






欢迎加入ComfyUI中文爱好者讨论 https://www.mixcomfy.com
亲爱的开发者和设计师们,现在是时候加入我们,一起探索全新的创作方式了!作为一款备受开发者和设计师喜爱的强大SD UI 框架,ComfyUI 一直以来都致力于为用户提供出色的体验。而现在,我们将为您带来 ComfyUI 系统教程,为您提供更加便捷和全面的社群学习资源。
加入ComfyUI动画知识库星球 https://t.zsxq.com/18K5GqOd1
感谢 @WritterGPT ML2627 的记录。
分享者 / Rui
总结YouTube视频的gpts

可以针对多语言的长视频进行摘要处理。原理是取到Youtube的视频字幕,然后喂给GPT。也可以自己通过 MixCopilot 实现一个 :
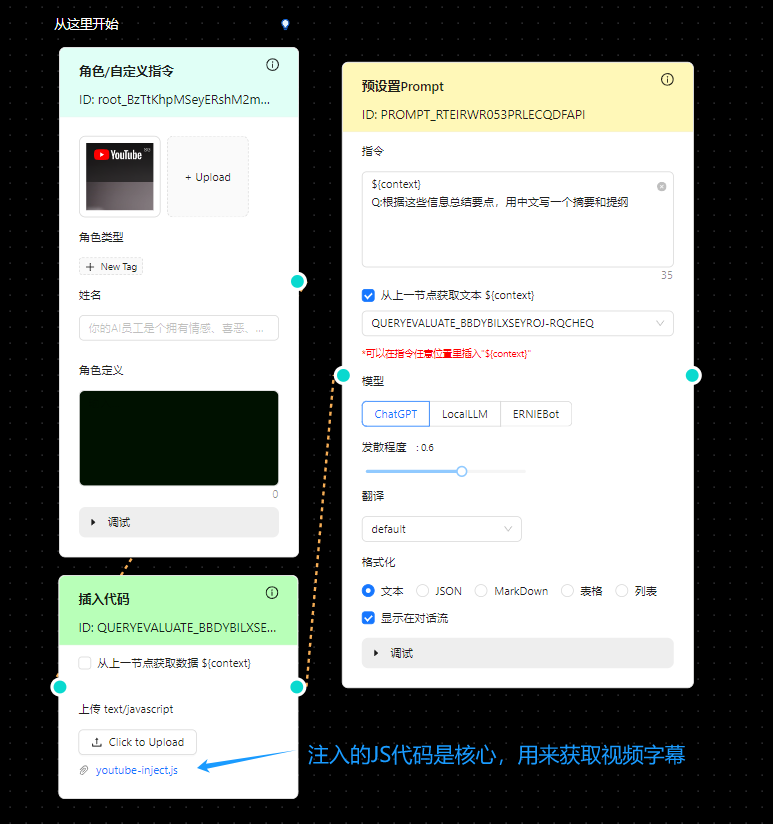
https://chat.openai.com/g/g-Dfo2YQk0Y-noyoutube-video-summarizer
分享者 / 葫芦娃
LayerStyle
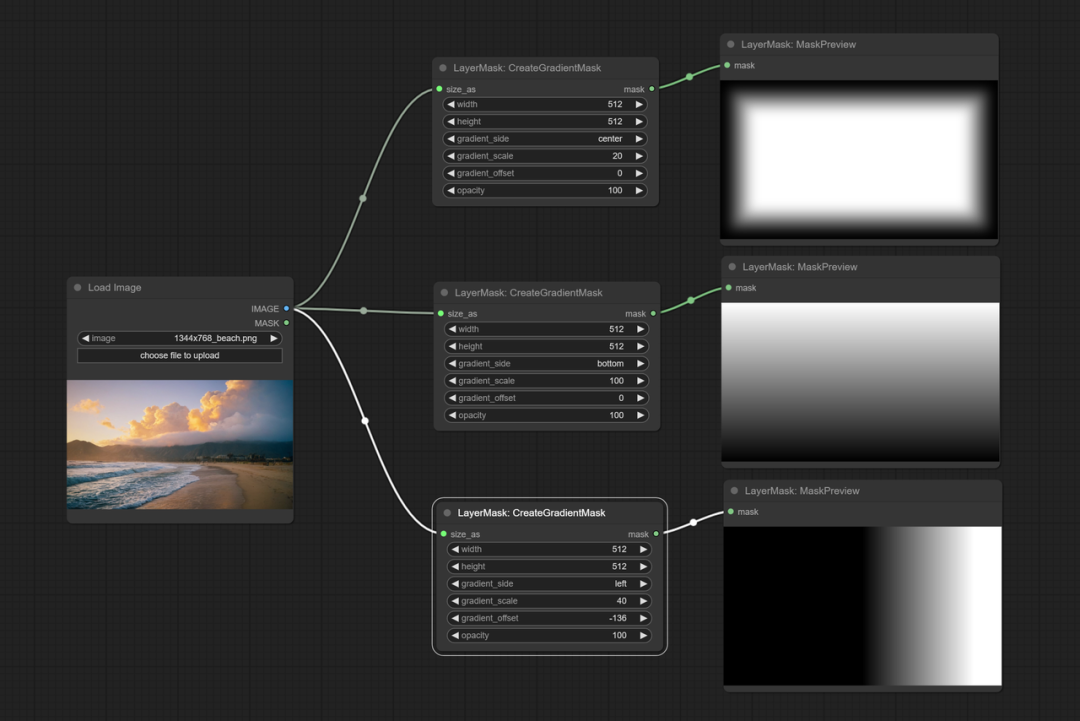
LayerStyle节点更新,CreateGradientMask增加center选项,可输出四周往中心的渐变,改善裁剪回帖边缘。新增AutoBrightiness,可自动调整过暗或过亮的图片到适中的亮度,支持遮罩输入仅参考遮罩部分的亮度数据。
https://github.com/chflame163/ComfyUI_LayerStyle
分享者 / Rui
midreal.ai 绘本

一个用AI做绘本故事的网站,给一点提示自动帮你写故事,配图。模型风格还不错。
好玩的是,你可以看别人的故事,不满意了接着他的开头改一个自己的版本。
https://midreal.ai
分享者 / Zho
CosXL 和 CosXL-Edit 模型

Stability AI 在 Hugging Face 上发布了 CosXL 和 CosXL-Edit 模型:CosXL 与 Playground v2.5 类似,也用上了 EDM,可以实现 PG2.5 提到的鲜艳色彩和高对比度图像。
Edit 模型属于 InstructPix2Pix 模型,用于实现提示词+图像精确编辑
模型(仅研究):https://huggingface.co/stabilityai/cosxl
https://comfyanonymous.github.io/ComfyUI_examples/edit_models/
分享者 / 海辛
AI Coser
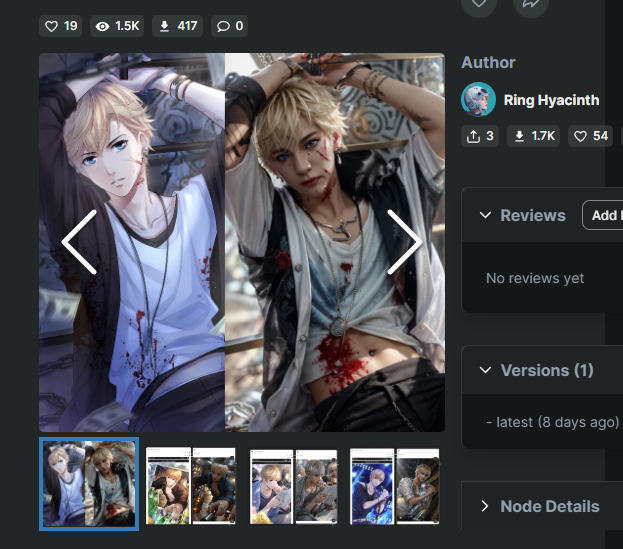
这是一个针对《我爱女主的选择》角色周启洛的AI Coser工作流程。它使用了多个模型和自定义节点来生成AI角色扮演图片。此项目是一个粉丝作品,不得用于商业目的。
"即使对于周启洛来说,不是所有情况都能自动生成最佳结果,请根据需要调整参数。"
"默认的宽高比是800*1216,如果上传了不同风格的卡片,请在图像大小调整节点中进行更改。"
https://openart.ai/workflows/UsWOVtezOZeNnzVljTf7

入群备注:ComfyUI
分享者 / Zho
艺术风格可视化

新出的 CosXL-Edit 模型非常适合风格迁移!做了一版艺术风格可视化的工作流:
CosXL-Edit 正好可以与我之前做的提示词可视化(ArtGallery)结合起来,方便大家直观的选择和自由组合风格,再也不用担心不懂风格了!工作流使用了 Fast Bypasser,可以对艺术家、流派和风格任意组合,尽情发挥创意吧!
使用插件:
1)ArtGallery:https://github.com/ZHO-ZHO-ZHO/ComfyUI-ArtGallery
2)Bypasser + Switch:https://github.com/rgthree/rgthree-comfy
3)Text Concat(可用任何文字连接节点替代):https://github.com/ZHO-ZHO-ZHO/ComfyUI-Gemini
https://github.com/ZHO-ZHO-ZHO/ComfyUI-Workflows-ZHO
分享者 / PM熊叔
ComfyUI 音频动画

这个工作流是为了实现音频反应的效果而设计的。通过在ComfyUI中玩弄AudioScheduler自定义节点的工作流,作者试图实现音频反应的效果,并希望有更多ComfyUI专家能够参与进来,创造出令人惊艳的音频反应式的ComfyUI节点和工作流。
欢迎加入我们的社群,一起交流分享!🎵🎨✨
Join our community and let's create amazing audio-reactive ComfyUI nodes and workflows together! 🎵🎨✨
工作流程:https://openart.ai/workflows/dyx1msfMUgNxUAFEJ6nV
音频调度程序自定义节点:https://github.com/a1lazydog/ComfyUI-AudioScheduler

加入社群
更多详见:
https://ywukcp2ygto.feishu.cn/wiki/ZoGUw23BVilkZnkrFTRcQn23nQg?from=from_copylink

















 7078
7078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









