






你是否曾经尝试将一段很长的文本输入ChatGPT,却被告知文本太长了?或者你是否试图让你的应用程序具有更好的长期记忆,但效果还不够好?
提高大语言模型性能的一个有效的策略是将大型数据分割成较小的部分。这个过程被称为分割或分块(Text Splitting)。
在这个教程中,介绍了文本分割的5种方法。我阅读后做了些精简,分享给大家,原文可以文末查看原链接。
Text Splitting
文本分割的方法
方法1:字符分割 - 简单的静态字符数据块
方法2:递归字符文本分割 - 基于分隔符列表的递归分块
方法3:特定文档分割 - 针对不同文档类型(PDF、Python、Markdown)的各种分块方法
方法4:语义分割 - 基于嵌入式遍历的分块
方法5:LLM 分割 - 使用类似代理系统的实验性文本分割方法。如果您的GPT成本接近于0.00美元,这种方法很好。
为了方便理解各种分割方式,可以通过下面这个可视化的网站,调整参数,体验文本分割的方法 ↓

可视化文本分割
chunkviz.up.railway.app
方法1:字符分割
字符分割是将文本分割的最基本形式。它是简单地将文本分割成N个字符大小的块,而不考虑其内容或形式。
优点:简单易行
缺点:非常刻板,不考虑文本的结构
需要了解的概念:
块大小 Chunk Size - 您希望在块中包含的字符数。50、100、100,000等。
块重叠 Chunk Overlap - 您希望连续块之间重叠的量。这是为了避免将单个上下文切割成多个部分。这将在块之间创建重复的数据。

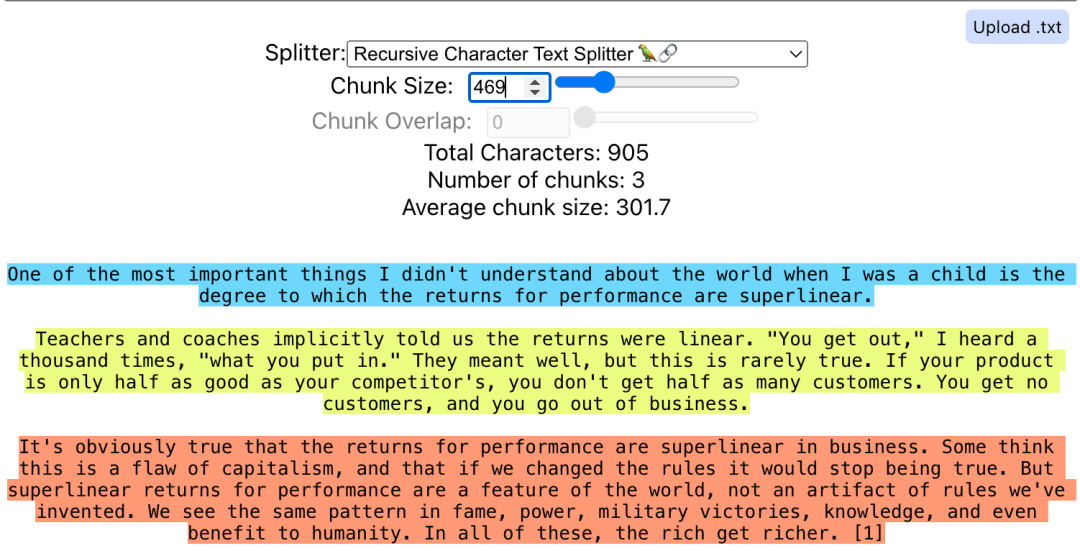
方法2:递归字符文本分割
方法1的问题在于完全不考虑文档的结构。只是按照固定数量的字符进行分割。
递归字符文本分割器可以解决这个问题。通过它,我们将指定一系列分隔符来分割文档。例如 LangChain的默认分隔符:
"\n\n" - 换行
"\n" - 换行
" " - 空格
"" - 空字符
这是快速搭建应用程序时的首选。如果您不知道从哪个分割器开始,这是一个不错的首选。
方法3:特定文档分割
除了普通文本文件之外的其他文档类型。比如图片、PDF、代码片段等等。前两个方法对于这些情况并不适用,所以需要找到不同的策略。
Markdown、Python和JS的分割器基本上与递归字符分割器类似,只是使用不同的分隔符。例如 Markdown 分隔符:
\n#{1,6} - 标题
```\n -代码块
\n\\*\\*\\*+\n - Horizontal Lines
\n---+\n - Horizontal Lines
\n___+\n - Horizontal Lines
\n\n 换行
\n - 换行
" " - 空格
"" - 空字符
再比如 Python 分隔符:
\nclass -类
\ndef - 方法
\n\tdef - Indented functions
\n\n - 换行
\n - 换行
" " - 空格
"" - 空字符
方法4:语义分块
我们是否觉得为块大小设置一个全局常量很奇怪?我们的普通分块机制是否更奇怪,因为它们没有考虑实际内容?
嵌入表示了字符串的语义含义。它们本身并没有太多作用,但是当与其他文本的嵌入进行比较时,您可以开始推断块之间的关系。利用这个特性,探索使用嵌入来找到语义上相似的文本聚类。假设是语义上相似的块应该放在一起。
(此部分详见作者代码演示)
方法5:LLM 分块
我们是否可以命令LLM执行此任务?人类是如何进行分块的呢?我们会如何将文档分块成具有语义相似性的离散部分?
我会准备一张草稿纸或记事本。
我会从文章的顶部开始,假设第一部分将是一个块(因为我们还没有任何块)。
然后,我会继续阅读文章,评估新的句子或文章片段是否应该成为第一个块的一部分,如果不是,就创建一个新的块。
然后一直这样做,直到读完整篇文章。
ps:
是否要严格使用文档的原始文本,还是使用改写的形式。改写的方式,从原始文本中提取独立的陈述句。
例如: Greg went to the park. He likes walking
> ['Greg went to the park.', 'Greg likes walking']
以上是5种不同的分割策略。欢迎入群交流 ↓

原文:
https://github.com/FullStackRetrieval-com/RetrievalTutorials/blob/main/5_Levels_Of_Text_Splitting.ipynb

github.com/explodinggradients/ragas
评估工具推荐:
Ragas是一个帮助您评估检索增强生成(RAG)pipelines。Ragas提供基于最新研究的工具,用于评估LLM生成的文本,以帮助您了解RAG pipelines的情况。

















 255
255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









