






为什么哈夫曼编码输出错误,有没有大神求解?
问题:
【问题描述】给定叶子结点的个数以及对应权值,构造哈夫曼树(序号小的做左子树),输出哈夫曼树对应的静态三叉链表;计算每个叶子结点的编码(左0右1)并输出。
【输入形式】输入叶子结点的个数以及对应权值。
【输出形式】显示结点序号,输出哈夫曼树的静态三叉链表(序号后面加冒号,静态三叉链表中元素之间用空格隔开,每个结点占一行);显示叶子结点的权值和对应的编码(叶子结点的权值后面加冒号,每个编码占一行)。
代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define N 5//叶子结点最大值
#define M 2 * N-1//所有结点最大值
typedef struct
{
int weight;//结点权值
int parent;//双亲下标
int LChild;//左孩子结点下标
int RChild;//右孩子结点下标
}HTNode,HuffmanTree[M+1];//HuffmanTree是一个结构数组类型0号单元不用*
typedef char * HuffmanCode[N+1];
void selects(HuffmanTree ht,int n,int *m1,int *m2)
{//找parent为0且权值最小的两个结点
int i=1,temp;
while(ht[i].parent>0)
i++;
*m1=i;
i++;
while(ht[i].parent>0)
i++;
*m2=i;
i++;
if(ht[*m1].weight>ht[*m2].weight)
{
temp=*m1;
*m1=*m2;
*m2=temp;
}
while(i<=n)
{
if(ht[i].parent==0)
{
if(ht[i].weight<ht[*m1].weight)
{
*m2=*m1;
*m1=i;
}
else if(ht[i].weight<ht[*m2].weight)
*m2=i;
}
i++;
}
}
//创建哈夫曼树
void CrtHuffmanTree(HuffmanTree ht,int w[],int n)
{
int s1,s2,i,m;
for(i=1;i<=n;i++)
{
ht[i].weight=w[i];
ht[i].parent=0;
ht[i].LChild=0;
ht[i].RChild=0;
}
m=2*n-1;
for(i=n+1;i<=m;i++)
{
ht[i].weight=0;
ht[i].parent=0;
ht[i].LChild=0;
ht[i].RChild=0;
}
for(i=n+1;i<=m;i++)
{
selects(ht,i-1,&s1,&s2);
ht[i].weight=ht[s1].weight+ht[s2].weight;
ht[s1].parent=i;
ht[s2].parent=i;
ht[i].LChild=s1;
ht[i].RChild=s2;
}
}
//哈夫曼编码
void CrtHuffmanCode(HuffmanTree ht,HuffmanCode hc,int n)
{
int i,c,p,start;
char *cd;
cd=(char*)malloc(n*sizeof(char));
cd[n-1]='\0';
for(i=1;i<=n;i++)
{
start=n-1;
c=i;
p=ht[i].parent;
while(p!=0)
{
--start;
if(ht[p].LChild==c) cd[start]='0';
else
cd[start]='1';
c=p;
p=ht[p].parent;
}
hc[i]=(char*)malloc((n-start)*sizeof(char));
strcpy(hc[i],&cd[start]);
}
free(cd);
}
int main()
{
int weight[N+1],i;
for(i=1;i<=N;i++)
scanf("%d",&weight[i]);
HuffmanTree t;
HuffmanCode code;
CrtHuffmanTree(t,weight,N);
printf("HuffmanTree is:\n");
for(i=1;i<=2*N-1;i++)
printf("%d:%d %d %d %d\n",i,t[i].weight,
t[i].parent,t[i].LChild,t[i].RChild);
CrtHuffmanCode(t,code,N);
printf("The Code is:\n");
for(i=1;i<=N;i++)
printf("%d:%s\n",weight[i],code[i]);
return 0;
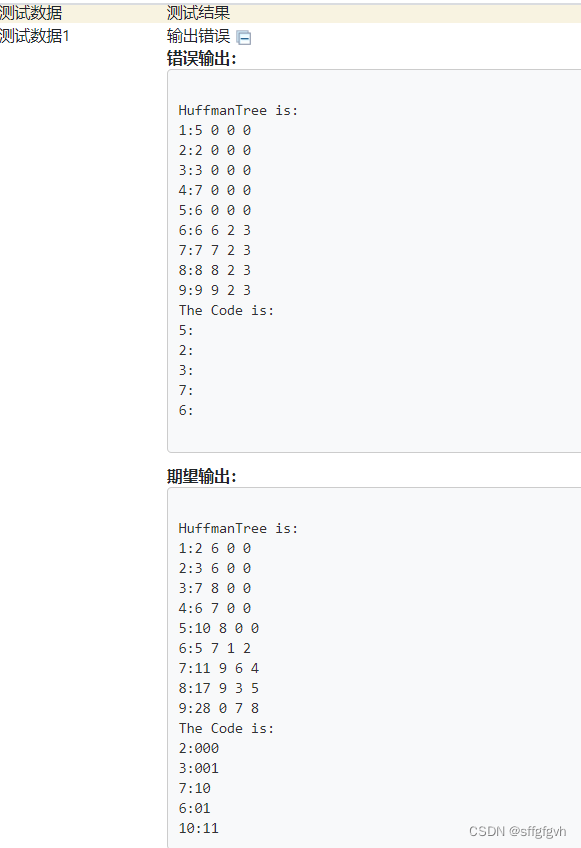
}















 29万+
29万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









