






Publisher: In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition 2022
MOTIVATION OF READING: 自监督学对比学习代表作、Momentum 动量对比, INFONCE
link: https://arxiv.org/abs/1911.05722
Code: GitHub - facebookresearch/moco: PyTorch implementation of MoCo: https://arxiv.org/abs/1911.05722
1. 代理任务(pretext tasks)的处理方式
The term “pretext” implies that the task being solved is not of genuine interest, but is solved only for the true purpose of learning a good data representation.
对于对比学习就是要构造对比方式进行学习特征表示。只要有新的正负样本的对应方式,就是有新的对比方法。
1.1 instance discrimination
对于数据集中的单个样本进行裁剪数据增强获得的两张图片,认为是相似的是正样本,与其余所有的图片都认为是不相似的,是负样本。
1.2 视频领域
认为相邻帧都是正样本,其余都是负样本。
1.3 NLP领域
SimCSE:把同样的句子扔给模型,做两次forward用不同的dropout,这样得到的两个特征认为是正样本
2. Momentum的含义
使用动量对比去做无监督视觉表征学习,动量在数学上就是加权移动平均。
,其中
为上一时刻的输出,
为当前输入,m是动量参数。如果m很大,结果
就取决于上一时刻的输出,更新就比较缓慢,反之亦然。
3. 如何将对比学习看成一个动态字典的方式?
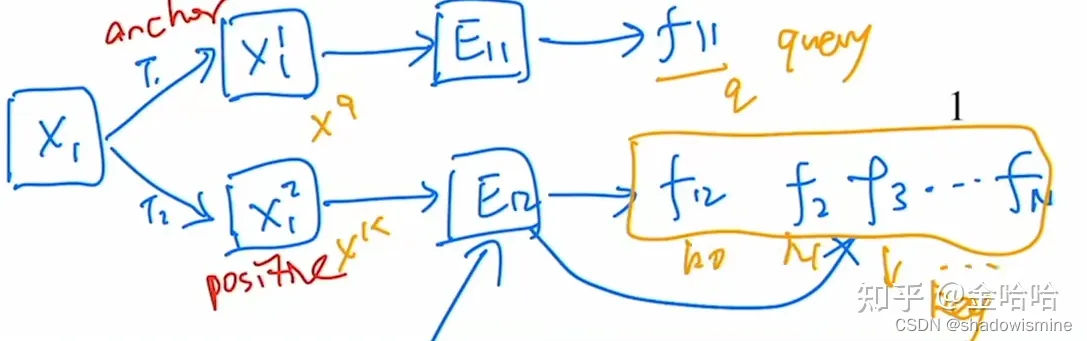
作者认为,对比学习方法都可以归纳成一个字典查询的方式。也就是说,对于一个query来讲,要去接近与之来自同个样本的key,远离不是一个样本的key。
Though driven by various motivations, these methods can be thought of as building dynamic dictionaries. The “keys” (tokens) in the dictionary are sampled from data (e.g., images or patches) and are represented by an encoder network. Unsupervised learning trains encoders to perform dictionary look-up: an encoded “query” should be similar to its matching key and dissimilar to others.
如果希望这个构建这样一个有效的字典需要满足一定的条件:1. 字典要足够的大 2. 在训练的过程中要保持一致性(这些key需要用一致或相似的编码器去进行特征抽取,这样去和query的表示做对比的时候,才能保证对比具有一致性。否则query寻找的可能是具有相似编码器的特征而不是具有相似语义的特征)。
We maintain the dictionary as a queue of data samples: the encoded representations of the current mini-batch are enqueued, and the oldest are dequeued.
构建的字典是数据样本的队列。但是入队出队的是encoded representations。
4. MoCo的架构
4.1 字典查询和动量编码器简述

moco构建了一个队列queue来存放一定数量的key。因为当字典非常大时,显存和内存是不足以容纳它,特别是在面对巨大的数据集的时候。
通过队列的方式,每一次的字典里样本的数量是一定的,字典的数据结构是队列,字典可以动态的缓慢更新,就可以一定程度上解决这个问题。将新的mini-batch移入队列,最早的mini-batch移除队列。

假设生成q的encoder为,生成k的动量编码器便为
,如果m非常大,那么编码器就受
的影响就会比较小。
4.2 Loss学习目标
对于MoCo来说,也是需要构建损失函数来进行目标学习的,他学习的目标就是希望query与字典中那个与之相match的key越近似越好,与其他不匹配的越不相似越好。MoCo使用的是一种对比损失函数,叫InfoNCE。
NCE(noise contrastive estimation):当使用交叉熵的时候,如果类别太多(比如类别数相当于就是数据集图片数),那么交叉熵是没法运行的。于是不如就是把多分类看成了数据样本和噪声样本两种类别,变成一系列的二分类问题,希望通过采样部分的负样本来近似使用全部负样本的效果。那么采样的负样本越多,自然就越接近全部样本的效果,但是同样也越难体现出交叉熵函数的作用。
InfoNCE认为不能单纯的看成二分类问题,因为很多负样本本身还是很不相似的,所以还是需要看成多分类的:
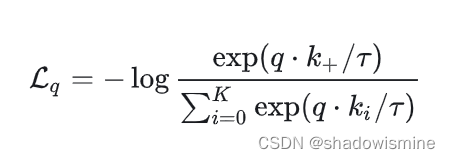
式子中,k+就代表那个相匹配的k,T是温度超参数。T越大,分布会越平滑,T越小,分布就会越陡峭peak更集中。公式下面的0到K指的是一个正样本和K个负样本。本质上直观的来看,这个损失函数就是交叉熵损失。
4.3 贡献点1:将字典做成一个队列 使得整个字典可以大
The introduction of a queue decouples the dictionary size from the mini-batch size. Our dictionary size can be much larger than a typical mini-batch size, and can be flexibly and independently set as a hyper-parameter.
也就是说,对于end-to-end的方法(下面5有说)来说,在硬件资源的局限下,是很难直接利用很大的batchsize的,直接导致的就是字典的规模会小。而对于moco来讲能通过队列的方式来使得字典动态起来,从而变得很大。
直观来说,就是利用了额外的空间维护了一个队列,整个队列里有n个mini-batch的,每一次queue匹配结束,就将这个queue的mini-batch送进去(这个最新也表示是目前最新的encoder所构建出来的特征表示),把之前用过的最旧的mini-batch送走(这个最旧,同样表现得是encoder是最旧的)。
4.4 贡献点2:使用动量更新构建的momentum encoder可以保证一致性
前面说到,对于query来说有一个编码器q,同样的对于key来讲也有编码器k。在moco中,作者认为这个key编码器的参数的得到是值得考究的,如果直接像end-to-end的方法(下面5有说)一样,两个编码器同时更新,是不合理的,由于每一次的key都不一样,导致key encoder无法保证一致性。于是,作者就提出了动量编码器的概念,使得key encoder的参数同时取决于当前query ender的参数和前置key encoder的参数,使得有一个缓慢的变化,尽可能的保持key encoder的一致性。
这里m的值很大0.999,使得更新的过程是缓慢的。
4.5 伪代码理解
作者在文章中通过一段伪代码来表述在MoCo的整体的一个前向模型过程
# f_q, f_k: encoder networks for query and key
# queue: dictionary as a queue of K keys (CxK) C代表特征的维度,这里为128(memory bank用的就是128维)
# m: momentum
# t: temperature
# bmm: batch matrix multiplication; mm: matrix multiplication; cat: concatenation.
f_k.params = f_q.params # initialize 刚开始两个编码器的参数应该是一致的
for x in loader: # load a minibatch x with N samples 代码里N默认是256
#获取一个正样本对,x_q和x_k都是从同一个样本x中获取的,语义应该是相似的。
x_q = aug(x) # a randomly augmented version
x_k = aug(x) # another randomly augmented version
#这里两个aug应该是不同的增强操作,another.
q = f_q.forward(x_q) # queries: NxC 256x128
k = f_k.forward(x_k) # keys: NxC 256x128
k = k.detach() # no gradient to keys #key这边的encoder是不参与梯度更新的
# positive logits: Nx1; 256x1
# bmm: batch matrix multiplication;
# 在Moco中本质上是利用点积来构建两个向量的相似度。
l_pos = bmm(q.view(N,1,C), k.view(N,C,1)) # q * k+
# negative logits: NxK; 256 x 65536(字典大小)
# mm: matrix multiplication
l_neg = mm(q.view(N,C), queue.view(C,K)) # Σq * k_i
# logits: Nx(1+K) 256 x 65537 相当于一个K+1类的分类问题
# cat: concatenation.
logits = cat([l_pos, l_neg], dim=1)
# contrastive loss, Eqn.(1)
labels = zeros(N) # positives are the 0-th 全0向量,因为正样本正好在第0个位置,index是0
loss = CrossEntropyLoss(logits/t, labels)
# SGD update: query network
loss.backward()
update(f_q.params)
# momentum update: key network
f_k.params = m*f_k.params+(1-m)*f_q.params #key编码器的参数由key和新更新完的query参数动量组合
# update dictionary 更新字典,队列一样,先进先出。
enqueue(queue, k) # enqueue the current minibatch 把新算的这个key放入队列里,把最老的key从队列中移除
dequeue(queue) # dequeue the earliest minibatch4.6 关于两个encoder的使用问题
毫无疑问,对于query encoder来讲,每一次的输入肯定就是只是每一次的mini-batch。对于动量编码器key encoder的使用,从代码层面来看,应该只有单次的对应的k+有参与使用。而剩余的queue本身就是已经编码好的特征了,是之前的动量编码器编码的结果,所以作者才会在文章中说到,要把旧的编码器得到的特征出队。
5. 其他对比学习架构的局限性
理解其他两种不同对比学习框架的方法,可以帮助去理解MoCo的方法。
作者提出,相比于MoCo而言,其他的对比学习框架都是有局限性的,要么就是1. 字典的大小太小(end-to-end) 2. 一致性无法得到保障(memory bank)。作者将先前的方法归结为两类,一个是end-to-end,一个是memory bank。
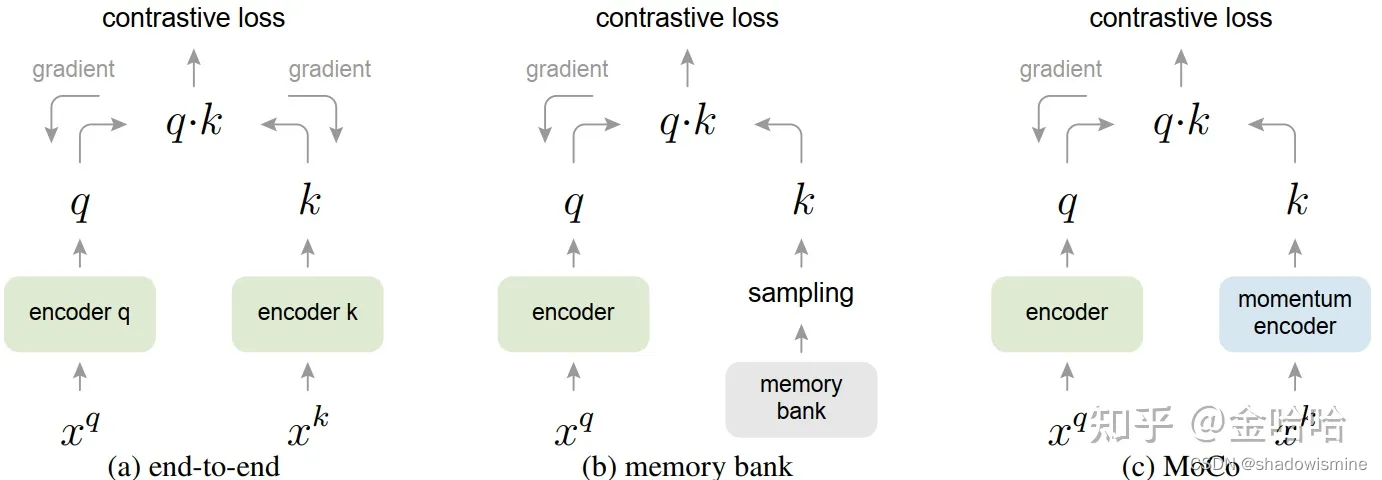
对于end-to-end而言,SimCLR就是典型的end-to-end框架。它能取得好的效果很大程度上归功于google大型的TPU集群,使用了8192为bathsize。这对一般的设备是难以实现的,相当于就是用暴力的堆资源的手段来解决字典太小的问题。在end-to-to的架构中,q,k的两个encoder(也可能用的就是同一个encoder)都是可以进行同步的梯度更新的,就如上图(a)所示。虽然有着字典小的问题,但同时,他的编码器可以实时更新,字典里的key一致性可以得到保证。
对于另外一类方法memory bank而言,它希望在牺牲一定key特性一致性的情况下,来构造很大的字典。他只有query的encoder是可以进行梯度更新的。 它的做法,先把所有的key都存在这个memory bank里面(这里这些key已经是特征了,一个样本128维),再随机从其中抽样当作字典。 这些被抽样的key帮助encoder更新后,在由这个encoder产生对应的新的这些的key,进行替换。假设memory bank里有很多的key,k1,k2,k3...kn,这时候抽样出k1,k2,k3出来作为我随机抽取的字典,再与encoder生成的query做损失,来更新encoder,这个更新好的encoder这时候会用于给刚刚的k1,k2,k3的原始图片提取新的特征key k1,k2,k3来替换掉原来的。这样的做法带来的问题,每一次这些特征key都是不同时刻编码器获得的,而编码器又是在不断变换更新的,所以得到的这些key是缺乏一致性的。
参考:















 2637
2637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









