







人工智能
二、岭回归
1. 岭回归
- 普通线性回归模型使用基于梯度下降的最小二乘法,在最小化损失函数的前提下,寻找最优模型参数,于此过程中,包括少数异常样本在内的全部训练数据都会对最终模型参数造成程度相等的影响,异常值对模型所带来影响无法在训练过程中被识别出来。为此,岭回归在模型迭代过程所依据的损失函数中增加了正则项,以限制模型参数对异常样本的匹配程度,进而提高模型面对多数正常样本的拟合精度。
import sklearn.linear_model as lm
# 创建模型
model = lm.Ridge(正则强度, fit_intercept=是否训练截距, max_iter=最大迭代次数)
# 训练模型
# 输入为一个二维数组表示的样本矩阵
# 输出为每个样本最终的结果
model.fit(输入, 输出)
# 预测输出
# 输入array是一个二维数组,每一行是一个样本,每一列是一个特征
result = model.predict(array)
2. 案例:根据工作经验预测薪资
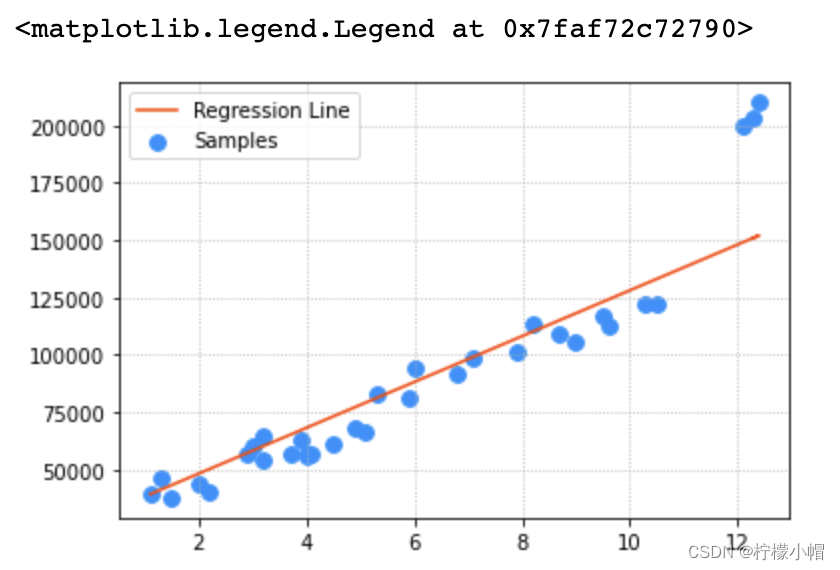
- 为样本数据添加强势样本,观察这些强势样本对线性回归模型的影响。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 加载数据集
data = pd.read_csv('Salary_Data2.csv')
x,y = data['YearsExperience'],data['Salary']
plt.grid(linestyle=':')
plt.scatter(x,y, s=60, color='dodgerblue', label='Samples')

# 基于sklearn提供的API,训练线性回归模型
import sklearn.linear_model as lm
train_x, train_y = pd.DataFrame(x),y
# 使测试样本得分最优的那个模型超参数就是最终选取的模型超参数
model = lm.Ridge(100)
model.fit(train_x, train_y)
# 针对所有训练样本,执行预测操作,绘制回归线
pred_train_y = model.predict(train_x)
# 可视化
plt.grid(linestyle=':')
plt.scatter(x,y, s=60, color='dodgerblue', label='Samples')
plt.plot(x, pred_train_y, color='orangered', label='Regression Line')
plt.legend()
# 调整岭回归的参数
params = np.arange(60, 130, 5)
for param in params:
model = lm.Ridge(param)
model.fit(train_x, train_y)
test_x, test_y = train_x.iloc[:30:4], train_y[:30:4]
pred_test_y = model.predict(test_x)
# 评估误差
print(param, '->', sm.r2_score(test_y, pred_test_y))
"""
60 -> 0.9079377012464043
65 -> 0.9103517840843116
70 -> 0.9123556127607111
75 -> 0.9139751047288491
80 -> 0.9152344834900279
85 -> 0.9161564017114545
90 -> 0.9167620543385843
95 -> 0.9170712826050363
100 -> 0.9171026697534421
105 -> 0.9168736292005816
110 -> 0.9164004858087551
115 -> 0.9156985508615196
120 -> 0.9147821912848049
125 -> 0.9136648936032749
"""
# 超参数为100最优
三、多项式回归
1. 问题
- 线性模型的表达能力有限,当模型拟合度不够,如何进一步提高模型表达能力?
- 可以尝试提高模型复杂度,使用复杂模型来拟合样本分布。
2. 什么是多项式回归
- 线性回归适用于数据呈线性分布的回归问题.如果数据样本呈明显非线性分布,线性回归模型就不再适用(下图左),而采用多项式回归可能更好(下图右).例如:

3. 多项式模型定义
-
与线性模型相比,多项式模型引入了高次项,自变量的指数大于1,例如一元二次方程:
y = w 0 + w 1 x + w 2 x 2 y = w_0 + w_1x + w_2x^2 y=w0+w1x+w2x2
一元三次方程:
y = w 0 + w 1 x + w 2 x 2 + w 3 x 3 y = w_0 + w_1x + w_2x^2 + w_3x ^ 3 y=w0+w1x+w2x2+w3x3
推广到一元n次方程:
y = w 0 + w 1 x + w 2 x 2 + w 3 x 3 + . . . + w n x n y = w_0 + w_1x + w_2x^2 + w_3x ^ 3 + ... + w_nx^n y=w0+w1x+w2x2+w3x3+...+wnxn
上述表达式可以简化为:
y = ∑ i = 1 N w i x i y = \sum_{i=1}^N w_ix^i y=i=1∑Nwixi -
多项式一般形式如下:
y = w 0 + w 1 x + w 2 x 2 + w 3 x 3 + . . . + w d x d y = w_0 + w_1x + w_2x^2 + w_3x ^ 3 + ... + w_dx ^ d y=w0+w1x+w2x2+w3x3+...+wdxd
将自变量的高次项看做对一次项特征的扩展则可以把上式看做:
y = w 1 x 1 + w 2 x 2 + w 3 x 3 + . . . + w d x d y = w_1 x_1 + w_2 x_2 + w_3 x_3 + ... + w_d x_d y=w1x1+w2x2+w3x3+...+wdxd
那么一元多项式回归即可以看做为多元线性回归
可以使用LinearRegression模型对样本数据进行模型训练。
4. 与线性回归的关系
-
多项式回归可以理解为线性回归的扩展,在线性回归模型中添加了新的特征值.例如,要预测一栋房屋的价格,有 x 1 , x 2 , x 3 x_1, x_2, x_3 x1,x2,x3三个特征值,分别表示房子长、宽、高,则房屋价格可表示为以下线性模型:
y = w 1 x 1 + w 2 x 2 + w 3 x 3 + b y = w_1 x_1 + w_2 x_2 + w_3 x_3 + b y=w1x1+w2x2+w3x3+b
对于房屋价格,也可以用房屋的体积,而不直接使用 x 1 , x 2 , x 3 x_1, x_2, x_3 x1,x2,x3三个特征:
y = w 0 + w 1 x + w 2 x 2 + w 3 x 3 y = w_0 + w_1x + w_2x^2 + w_3x ^ 3 y=w0+w1x+w2x2+w3x3
相当于创造了新的特征 x , x x, x x,x = 长 * 宽 * 高. 以上两个模型可以解释为: -
房屋价格是关于长、宽、高三个特征的线性模型
-
房屋价格是关于体积的多项式模型
-
因此,可以将一元n次多项式变换成n元一次线性模型.
5. 多项式回归实现
5.1 多项式回归实现步骤
- 针对一元多项式回归问题中自变量做特征扩展,转换为多元线性回归问题(只需给出多项式最高次数即可)。
- 将①步骤得到的特征扩展后的结果作为训练样本,交给线性回归器训练多元线性模型。
5.2 使用 sklearn 提供的数据管线实现两个步骤的顺序执行
import sklearn.pipeline as pl
import sklearn.preprocessing as sp
import sklearn.linear_model as lm
model = pl.make_pipeline(
sp.PolynomialFeatures(10), # 多项式特征扩展器
lm.LinearRegression()) # 线性回归器
- 对于一元n次多项式,同样可以利用梯度下降对损失值最小化的方法,寻找最优的模型参数 w 0 , w 1 , w 2 , . . . , w n w_0, w_1, w_2, ..., w_n w0,w1,w2,...,wn.可以将一元n次多项式,变换成n元一次多项式,求线性回归.以下是一个多项式回归的实现.
# 多项式回归示例
import numpy as np
# 线性模型
import sklearn.linear_model as lm
# 模型性能评价模块
import sklearn.metrics as sm
import matplotlib.pyplot as mp
# 管线模块
import sklearn.pipeline as pl
import sklearn.preprocessing as sp
train_x, train_y = [], [] # 输入、输出样本
with open("poly_sample.txt", "rt") as f:
for line in f.readlines():
data = [float(substr) for substr in line.split(",")]
train_x.append(data[:-1])
train_y.append(data[-1])
train_x = np.array(train_x) # 二维数据形式的输入矩阵,一行一样本,一列一特征
train_y = np.array(train_y) # 一维数组形式的输出序列,每个元素对应一个输入样本
# print(train_x)
# print(train_y)
# 将多项式特征扩展预处理,和一个线性回归器串联为一个管线
# 多项式特征扩展:对现有数据进行的一种转换,通过将数据映射到更高维度的空间中
# 进行多项式扩展后,我们就可以认为,模型由以前的直线变成了曲线
# 从而可以更灵活的去拟合数据
# pipeline连接两个模型
model = pl.make_pipeline(sp.PolynomialFeatures(3), # 多项式特征扩展,扩展最高次项为3
lm.LinearRegression())
# 用已知输入、输出数据集训练回归器
model.fit(train_x, train_y)
# print(model[1].coef_)
# print(model[1].intercept_)
# 根据训练模型预测输出
pred_train_y = model.predict(train_x)
# 评估指标
err4 = sm.r2_score(train_y, pred_train_y) # R2得分, 范围[0, 1], 分值越大越好
print(err4)
# 在训练集之外构建测试集
test_x = np.linspace(train_x.min(), train_x.max(), 1000)
pre_test_y = model.predict(test_x.reshape(-1, 1)) # 对新样本进行预测
# 可视化回归曲线
mp.figure('Polynomial Regression', facecolor='lightgray')
mp.title('Polynomial Regression', fontsize=20)
mp.xlabel('x', fontsize=14)
mp.ylabel('y', fontsize=14)
mp.tick_params(labelsize=10)
mp.grid(linestyle=':')
mp.scatter(train_x, train_y, c='dodgerblue', alpha=0.8, s=60, label='Sample')
mp.plot(test_x, pre_test_y, c='orangered', label='Regression')
mp.legend()
mp.show()
- 打印输出
0.9224401504764776
- 执行结果

6. 欠拟合与过拟合
- 过于简单的模型,无论对于训练数据还是测试数据都无法给出足够高的预测精度,这种现象叫做欠拟合。
- 过于复杂的模型,对于训练数据可以得到较高的预测精度,但对于测试数据通常精度较低,这种现象叫做过拟合。
- 一个性能可以接受的学习模型应该对训练数据和测试数据都有接近的预测精度,而且精度不能太低。
6.1 现象
训练集R2 测试集R2
0.3 0.4 欠拟合:过于简单,无法反映数据的规则
0.9 0.2 过拟合:过于复杂,太特殊,缺乏一般性
0.7 0.6 可接受:复杂度适中,既反映数据的规则,同时又不失一般性
6.2 什么是欠拟合、过拟合
- 多项式回归示例中,多项特征扩展器PolynomialFeatures()进行多项式扩展时,指定了最高次数为3,该参数为多项式扩展的重要参数,如果选取不当,则可能导致不同的拟合效果.下图显示了该参数分别设为1、20时模型的拟合图像:

这两种其实都不是好的模型. 前者没有学习到数据分布规律,模型拟合程度不够,预测准确度过低,这种现象称为“欠拟合”;后者过于拟合更多样本,以致模型泛化能力(新样本的适应性)变差,这种现象称为“过拟合”. 欠拟合模型一般表现为训练集、测试集下准确度都比较低;过拟合模型一般表现为训练集下准确度较高、测试集下准确度较低. 一个好的模型,不论是对于训练数据还是测试数据,都有接近的预测精度,而且精度不能太低.
6.3 思考
【思考1】以下哪种模型较好,哪种模型较差,较差的原因是什么?
| 训练集R2值 | 测试集R2值 |
|---|---|
| 0.6 | 0.5 |
| 0.9 | 0.6 |
| 0.9 | 0.88 |
【答案】第一个模型欠拟合;第二个模型过拟合;第三个模型适中,为可接受的模型.
【思考2】以下哪个曲线为欠拟合、过拟合,哪个模型拟合最好?

【答案】第一个模型欠拟合;第三个模型过拟合;第二个模型拟合较好.
6.4 如何处理欠拟合、过拟合
- 欠拟合:提高模型复杂度,如增加特征、增加模型最高次幂等等;
- 过拟合:降低模型复杂度,如减少特征、降低模型最高次幂等等.
7. 实例
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 加载数据集
data = pd.read_csv('Salary_Data.csv')
x,y = data['YearsExperience'],data['Salary']
plt.grid(linestyle=':')
plt.scatter(x,y, s=60, color='dodgerblue', label='Samples')
import sklearn.pipeline as pl
import sklearn.preprocessing as sp
model = pl.make_pipeline(sp.PolynomialFeatures(10), lm.Ridge())
model.fit(train_x, train_y) # 对train_x做多项式特征扩展,然后训练线性回归模型
pred_test_y = model.predict(test_x)
# 评估
print(sm.r2_score(test_y, pred_test_y)) # 0.9678561968395445
# 可视化
plt.grid(linestyle=':')
plt.scatter(x,y, s=60, color='dodgerblue', label='Samples')
# 构造200个样本点,预测得到200个输出,绘制多项式模型图像
xs = np.linspace(train_x.min(), train_x.max(), 200)
ys = model.predict(xs.reshape(-1, 1)) # 变成n行1列
plt.plot(xs, ys, color='orangered', label='Poly Regression')
plt.legend()


















 65万+
65万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











