







目录
1、什么是Huffman树?
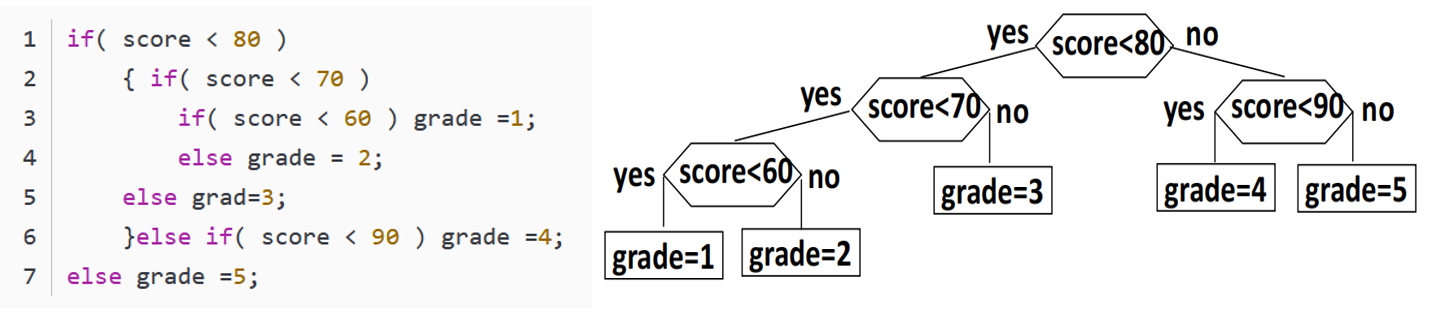
【例】将百分制的考试成绩转换成五分制的成绩,代码如下
if(score< 60)grade=1;
else if(score< 70)grade=2;
else if(score< 80)grade=3;
else if(score< 90)grade=4;
else grade=5;
若学生成绩分布比例如下:

计算查找效率,做出判定树:

查找效率= 0.05×1+0.15×2+0.4×3+0.3×4+0.1×4 =3.15
修改查找代码与判定树形态,得查找效率=0.05×3+0.15×3+0.4×2+0.3×2+0.1× 2=2.2
思考:如何根据结点不同的查找频率构造更有效的搜索树?
2、Huffman树的定义
路径长度:两个结点之间路径上的分支数
树的外部路径长度:各叶结点到根结点的路径长度之和
树的内部路径长度:各非叶结点到根结点的路径长度之和
带权路径长度(WPL):设二叉树有n个叶子结点,每个叶子结点带有权值 ,从根结点到每个叶子结点的长度为
,则每个叶子结点的带权路径长度之和
Huffman树(最优二叉树):带权(外部)路径(Weighted PathLength)长度最短的树
【例】有五个叶子结点,它们的权值为{1,2,3,4,5},用此权值序列可以构造出形状不同的多个二叉树。可以计算下面二叉树的带权路径长度

根据上述计算可以得到初步结论:“权”大的叶结点深度小,它相对于总路径长度的花费最小,因此,其他叶结点如果"权"小,就会被推到树的较深处。
3、Huffman树的构造
步骤:
- 根据给定的n个权值 {
,
, . . . ,
},构造n棵二叉树的集合 F = {
,
, . . . ,
} ,其中每棵二叉树中均只含一个带权值为
的根结点,其左、右子树为空树;
- 在F中选取其根结点的权值为最小的两棵二叉树,分别作为左、右子树构造一棵新的二叉树,并置这棵新的二叉树根结点的权值为其左、右子树根结点的权值之和;
- 从F中删去这两棵树,同时加入刚生成的新树,参与新的排序;
- 重复(2)和(3)两步,直至F中只含一棵树为止。
【例】给定权值为{1,2,3,4,5}的叶节点,根据上述步骤合并。

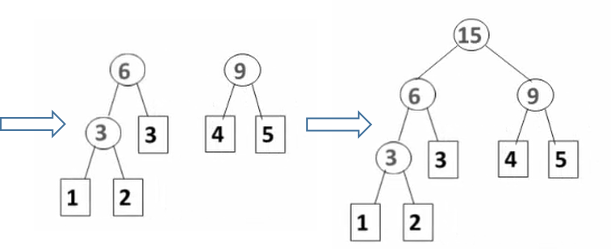
代码实现①用冒泡排序实现
public class Element { //建立元素的类类型存储其值与频率
private char element; //元素
private double weight; //出现的频率
public Element(char element, double weight) {
this.element = element;
this.weight = weight;
}
public char getElement() {
return element;
}
public void setElement(char element) {
this.element = element;
}
public double getWeight() {
return weight;
}
public void setWeight(double weight) {
this.weight = weight;
}
}public class HuffmanTreeNode implements Comparable<HuffmanTreeNode> {//建立子树的结点类类型
Element Element;
HuffmanTreeNode left;//左子结点
HuffmanTreeNode right;//右子结点
public HuffmanTreeNode(Element element, HuffmanTreeNode left, HuffmanTreeNode right) {
this.Element = element;
this.left = left;
this.right = right;
}
public Element getElement() {
return Element;
}
public void setElement(Element Element) {
this.Element = Element;
}
public HuffmanTreeNode getLeft() {
return left;
}
public void setLeft(HuffmanTreeNode left) {
this.left = left;
}
public HuffmanTreeNode getRight() {
return right;
}
public void setRight(HuffmanTreeNode right) {
this.right = right;
}
@Override
public int compareTo(HuffmanTreeNode node) {
if (this.Element.getWeight() == node.Element.getWeight())
return 0;
if (this.Element.getWeight() > node.Element.getWeight())
return 1;
else
return -1;
}
}public class HuffmanTree {
public HuffmanTreeNode generateHuffTree(Element[] Elements) {
//设置传入的元素初始化为单个结点的HuffmanTree,nodes[n]表示n棵独立的 Huffman树 组
HuffmanTreeNode[] nodes = new HuffmanTreeNode[Elements.length];
for (int i = 0; i < Elements.length; i++)
nodes[i] = new HuffmanTreeNode(Elements[i], null, null);
//依次构建Huffman树
while (nodes.length > 1) {
bubbleSort(nodes);//每次删除、插入新树后都需要重排序
//取出Huffman树 组中频率最小的两棵树,组成一棵新的Huffman树
Element newElemnt = new Element('0', nodes[0].getElement().getWeight() + nodes[1].getElement().getWeight());//新树的根结点中不存储该元素的内容,只存储该元素频率。
HuffmanTreeNode newTree = new HuffmanTreeNode(newElemnt, nodes[0], nodes[1]);//新树的左右子树为取出的两棵Huffman树
//删除取出的两棵树并加入新生成那棵的Huffman树
HuffmanTreeNode[] newNodes = new HuffmanTreeNode[nodes.length - 1]; //新的Huffman树 数组,长度减一
for (int i = 0; i < newNodes.length - 1; i++) {
newNodes[i] = nodes[i + 2];
}
newNodes[newNodes.length - 1] = newTree; //新树插在最末尾
nodes = newNodes;
}
return nodes[0];
}
private void bubbleSort(HuffmanTreeNode[] array) {
boolean flag = true; //剪枝:若在当前排序中没有出现逆序对(即不发生交换),则表明当前数组已经有序,退出排序过程
for (int i = 0; flag && (i < array.length - 1); i++) {
flag = false;
for (int j = array.length - 1; j > i; j--) {
if (array[j - 1].compareTo(array[j]) > 0) {
HuffmanTreeNode temp = array[j];
array[j] = array[j - 1];
array[j - 1] = temp;
flag = true;
}
}
}
}
public void print(HuffmanTreeNode root, String code) {
if (root != null) {
print(root.getLeft(), code + "0");
print(root.getRight(), code + "1");
if (root.getLeft() == null && root.getRight() == null) {
String m = "Element:" + root.getElement().getElement() + " 频数:" + root.getElement().getWeight() + " 哈夫曼编码:" + code;
System.out.println(m);
}
}
}
public static void main(String[] args) {
Element a = new Element('a', 1);
Element g = new Element('g', 1);
Element h = new Element('h', 1);
Element l = new Element('l', 1);
Element n = new Element('n', 1);
Element t = new Element('t', 1);
Element i = new Element('i', 4);
Element s = new Element('s', 5);
Element[] test = {a, g, h, l, n, t, i, s};
HuffmanTree huffmanTree = new HuffmanTree();
huffmanTree.print(huffmanTree.generateHuffTree(test), "");
}
}代码实现②用堆实现
public class MinHeap<E extends Comparable<E>> {
private static final int DEFAULT_CAPACITY = 10;//默认大小
public int currentSize;//当前堆的大小,也是当前存放的末尾元素位置
private E[] array;//堆数组
//constructor部分,(考虑到表达的精简性,0不存储,从1开始存储元素)。
public MinHeap() {
this.array = (E[]) new Object[DEFAULT_CAPACITY + 1];
currentSize = 0;
}
public MinHeap(int maxSize) {
this.array = (E[]) new Object[maxSize + 1];
currentSize = 0;
}
public MinHeap(E[] array) {
this.array = (E[]) new Object[array.length + 1];
for (int i = 0; i < array.length; i++) {
this.array[i + 1] = array[i];
}//从1开始算
currentSize = array.length;
buildHeap();
}
public void insert(E item) {
if (isFull()) {
System.out.println("heap is full!");
return;
}
int temp = ++currentSize;//temp指向当前要插入的位置
while ((temp != 1) && (item.compareTo(array[getParent(temp)]) < 0)) {
array[temp] = array[getParent(temp)]; //如果非根节点且插入元素比父结点的键值小,则向下过滤父结点
temp = getParent(temp);
}
array[temp] = item; //将item插入
}
public E deleteMin() {
if (isEmpty()) {
System.out.println("heap is empty!");
return null;
}
E maxItem = array[1];
E itemFill = array[currentSize--];//用堆中最后一个元素从根结点开始向上过滤下层结点
//删除了堆中唯一的元素的情况:此时currentSize==0,下述代码也可以满足该情况,无需单独判断
int tempFill = 1;
while (!isLeaf(tempFill)) { //不是叶子结点,则必定有左子结点
int child = tempFill * 2; //child定位到填补位置的左子结点处
if ((child != currentSize) && (array[child].compareTo(array[child + 1]) > 0))
child++; //若有右结点,child指向左右子结点的较小者
if (itemFill.compareTo(array[child]) > 0) {
array[tempFill] = array[child]; //若不满足有序性(itemFill比左右子结点的较小者大),将左右子结点中的较小者向上过滤
tempFill = child; //tempFill始终指向要填补的位置,下移一层
} else
break;
}
array[tempFill] = itemFill;
return maxItem;
}
public void buildHeap() {
for (int i = currentSize / 2; i > 0; i--) { //从非叶子结点开始从右到左,从下到上调整直至根结点
int temp = i; //记录当前调整元素应放置的位置
E item = array[temp]; //临时存储下当前位置的元素值
while (!isLeaf(temp)) { //不是叶子结点,则必定有左子结点
int child = temp * 2; //child定位到填补位置的左子结点处
if ((child != currentSize) && (array[child].compareTo(array[child + 1]) > 0))
child++; //若有右结点,child指向左右子结点的较小者
if (item.compareTo(array[child]) > 0) {
array[temp] = array[child]; //若不满足有序性(itemFill比左右子结点的较小者大),将左右子结点中的较小者向上过滤
temp = child; //tempFill始终指向要填补的位置,下移一层
} else
break;
}
array[temp] = item;
}
}
public boolean isFull() {
return currentSize == array.length - 1;
}
public boolean isEmpty() {
return currentSize == 0;
}
private int getParent(int i) {
return i / 2;
}
private boolean isLeaf(int i) {
return i * 2 > currentSize;
}
}public HuffmanTreeNode generateHuffTreeByHeap(Element[] Elements) {
//设置传入的元素初始化为单个结点的HuffmanTree,nodes[n]表示n棵独立的 Huffman树 组
HuffmanTreeNode root;
HuffmanTreeNode[] nodes = new HuffmanTreeNode[Elements.length];
for (int i = 0; i < Elements.length; i++)
nodes[i] = new HuffmanTreeNode(Elements[i], null, null);
//以HuffmanTree数组建立堆
MinHeap<HuffmanTreeNode> minHeap = new MinHeap<HuffmanTreeNode>(nodes);
while(minHeap.currentSize!=1){
//取出Huffman树 组中频率最小的两棵树,组成一棵新的Huffman树
HuffmanTreeNode node1= minHeap.deleteMin();
HuffmanTreeNode node2=minHeap.deleteMin();//弹出两个最小的
Element newElemnt = new Element('0',node1.getElement().getWeight()+node2.getElement().getWeight());
//新树的根结点中不存储该元素的内容,只存储该元素频率。
HuffmanTreeNode newTree = new HuffmanTreeNode(newElemnt, node1, node2);//新树的左右子树为取出的两棵Huffman树
minHeap.insert(newTree); //生成的新树插入堆中
}
root= minHeap.deleteMin();
return root;
}4、Huffman树的性质
1️⃣ 没有度为1的结点;
2️⃣ n个叶子结点的哈夫曼树共有2n-1个结点;(性质1的拓展结论)
3️⃣ Huffman树的任意非叶节点的左右子树交换后仍是哈夫曼树;
4️⃣ 对同一组权值{,
, …… ,
},可能存在不同构的两棵哈夫曼树。

5、Huffman编码
给定一段字符串,如何对字符进行编码,可以使得该字符串的编码存储空间最少?
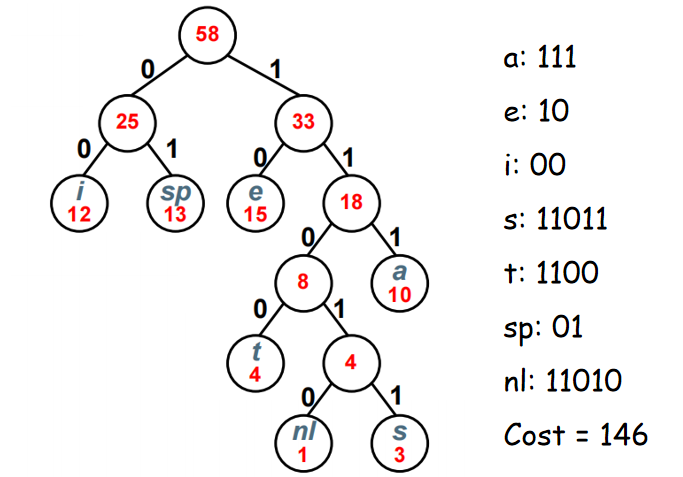
【例】假设有一段文本,包含58个字符,并由以下7个字符构成:a,e,i,s,t,空格(sp),换行(nl)。这7个字符出现的次数不同,分别为10,15,12,3,4,13,1。如何对这7个字符进行编码,使得总编码空间最少?
【分析】
(1)用等长ASCII编码:58 ×8 = 464位;
(2)用等长3位编码:58 ×3 = 174位;
(3)不等长编码:出现频率高的字符用的编码短些,出现频率低的字符则可以编码长些。
Q:进行不等长编码,如何避免二义性?

A:使用Huffman树编制的代码具有前缀特性(前缀码prefix code):任何字符的编码都不是另一字符编码的前缀
所有字符都放在叶结点上,可以无二义地解码。
按照字母出现的频度创建一个Huffman树,可以得到字符的编码如下:
6、Huffman树的应用——生成非等概率随机数
【例】按照给定的概率生成相应的随机数:例如,有1、2、3、4、5、6这6个数,编写一个随机发生器,使其能够按照如下概率(0.15、0.20、0.10、0.30、0.12和0.13)生成相应的6个数。
【分析】由于六个数的概率之和为1,可以使用JavaAPI中的随机数生成函数,产生[0,1)之间等概率的随机数,用产生的随机数指向要求产生数的概率值范围内的数,即为当前生成的非等概率随机数。
对于此判断可进一步优化:使用Huffman树减少比较次数

代码实现:
public static int randomGenerate() {
double temp = Math.random();
int result = 0;
if (temp < 0.42) {
if (temp < 0.22) {
if (temp < 0.10) result = 3;
else result = 5;
} else result = 2;
} else {
if (temp < 0.72) result = 4;
else {
if (temp < 0.85) result = 6;
else result = 1;
}
}
return result;
}













 221
221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









