







Paper Link: https://aclanthology.org/2023.acl-short.36/
Split-NER: Named Entity Recognition via Two Question-Answering-based Classifications
A 2-stage QA-based framework for NER, which splits NER into Span Detection and Span Classification.
Intro: Typical NERs
- Traditional NER: a sequence labeling task where a model is trained to classify each token of a sequence to a predefined class.
- Span based NER: a model is trained to jointly perform span boundary detection and multiclass classification over the spans, because in reality, multiple tokens might belong to one entity. Span-based NER systems consider all possible spans (i.e., n 2 n^2 n2 (quadratic) spans for a sentence with n n n tokens)
- QA based NER: a model is given a sentence and a query corresponding to each entity type. The model is trained to understand the query and extracts mentions of the entity type as answers. QA-based system multiplies each input sequence by the number of entity types resulting in N × T N×T N×T input sequences for N N N sentences and T T T entity types.
In this work, the author split the span prediction NER into Span Detection and Span Classification, where span detection aims to find which tokens might be a named entity, and span classification aims to classify their actual entity type. Both of these 2 stages are formed as QA task, that the input sentence will be combined with “Extract important entity spans from the following text [SENTENCE]” for span detection and “[SENTENCE] What is [MENTION]”.
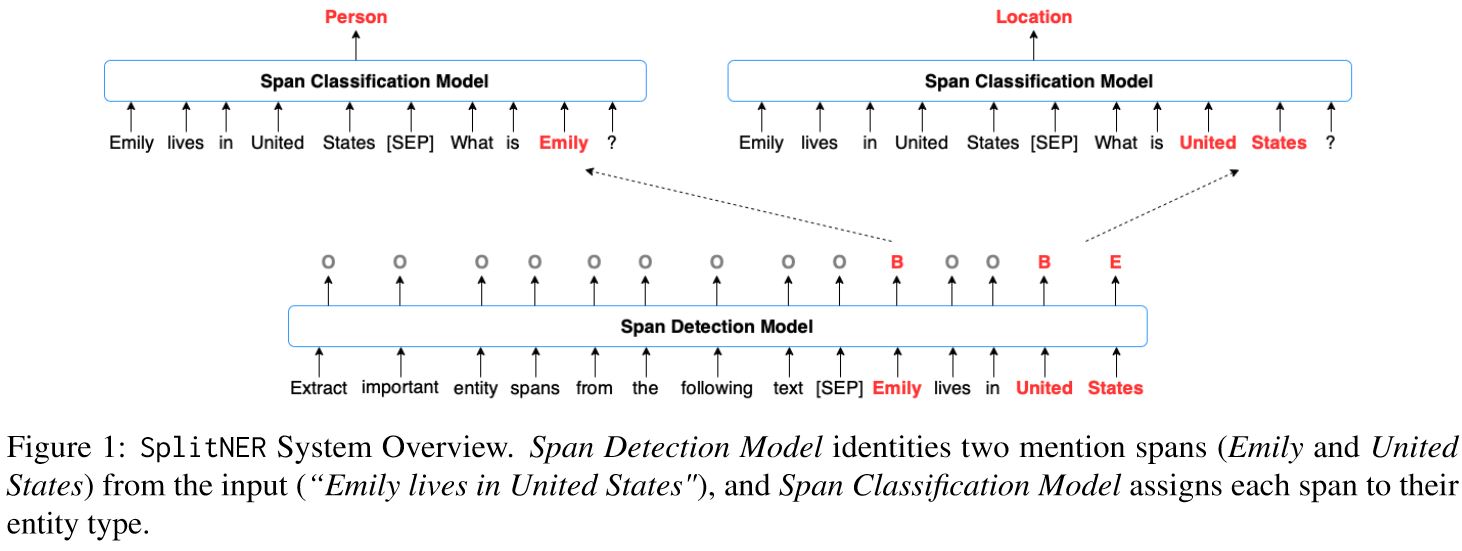
Model
Span Detection
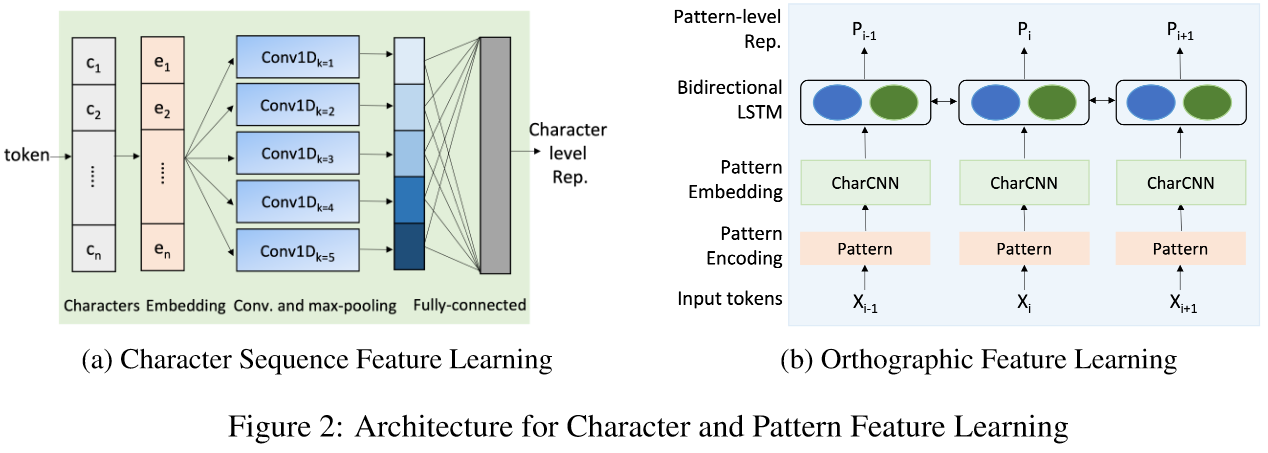
The authors observed that bad cases happen mostly for domain-specific terms which occur rarely and do not have a good semantic representation in the underlying BERT model. So, they try to involve more features.
Character Sequence Feature: Shown in 2(a), all characters in one token are embedded and pass through 5 1D CNN with different kernel sizes from 1 to 5. These convolved embeddings are then concatenated and projected to the same dimension as BERT embeddings.
Orthographic Pattern Feature: Shown in 2(b), this feature aims to extract pattern based on the upper, lower cases and digits. They map all uppercase tokens to a single character, U, all lowercase tokens to L, all digit tokens to D. If a token contains a mix of uppercase, lowercase and digits, we map each lowercase character to l, uppercase to u and digit to d. The pattern is then passed to charCNN similar to 2(a) with 3 different kernel size from 1 to 3. Then, the pattern-level embeddings for all tokens are passed to a bidirectional LSTM with 256 hidden dimensions. Finally, the character and pattern features are concatenated with the BERT output for the token and fed to a final classifier layer.
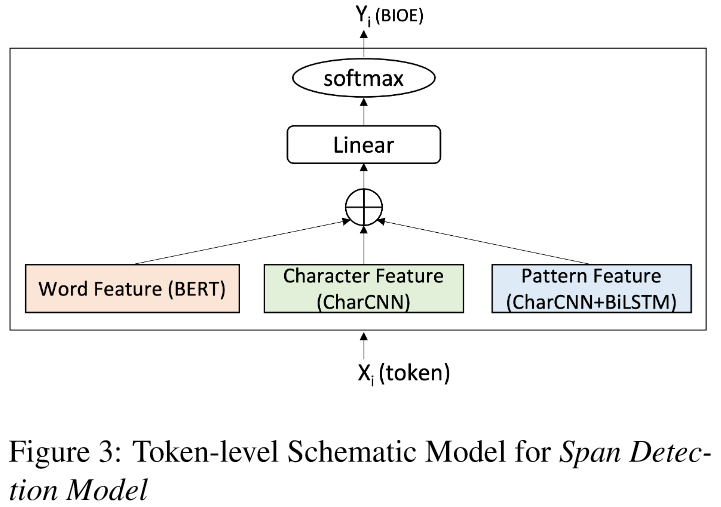
These are quite interesting way to aggregate different patterns into the feature. However, in the age of LLM, LLM itself should be enough to catch these patterns, because of their more complex afterwards structure than BERT.
Span Classification
The classification part is relatively easy. They just fill in the query template “[SENTENCE] What is [MENTION]” and passed it to a BERT-based classifier, just like Fig. 1. Note that span classification is trained via dice loss, basically it’s computing 1 minus the macro F1 score of the batch as the loss.
Evaluation
Baselines:
(1) Single(SeqTag): The standard single-model sequence tagging NER setup which classifies each token using BIOE scheme.
(2) Single(QA): The standard single-model QA-based setup which prefixes input sentences with a question describing the target entity type (e.g., Where is the person mentioned in the text?);
(3) SplitNER(SeqTag-QA): A variant of our model which uses sequence tagging for span detection with our QA-based Span Classification Model;
(4) SplitNER(QANoCharP attern-QA): This model is the same as our method but without the additional character and pattern features. All other baselines use character and pattern features for fair comparison.
All models are trained with 5 random seeds and report the mean mention-level Micro-F1 score in Table 2.
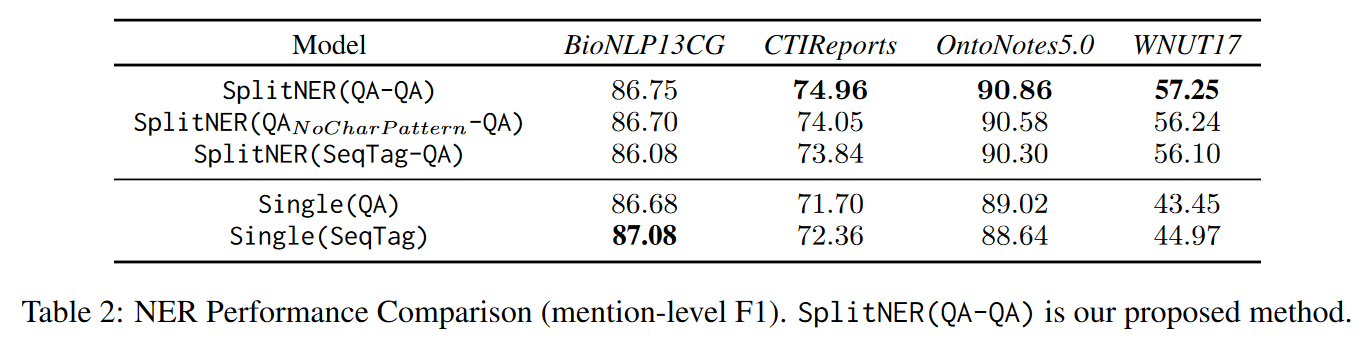
SplitNER(QA-QA) outperforms all baselines on three cross-domain datasets and gives comparable results on BioNLP13CG.
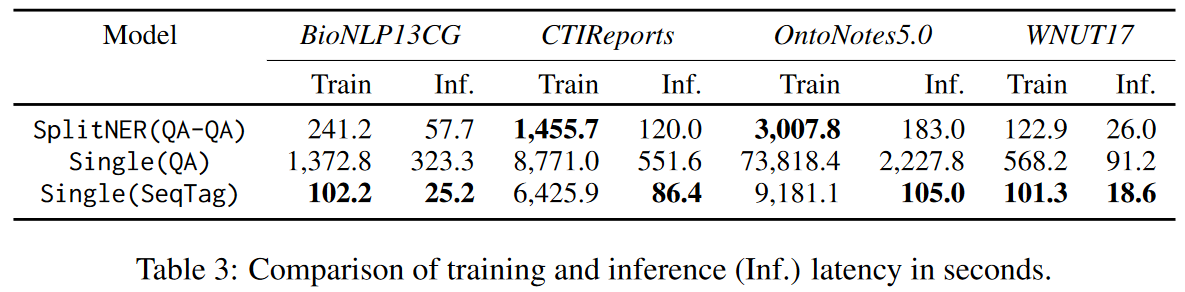
Compared to Single(QA), SplitNER is 5 to 25 times faster for training and about 5 times faster for inference, and it is especially beneficial for large datasets with many entity types., because Single(QA) need to
Compared to Single(SeqTag), our method is slightly slower but achieves much better F1 scores (Table 2).



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











