







Publisher: IEEE TRANSACTIONS ON INDUSTRIAL INFORMATICS 2023
MOTIVATION OF READING: 第一篇通过自监督学习在NILM上的应用
1. Overview
This is the first work to pre-train the NILM model with unlabelled data based on self-supervised learning in time series.
Firstly, a Multi-Layer Momentum Contrast (MLMoCo) network is designed for unsupervised feature representation learning using a momentum contrast mechanism.
Then, an event-based data augmentation algorithm is proposed to improve the diversity of aggregate load for pair comparison in self-supervised learning.
Finally, extensive experiments with real-world datasets are conducted to evaluate the effectiveness of the proposed algorithm.
2. Contributions
1) A multi-layer momentum contrast learning framework is creatively proposed to characterise unlabelled aggregate load for NILM. The presented approach pursues to exploit the high-level features among different time steps and the low-level features among different samples.
2) A novel data augmentation method is proposed based on event detection. Unlike the traditional event-based NILM, which needs prior knowledge for load estimation, the detected event is used for augmenting the data for feature representation learning in an unsupervised manner.
3) Extensive experiments with real-world datasets demonstrate (i) The effectiveness and superiority of the proposed algorithm on different downstream tasks compared with the
state-of-the-art supervised NILM. (ii) MLMoCo can reduce the model’s dependency on the number of labelled data. (iii) The feature learned from the unlabelled data can help the
model improve the transferability and reduce the monitoringdifficulty compared with the supervised methods.
3. Background
For deep learning-based algorithms, the model is trained to take the aggregate signals such as active power, reactive power, and voltage-current trajectory as input and disaggregate the ON/OFF state (classification problem) or power (regression problem) of each monitored appliance.

4. Problem Formulation

where 𝜖𝑡 is the noise term, 𝑁 is the number of electrical appliances in a house.
NILM can be divided into two different downstream tasks.
Monitoring the working state can be regarded as a classification problem known as state detection. If an appliance’s power consumption rather than ON/OFF status needs to be monitored, NILM can be treated as a regression problem.
Even for the same device, such as a washing machine, the different houses may have different load profiles due to different manufacturers, different function usage, different time of use.

5. Algorithmic Methodology

5.1 Data Augmentation
The main active profiles of the aggregate load 𝒙 are first detected with event detection. Then,
one of the active profiles will be shifted along the time axis to obtain the transformed aggregate load 𝒙'. The proposed active profile permutation method can ensure that 𝒙 and 𝒙' are distinct
but strongly related, which is useful for feature representation learning.
1) Event Detection:
Typically, a sudden change can be observed when an event is transferred into an aggregate load 𝒙. (first-order difference)

2) Active Profile Detection:
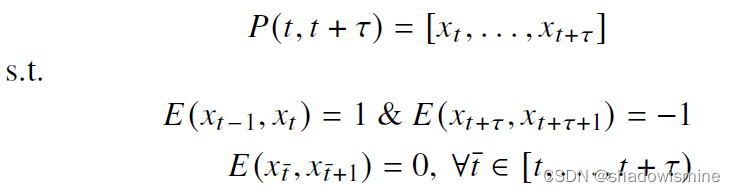
3) Active profile Permutation:
One or more detected active profiles could be shifted along the timeline to make sure that the transformed and original aggregate loads are different and strongly correlated with each other.
Taking the example of moving a detected active profile, the active profile permutation result is as follows,

Then, the jittering is applied to ,
![]()

5.2 Multi-Layer Momentum Contrast Learning
The core idea of the proposed algorithm is to identify the relationships among unlabelled data instances by minimizing the distance between two samples belonging to the same category (positive pairs) while maximizing the distance between two samples belonging to different categories (negative pairs).

The proposed framework consists mainly of two mutually interacted players: a basic encoder, also known as the online branch, embedding input examples into feature vectors, and a momentum encoder, namely the target branch, updating a dynamic dictionary including positive and negative key samples.
1) Network Architecture:
The dilated temporal convolutional network (TCN) block has been designed to reduce the model size rather than the traditional CNNs. To capture the relationship between time points in the sequence, the multi-head self attention mechanism is adopted at the high level of the network.
2) Contrastive Self-Supervised Learning Mechanism:
The pipeline of the proposed network employs two encoders: a basicencoder and a momentum encoder, which have the same architecture.
With a basic encoder, the augmented samples can be encoded to different ”queries” in low- and high-level spaces,
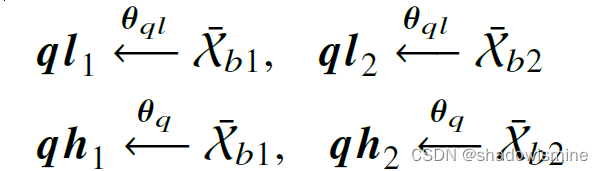
where 𝜽𝑞𝑙 and 𝜽𝑞 are the parameters of the TCN blocks and the basic encoder, respectively, the high-level features concentrate on the similarity of various time steps with self-attention mechanisms. In contrast, the low-level features focus on the characteristics of various samples.
(high-level没有经过TCN,直接通过prediction head输出,而low-level通过TCN输出)
A dynamic dictionary is maintained with a momentum encoder as a queue of encoded keys with the current mini-batch enqueued and the oldest mini-batch dequeued,

where 𝜽𝑘𝑙 and 𝜽𝑘 are the parameters of TCN blocks and all parameters of the momentum encoder.
To make the update of the momentum encoder tractable, a momentum update is adopted
by following
![]()
3) Contrastive Loss:
The InfoNCE contrastive loss function can be expressed as follows,

To make the model robust in balancing error rate optimization from corrupted labels, a symmetric loss is adopted for both lowand high-level feature learning,
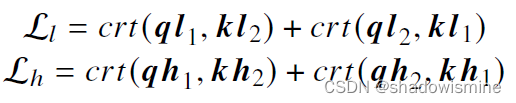

6. Experiment Setup
We evaluate the proposed algorithm on two widely-used datasets: (i) UK-DALE , (ii) REFIT, (iii) AMPds2 , and Dataport.
Considering the time consumption and limited computational resources, it’s reasonable to use the holdout method with enough samples, namely more than 140, 000 samples for the feature learning and 20, 000 samples for the retraining model.

Mean absolute error(MAE), normalized signal aggregate error (SAE), and total energy correctly assigned (TECA) [46] are used to measure the estimated error.

For state detection evaluation, 𝑓1 score that frequently appears in the literature is adopted,
![]()
For a more comprehensive evaluation of the proposed model, monitoring difficulty is proposed to assess the overall performance of the algorithm with accuracy, reliance on labelled data, and training time.
![]()
7. Results

















 1961
1961











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









