最小残存容量),根据判断对边增减,如果是正向边=正向f+cfp,如果是反向边=反向f - cfp.当没有可以流通的路径(满的边会取反,因为只能减少无法再增,所以反向边无法流通时停止),找到最大流(流量相加)
- 时间:寻找路径至多最大流|f*|次(因为每次最少+1),每次寻找路径最多e,则=e|f*|
- endoms算法:采用广度搜索最短路径改善寻找路径的次数。让每条边权重为1,
- 性质6:u,v最短路径会随着流量递增而递增
- 证明:如果u,v属于ef(不属于流量递增边)根据三角不等式,和上述定理,
- 性质7:算法运行总次数为ve。证明:关键边:=cfp(每次成为关键边就剔除,直到流减少)。先证明每个边成为关键边至多v/2 -1次。
- 证明:当u,v成为关键边
- 证明:当初始s,u距离至少为0,距离最后一次成为关键边为v-2,因为每次递增2下一次就无法递增。那么每次递增2,总次数为(v-2)/2次即v/2 -1。
- 时间:因为总共有e条边可以成为关键边,关键边总数为Oev,每次寻找最短路径需要e,则总为ve^2
26.3最大二分配
- 在二分图找最大匹配问题,无向图中m属于e,如果m与某v相连(最多只能有一条m的边与v相连,v不能相连两个m),则v由m匹配,最大匹配m是最大匹配v的个数,匹配数m'<=m。将节点划分为lr两部分,
- 建立流网络G’,和st属于网络的v,边为所有边,且赋予单位容量1。在原始图中,每个顶点至少一条边,则边e至少v/2,每两个节点连成一条边。因为流的e‘=e+v(所有左边节点和s相连,右侧和t相连)。如果对于所有流都是整数值(非小数边),则流是整数值。
- 性质:如果m是二分图中的匹配,则流网络存在整数值流,使得|f|=|m|,相反同理。证明:当G‘中的边u,v属于m,则定义su,uv,vt=1,其余边=0.,如果能证明满足流2性质则存在流。因为横跨切割净流量=fu,v-fv,u(fv,u=0)=m根据2节性质1=|f|
- 证明反向论断:设f是整数流,设每个节点只有一条进入边,容量1.因此根据守恒,只有一条流出边,因此对于u恰好仅存在一个v,所以符合m匹配的性质。因为属于m的边f=1,不属于=0,所以|f|=|m|,
- 为了让流可以解决二分图最大匹配问题,希望最大流对应最大匹配。但是流必须符合整数值,根据ford算法,流满足。
- 性质:最大流对应最大匹配。证明:因为流=匹配,假定m是最大匹配,流不是最大流,则存在更大的流f'=m',f=m,f'>f,则m'>m则与m是最大流矛盾。时间:ve
26.4推送——重贴标签
- 过程不遵守流量守恒,
- 形象例子:管道有容量和当前流量,节点高度决定推送方向,将s的高度h定义为v,所有节点上方,t定义为0,其他节点初始与t水平=0。重贴u的h=min邻接节点的高度+1,这里管道u,v必须至少有一个未满.
- 定义高度h,对于所有属于Gf(Vf,Ef)的边(f<=c)的边,hu<=hv+1(u高度至多与v相同)。
- push推送:
- 过程:如果u溢出,u,v路径容量未满,并且hu=hv+1(高度比v大1),则可以向v推送流
f=MIN(ue , cu,v)。则向v推送后对u,v边的流f更新,如果属于e+
- 如果推送后残存容量=0,达到饱和,边将从残存网络消失,否则非饱和操作。因为推送=ue,所以推送后ue=0.
- 重贴标签:
- 如果u.h<=v.h并且如果至少包含一条u出发的边,则hu=MIN(hv)。
- 创建初始流和高度:
- 如果u=s,预流u,v f=cu,v,否则=0. 。高度:如果u=s则,u,h=V,否则=0
- 性质1:只要存在溢出节点,就存在上述2操作。证:当属于残存边,hu<=hv+1,如果不满足推送,根据推送条件则hu=hv+1即hu<=hv,却满足重贴标签条件。
- 证明推送——重贴标签算法正确性(可以求出最大流)
- 性质2:每当重贴,u.h增加至少1.证明:因为重贴标签改变高度,在最初条件u.h<=v.h,改变后u.h<min(v,h)+1(右侧+1改变不等号),所以在重贴后变为v.h+1必定增加。
- 性质3:推送和重贴不影响高度函数(hu<=hv+1)。证明:考虑进入u的节点w,遵循高度函数w.h<=u.h+1,在重贴标签后hu必定增加,所以w.h<u.h+1仍遵守高度函数。在push后=可能增加v,u边因为重贴,所以v.h=u.h-1<=u.h+1符合,考虑可能减少边u,v达到饱和,那么将删除边从而不必再考虑。
- 性质4:在残存网络不存在st路径,证明:反证法:从0——k(k<v)的st路径,因为对于每个节点都遵守高度性质,所以两边求和h.s+……+h.t-1<=……+(h.t-1 +1)+(h.t+1)=抵消后h.s<=h.t+k(每个1加一遍,0--k-1共k个),因为ht=0,所以h.s<=k<v,这与h.s=v矛盾,所以不存在st路径。
- 性质5:证明算法正确性。证明:循环不变式:f始终是预流。证:初始就是预流,while时重贴不影响高度,推送前预流后也预流。那么根据性质1,算法终止不存在溢出节点,根据性质4Gf不存在st路径,则根据最大流最小切割定理,Gf不存在即可推导|f|=cST,则可推导f是最大流。
- 性质:算法会终止。证明:
- 性质6:对于溢出节点存在xs的路径。证明:反证法:U(所有存在xv路径的v节点,s!属于U)U'=v-U。对于eu超额流的求和公式(计算所有uv有路径的边即U),因为v=U并U',所以可以分解为两部分(书中印刷错误❌),因为uv都属于U时表示溢出节点x到两个节点都有可推送路径,则x.h=u.h+1=v.h+1,uv高度相等,所以fuv和fvu=0可删除。
- 证明:s节点超额流es为负值,因为只有流出,但U不包含s,所以其余节点eu>=0为非负??(流入u>流出u),所以求和公式>0,所以移项fvu>0(u属于U,v属于U‘),所以存在流入u的边,所以反向边uv存在,所以xuv路径(v属于U‘),那么与xv存在路径属于U矛盾。
- 性质7:任意时刻hu<=2v-1.证明:st不会大于,初始时高度=0不会大于,当u被重贴标签,则u必定溢出节点(性质1),根据性质6必然存在us的路径p(vo=u,vk=s,k<=v-1,0——v-1是v个),那么u.h<=s.h+k(性质4的求和方法)<=s.h(=v)+(v-1)=2v-1
- 性质8:重贴操作<2v^2次.证明:有v-2(排除st)个节点可能被重贴标签,因为每次重贴增加u.h,根据性质7至多为2v-1,所以相乘=(v-2)*(2v-1)<2v^2
- 性质9:饱和推送<2ve。证明:把从uv和vu的推送称为饱和,一个边饱和删除,因为性质2vh高度不会减少,所以下一次必定vu路径,根据推送条件hu=hv+1,那么要满足hv=hu+1,v要增加2,所以每个边推送次数<2v,共e条边,则<2ve
- 性质10:非饱和推送4v^2(v+e).证明:势函数
- 证明:由于
26.5前置重贴标签
- 许可边uv满足cfuv>0残存容量,hu=hv+1可以流向v。Gfh许可网络。
- 性质1:许可网络是无环的。证明:反证法:如果包含环路(vo--vk,w0=wk,k>0),求和相加:v0=vk+k,(4节性质4)k=0,矛盾
- 性质2:推送操作不会创建许可边,并可能导致u,v非许可。证明:hu=hv+1,所以vu不满足创建条件,如果饱和推送,则uv边消失
- 性质3:至少存在一条从u发出的许可边,重贴后不存在进入u的许可边。证明:如果没有从u发出的许可边,因为u是溢出节点(4节性质1)必定存在重贴操作,hu=hv+1。证明:反证法:加入有一条进入u的许可边v.h>u,h,重贴节点u后仍为许可边,则v.h=u,h+1,所以重贴前v.h>u,h+1(要大于u,h+1才可以),根据性质不符合高度函数定义,则不属于残存边,则不符合许可边
- u,n是有u的邻接边(uv,vu的邻接节点组成的链表)
- 释放操作u=0:
- 过程:释放溢出节点u,让v=邻接链表表头,如果v=null,执行重贴(增加u高度),并考虑表头结点,如果cfuv>0&&hu=hv+1(非null,是许可边)则推送(传流),否则(非null,不是许可边),考虑下一个结点
- 图中右侧顶部显示每一次迭代,只有当结点到null,下一次迭代将从头开始,否则剩下的两情况的下一次迭代都为next。当hu=hv+1,就可以向其推送,(只关心高度,无关uv,vu(减小f))
- 性质4:当调用操作时必须当时使用的操作。证明:对于推送操作有明确条件,所以无需证明。对于重贴操作,条件为null时,根据性质3只要证明从u发出的都是非许可边(不会推送,需要重贴),如果没有推送,uv必须是非许可才能继续考虑下一个边,对于有推送时,性质2不会创建许可边,且不会发生重贴,所以uv是非许可,因此遍历结束所以边都是非许可。
- 前置重贴标签:维持链表L(v!=st),结点按照拓步存放。
- 过程:初始流和高度,循环:记录u.h,找到L中第一个结点,对其进行释放,如果当前的u,h>u.h(进行了重贴),则置于表头,且寻找L中下一位。图右侧下方,每一列代表上方对于L结点的邻接链表。
- 证明算法正确性:
- 性质5:算法过程L中u的前面结点都没有超额流量。证明:初始化u作为表头,前面无结点。过程,首先因为只有重贴才会创建从u发出的边,将u移动到表头,会让L中许可边符合拓步(高度uv从上到下)(普通拓步uv从左到右)。
- 证明:将u的next=u’ ,u‘前包括u(不断寻找下一位),不包括结点(u执行重贴:至于表头),包括结点(u没有重贴),如果对u释放,u将没有超额流量,如果u执行重贴,u’之前的没有超额流量(u),如果u没有执行重贴,则u’之前的结点都没有获得流量,因为拓步排序,推送的流量(由高到低)。
- 时间分析:根据上界性质,每个区段=重贴标签=L更新为head=v^2次,对于每个区段(每次释放操作)最多执行v次,如果没有重贴将看下一位的释放操作,如果重贴看下个区间,对于所有节点v^3次释放操作。
- 证明:对于指针u的更新,当共v个节点发生重贴,作为head,每次u考虑表的下一个节点次数为e。所以ve。
- 证明:如果非饱和操作会立即执行推送(超额流量-0),因此最多执行一次非饱和操作。总时间:v^3+ve=Ov^3



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









