







从前,有一个名叫Comfy的村庄,村里的人们都热衷于各种奇妙的技术。一天,他们决定举办一场盛大的“科技嘉年华”。音频大师和视频插帧专家联手表演了一场视觉与听觉的盛宴;VR魔术师则带领观众穿越到另一个世界,体验前所未有的景深效果。
与此同时,村里的科学家们在cfg实验室里忙得不可开交,他们不断调整深度图和法线数据,试图创造出最逼真的画面。tensorrt工程师在后台加速处理,确保一切实时运行。Pixtral和Llama两位视觉模型大师展开了一场友好的比拼,看看谁能更快更准确地生成图像描述。
Molmo和Motion-I2V这对好朋友则展示了如何通过提示词反推和运动笔刷技术,将静态图片变成生动的视频。最后,村里的艺术家们用lvcd技术为线稿上色,并设计了各种萌萌的贴纸和漫画。
整个嘉年华在GPU的强大支持下,精彩纷呈,村民们无不叹为观止。这个寓言告诉我们,科技的融合和创新能创造出无限可能,只要我们敢于尝试。
📝 Topic 1
📅 2024-10-12 09:57
🏷️ 音频
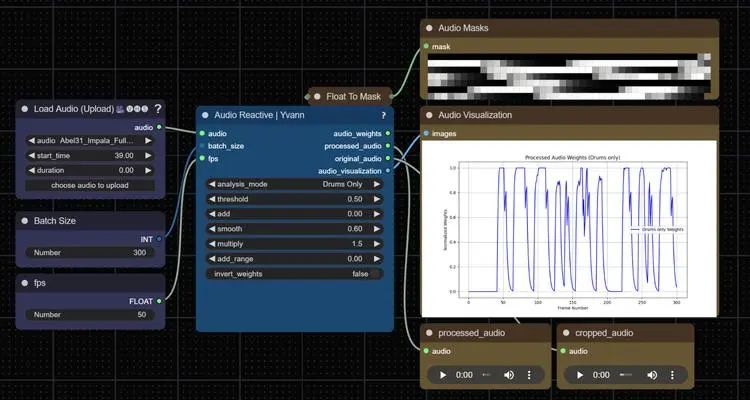
ComfyUI_Yvann-Nodes 是一个用于音频分析的节点包,通过提取鼓声、贝斯、声乐轨道等元素,并使用预定的掩码和权重在 ComfyUI 中创建音频反应动画。节点参数允许手动调整,提供对音频数据解释和转换为反应动画或视觉效果的精细控制。
📝 Topic 2
📅 2024-10-12 09:54
🏷️ 视频插帧
Real-Time Intermediate Flow Estimation for Video Frame Interpolation
该项目提供了一个基于TensorRT的RIFE实现,用于在ComfyUI中进行超快速的帧插值。项目使用的是CC BY-NC-SA许可证,用户可以自由访问、使用、修改和再分发。安装和构建过程包括下载ONNX模型和编辑路径配置,最终将生成的引擎文件放置在指定目录中。项目在Ubuntu 22.04 LTS和RTX 3070 GPU上进行了测试,支持的图像分辨率范围为256x256到3840x3840。
📝 Topic 3
📅 2024-10-11 21:10
🏷️ VR, 景深
ComfyUI-Environment-Visualizer 是一个节点包,允许用户将全景图像和相应的深度图转换为可在 WebXR 环境中查看的 3D 环境。该工具包包含辅助节点,帮助创建等矩形图像,并提供详细的操作概述和生成技巧。用户可以通过 VR 控制器或键盘在环境中导航。此外,该节点包的 WebXR 服务器可以独立运行,提供对已保存环境的选择和查看功能。
📝 Topic 4
📅 2024-10-11 21:09
🏷️ 景深
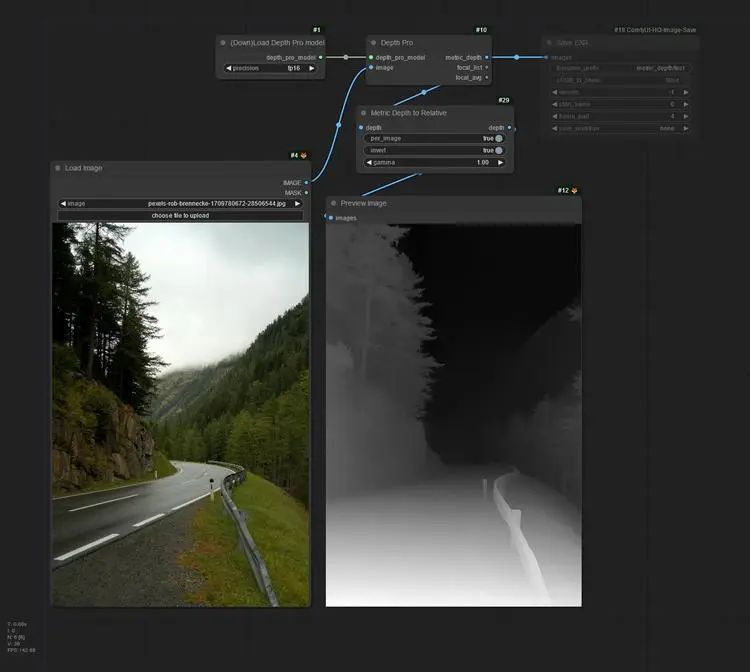
ComfyUI-Depth-Pro是一个基于Apple的ml-depth-pro项目的深度模型工具,主要功能是将深度模型的输出从度量深度转换为相对深度,以便于控制网络的使用。该工具提供了自动下载模型的功能,并支持手动下载和安装。代码和模型受Apache-2.0许可证保护,未修改的部分遵循原始代码库的许可证条款。
📝 Topic 5
📅 2024-10-11 21:07
🏷️ cfg
ComfyUI-APGScaling 是一个用于实现CFG(条件生成函数)缩放的工具,通过使用APG技术能够提升图像质量。示例文件夹中提供了具体的例子,展示了在不同设置下图像效果的对比。该项目旨在通过提高CFG值来优化图像生成效果。

📝 Topic 6
📅 2024-10-11 21:06
🏷️ 深度图, 法线
ComfyUI-Lotus是一个用于深度和法线预测的项目,包含了一些ComfyUI节点。项目模型来源于Hugging Face,并建议将其放置在指定的路径下。

📝 Topic 7
📅 2024-10-11 21:02
🏷️ 景深
ComfyUI-Depthflow-Nodes是一个用于在ComfyUI中实现Depthflow库的节点包。它可以将2D图像转化为惊艳的2.5D视差动画,并扩展了RyanOnTheInside的Flex系统,提供更多的动态动作控制和自定义效果。该节点包包括基础节点、Depthflow效果和动作组件,允许用户通过预设和细化的参数配置创建复杂的动画。
📝 Topic 8
📅 2024-10-02 13:10
🏷️ tensorrt
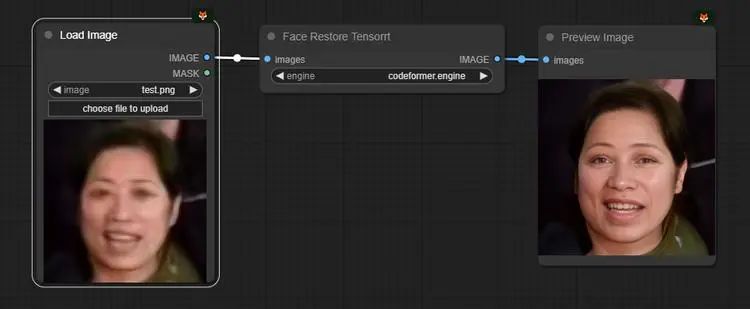
ComfyUI-Facerestore-Tensorrt项目提供了一种实验性的Tensorrt实现,旨在ComfyUI中实现超快速的面部修复。
📝 Topic 9
📅 2024-10-02 13:07
🏷️ 视频, 三维重建
ComfyUI-ViewCrafter 是一个用于新视角合成的工具集成,使用 ViewCrafter 节点。

📝 Topic 10
📅 2024-10-02 13:00
🏷️ flux, 实时
ComfyUI Flux Accelerator是一个用于ComfyUI的自定义节点,能够加速Flux.1的图像生成。其通过使用TAEF1快速编码器、量化和编译技术以及跳过冗余的DiT块来实现加速。该工具可以将图像生成速度提高最多37.25%。
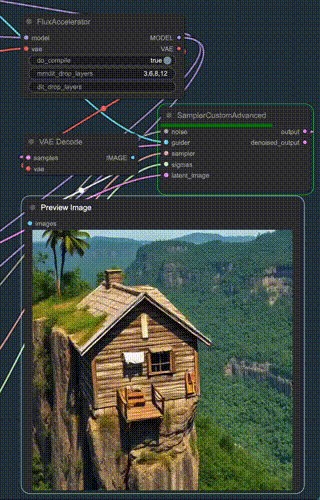
📝 Topic 11
📅 2024-10-02 12:54
🏷️ 提示工程
ComfyUI_FluxPromptGen 旨在增强提示生成和图像描述功能。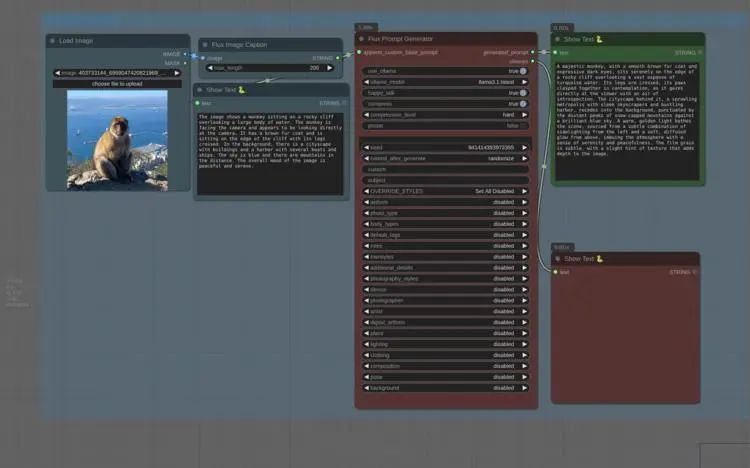
📝 Topic 12
📅 2024-10-02 11:48
🏷️ lora
用于合并flux的lora模型的节点,如果想了解合并逻辑,可以阅读代码。
GitHub - StartHua/Comfyui_CXH_FluxLoraMerge: flux ...
📝 Topic 13
📅 2024-10-02 11:29
🏷️ Pixtral, Mistral Pixtral AP, 视觉模型
ComfyUI_pixtral_vision 是一个强大的ComfyUI节点,旨在无缝集成Mistral Pixtral API,通过深度学习模型进行图像分析和描述。用户可以直接输入图像并提供上下文提示,使用API密钥进行身份验证。该节点特别适用于需要详细视觉理解和内容描述的应用场景。

📝 Topic 14
📅 2024-10-02 11:20
🏷️ Llama, 视觉模型, Pixtral, Molmo
ComfyUI-PixtralLlamaVision是一个用于加载和运行Pixtral、Llama 3.2 Vision和Molmo模型的项目。模型需要放置在ComfyUI/models/LLM文件夹中,以提高与其他自定义节点的兼容性。该项目提供了多个节点来加载和运行不同类型的视觉语言模型(VLMs),并包含一些文本处理的实用节点。
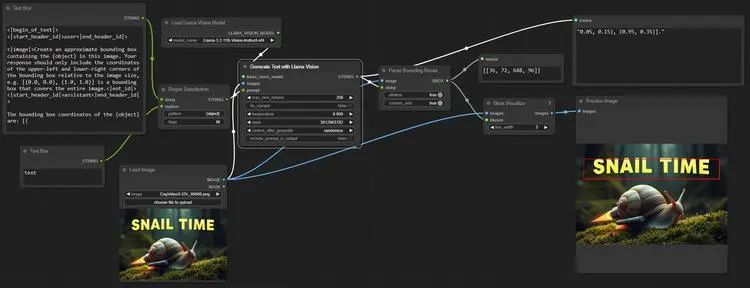
📝 Topic 15
📅 2024-10-02 10:53
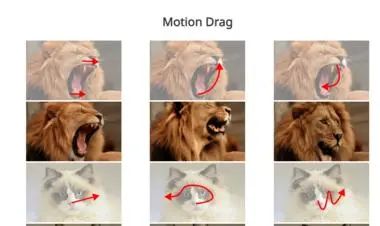
🏷️ Motion-I2V, 运动笔刷, 视频, 可控
ComfyUI-IG-Motion-I2V是一个基于ComfyUI实现的Motion-I2V项目,目前作为diffusers的封装器。该项目提供了若干节点,如MI2V Flow Predictor、MI2V Flow Animator和MI2V Motion Painter,用于生成和控制16帧动画的光流预测和动画制作。项目最新更新包括首次发布、交互式运动绘制UI、基本的IP Adapter集成等。未来计划包括将代码转换为Comfy Native、减少显存使用、增加更多运动控制和训练更长上下文模型。
Motion-I2V是一种新型框架,用于一致且可控的图像到视频生成。该方法通过明确的运动建模将图像到视频生成分为两个阶段。第一阶段采用基于扩散的运动场预测器,专注于推导参考图像像素的轨迹;第二阶段引入运动增强的时间注意力机制,有效地将参考图像的特征传播到合成帧中。与现有方法相比,Motion-I2V在存在大运动和视点变化的情况下,能够生成更一致的视频,并且提供了更高的可控性。此外,该框架还支持零样本视频到视频的翻译。
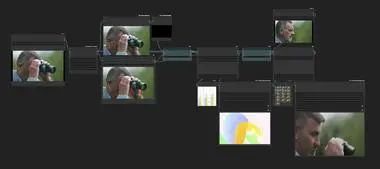
📝 Topic 16
📅 2024-10-02 10:25
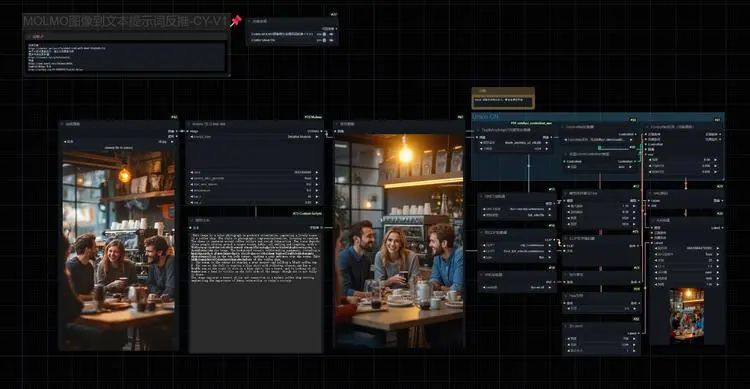
🏷️ Molmo, 提示词反推, 提示工程, 视觉模型
ComfyUI-Molmo是一个在ComfyUI中实现图片描述和分析的项目,通过使用Molmo模型将图片转换为文本描述。
Molmo是由AI2开发的一系列开源视觉语言模型,基于PixMo数据集训练,包含100万对高质量图像和文本。Molmo 7B-D模型在学术基准测试和人类评估中表现突出,介于GPT-4V和GPT-4o之间。Molmo 7B-D使用Qwen2-7B作为基础模型,并采用OpenAI CLIP作为视觉主干。
📝 Topic 17
📅 2024-10-01 21:16
🏷️ lvcd, 视频, 线稿
LVCD 基于参考的线稿视频上色的扩散框架。与以往依赖图像生成模型逐帧上色的方法不同,我们的方法利用大规模预训练的视频扩散模型生成上色动画视频,从而获得更好的时序一致性,并能更好地处理大幅度动作。
ComfyUI-LVCDWrapper是一个用于LVCD(稳定视频扩散)的包装器。它需要SVD模型,推荐使用原版模型,但也支持1.1和XT版本。模型文件通常从指定的路径加载,如果不存在则会自动下载。

📝 Topic 18
📅 2024-09-29 16:43
🏷️ 贴纸, prompt
一组贴纸的prompt
"0": "Laughing,Eat cake",
"1": "Crying, tears, sadness, coffee",
"2": "Take the microphone, sing",
"3": "Listen to music with headphones on and eyes closed",
, Sticker, svg, vector art, sharp, kawaii style, Anime style
📝 Topic 19
📅 2024-09-27 07:23
🏷️ 教程, 工作流, 漫画
该视频介绍了如何使用ComfyUI创建一致的漫画角色,并自动编写和嵌入故事文本。视频通过逐步演示工作流程,帮助观众了解如何安装自定义节点和生成故事。
📝 Topic 20
📅 2024-09-26 13:26
🏷️ gpu
ComfyUI-MultiGPU是一个扩展插件,旨在通过增加新的节点来支持在单个ComfyUI工作流中使用多个GPU。该插件允许用户为每个模型指定使用的GPU,从而优化内存管理。然而,这种方法并不增加并行处理能力,工作流步骤仍会按顺序在不同的GPU上执行。用户可以在不同的GPU上加载和分配任务,以减少模型从VRAM频繁加载和卸载的时间。
更多详见:
https://t.zsxq.com/c2TjW


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









