







 本文探讨分布式数据库数据一致性的重要性,并介绍了Raft算法的背景、概述和原理,阐述了如何在SequoiaDB中利用Raft算法实现数据一致性。通过详细解释节点角色、Terms、选举和日志复制等概念,展示了如何在分布式存储中保障数据一致性。此外,还讨论了SequoiaDB在编目和数据分区组中的一致性策略以及用户如何调整数据一致性强度。
本文探讨分布式数据库数据一致性的重要性,并介绍了Raft算法的背景、概述和原理,阐述了如何在SequoiaDB中利用Raft算法实现数据一致性。通过详细解释节点角色、Terms、选举和日志复制等概念,展示了如何在分布式存储中保障数据一致性。此外,还讨论了SequoiaDB在编目和数据分区组中的一致性策略以及用户如何调整数据一致性强度。
前言
分布式数据库的数据一致性管理是其最重要的内核技术之一,也是保证分布式数据库满足数据库最基本的ACID特性中的 “一致性”(Consistency)的保障。在分布式技术发展下,数据一致性的解决方法和技术也在不断的演进,本文就以作者实际研发的分布式数据库作为案例,介绍分布式数据库数据一致性的原理以及实际实现。
1.数据一致性
1.1数据一致性是什么
大部份使用传统关系型数据库的DBA在看到“数据一致性”时,第一反应可能都是数据在跨表事务中的数据一致性场景。但是本文介绍的“数据一致性”,指的是“数据在多份副本中存储时,如何保障数据的一致性”场景。
由于在大数据领域,数据的安全不再由硬件来保证,而是通过软件手段,通过同时将数据写入到多个副本中,来确保数据的安全。数据库在同时向多个副本写入记录时,如何确保每个副本数据一致,称为“数据一致性”。
1.2关系型数据库如何保障数据一致性
传统的关系型数据库对于运行环境--硬件要求都比较高,例如Oracle会建议用户使用小型机+共享存储作为数据库的运行环境,DB2 DPF也同样建议用户采用更好的服务器+高端存储来搭建数据库的运行环境。所以在数据存储安全的技术要求下,传统关系型数据库更多是依赖硬件的技术来保障数据的安全性。
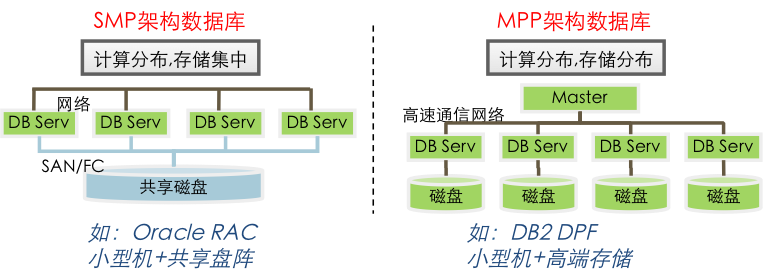
因为关系型数据库的数据安全是基于硬件来保障,并且数据也不会通过同时存储多份来保障数据的安全,所以关系型数据库的用户默认认为数据存储是一致的。
1.3分布式存储如何保障数据一致性
本文在讨论分布式存储时,主要指的是大数据产品中的分布式文件系统和分布式数据库,例如:SequoiaDB和HDFS。
用户在搞明白分布式存储的数据一致性原理时,必须要先明白为什么他们就需要数据一致性,和分布式存储的数据存储与关系型数据库的数据存储又有什么区别。
大数据技术的诞生,确确实实让系统的性能有新的突破,并且支持硬件以水平扩展的方式来获得线性增长的性能和存储。这些都是过去传统关系型数据库所无法提供的。另外,大数据技术也抛弃了运行环境必须足够好的硬性要求,而是允许用户通过批量廉价X86服务器+本地磁盘的方式搭建规模集群,从而获得比过去依赖硬件垂直扩展所提供的更强的计算能力和更多的存储空间。
大数据技术的核心思想就是分布式,将一个大的工作任务分解成多个小任务,然后通过分布式并发操作的方式将其完成,从而提高整个系统的计算效率或者是存储能力。而在分布式环境下,由于硬件的要求降低,必然需要大数据产品提供另外一个重要的功能--数据安全。
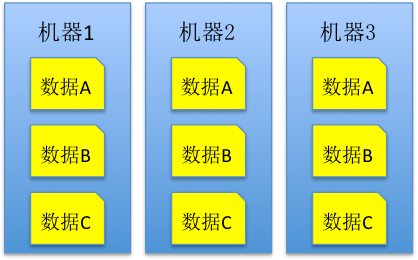
大数据产品在解决数据安全的方式上,都比较接近,简单来说,就是让一份数据通过异步或者同步的方式保存在多台机器上,从而保障数据的安全。
分布式存储在解决数据安全的技术难点后,又引入了一个新的技术问题,就是如何保障多个副本中的数据一致性。目前SequoiaDB是使用Raft算法来保证数据在多个副本中一致性。
2.Raft算法
2.1Raft算法背景
在分布式环境下,最著名的一致性算法应该是Paxos算法,但是由于它实在过于晦涩难懂,并且实现起来极度困难,所以在2013年,Diego Ongaro、John Ousterhout两个人以易懂(Understandability)为目标设计了一套一致性算法Raft。Raft算法最大的特点在于简单易懂,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 406
406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









