







1.IO流体系
字节流:抽象类-->InputStream(字节输入流),OutputStream(字节输出流)
字符流:抽象类--->Reader(字符输入流),write(字符输出流)
各种字节流和字符流继承以上的抽象类(父类,各种IO流的爹)
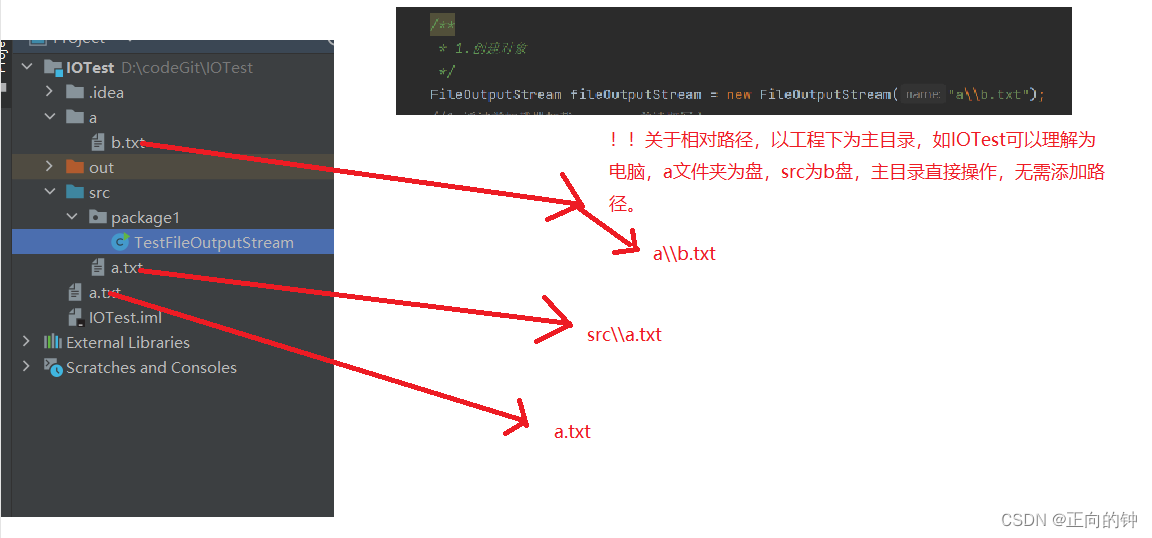
2.关于相对路径和据对路径的问题
3.FileOutputStream------>文件字节输出流写入数据
package FileOutputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class TestFileOutputStream {
public static void main(String[] args) throws IOException {
/**
* 1.演示字节输出流FileOutputStream
* 2.写出一段文字到本地txt文件中
* 3.实现步骤:创建对象--->写出数据---->释放资源
*/
/**
* 1.创建对象
*/
FileOutputStream fileOutputStream = new FileOutputStream("src\\test\\a.txt");
//1.通过类加载器加载resource并读取写入
//2.据对路径写入
//3.先去研究类加载器的使用
//4.总结maven项目中各种文件路径的读取与写入文件并利用IO流
/**
* 2.写出数据
*/
fileOutputStream.write(92);
/**
* 3.释放资源
*/
fileOutputStream.close();
}
}
3.1 使用步骤
1.创建FileOutputStream对象,参数为需要写入的路径也可以时file对象,流以字节的方式通过write()方法写入
在其父类OutputStream中提供了write()方法写入字节流
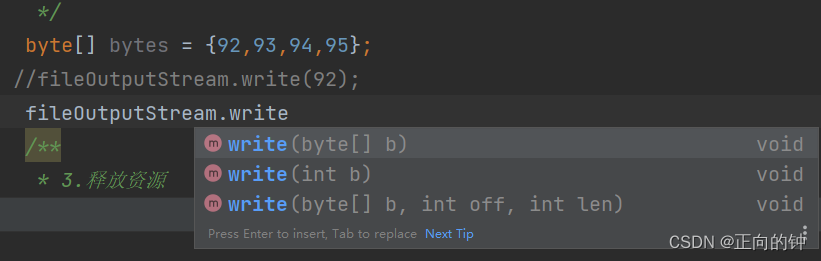
write(int b)传递一个字节,通过int类型的整数对应的ASCll码表传递
write(byte[ ] b)传递一个字节数组,一次性可以传递多个字节
write (byte[ ] b,int off,int len)传递字节数组中的部分字节,截取字节数组片段,off表示起始索引,len表示截取个数
3.2提出问题
1.每次byte[ ]数组都要不停的写一个,或者多个字符,相对麻烦
String test = "hello word";
byte[] bytes = test.getbytes(test);//通过getbytes()方法,将字符串转为字节数组
fileOutputStream.write(bytes)2.每次进行IO写入时,FileOutputStream都会将之前的文本数据进行覆盖,如何完成续写
FileOutputStream fileOutputStream = new FileOutputStream("src\\test\\a.txt",true);
FileOutputStream提供了完成续写的开关,默认为false,在创建对象时,将其设置为true即可。
3.在写入文本数据时,如何完成换行
在次写入一个换行符即可------> \n
4.FileInputStream------->文件字节输入流读取数据
package FileOutputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class TestFileInputStream {
public static void main(String[] args) throws IOException {
/**
* 1.创建文件字节输入流对象,用于把文件输入到内存程序中
*/
FileInputStream fileInputStream = new FileInputStream("src/test/a.txt");
// int a = fileInputStream.read();
// System.out.println((char) a);
int a;
while ((a = fileInputStream.read()) != -1){
System.out.print((char)a);
System.out.print(",");
}
fileInputStream.close();
}
}
4.1关于数据读取的解释说明
1.在读取数据经典的繁琐操作只用于学习,如上述注释的代码所示:
int a = fileOutputStream.read();
System.Out.Print(char(a));分析:这样写只是为了学习理解,一次只能读一个字节,为了将文本中的所有数据都读出来采用循环遍历的方法,read()方法在读取数据时,如果读取完毕,读不到数据会返回一个-1;所以代码应该这样写。
int a;
while ((a = fileInputStream.read()) != -1){
System.out.print((char)a);
System.out.print(",");
}2.注意细节
如果字节打印a,那么会打印出a所对应的ASCLL码的数字,而不是数据本身,所以需要用char(a)
对a进行强转。
5.文件拷贝(边读边写)
public class FileCopyCode {
public static void main(String[] args) throws IOException {
FileInputStream fileInputStream = new FileInputStream("需要读取的文件路径,精确到文件名称");
FileOutputStream fileOutputStream = new FileOutputStream("拷贝到相应的文件夹--精确到文件名称");
int a;
while((a = fileInputStream.read()) != -1){
fileOutputStream.write(a);
}
/**
* 关流原则,先开的后关闭
*/
fileOutputStream.close();
fileInputStream.close();
}
}
备注:这里注意关流原则,先开的后关闭
但是以上拷贝存在几个问题:1.每次只能读一个字节写一个字节,大文件的读取很慢,为了解决
上述问题,给出如下代码
package FileOutputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class FileCopyCode {
public static void main(String[] args) throws IOException {
FileInputStream fileInputStream = new FileInputStream("需要读取的文件路径,精确到文件名称");
FileOutputStream fileOutputStream = new FileOutputStream("拷贝到相应的文件夹--精确到文件名称");
//----------------------------------------------------------------------------------------------
/**
* 普通读取方法,一次读一个字节,速度慢,无法读取大文件
int a;
while((a = fileInputStream.read()) != -1){
fileOutputStream.write(a);
}*/
//----------------------------------------------------------------------------------------------
/**
*创建字节数组,输入流每次读取一个字节数组,返回值len为每次读取的字节数组的字节数
* 关于读取细节:假设数组长度为2,文件大小为5,(a,b,c,d,e)
* 第一次读取 a,b
* 第二次读取 c,d
* 第三次读取 e,d
* 也就是说数组最后如果没有读满,会保留上一次读取的残留数据,所以写入数据时
* 要用write(bytes,0,len),输入流读到几个数据,输出流就写出几个数据
*/
byte[] bytes = new byte[1024 * 1024 * 5];//创建字节数组
int len;
while((len = fileInputStream.read(bytes)) != -1){
fileOutputStream.write(bytes,0,len);
}
/**
* 关流原则,先开的后关闭
*/
fileOutputStream.close();
fileInputStream.close();
}
}
补充说明:使用数组去读取和写入进行文件拷贝时包含的细节在代码注释中给出了详细说明。
6.字符流的引出
在了解完文件字节流后,会发现其无法读取中文,在字符集中,中文的表示是使用两个字节表示的,因此java设计和读取字符的流用来读取字符,也就是说字符流一般用于读取纯文本文件。
如果使用字节流去读取中文或者其他字符,会导致乱码,原因有两点,1.读的编码格式和写的编码格式不一致;2.读取的字符不完整,无法对照字符集。
英文字节的第一个位开头为0,中文字符的第一个位为1。
字符流底层:字节流+字符集
7.FileReadr------->文件字符输入流
public class FileReaderTest {
public static void main(String[] args) throws IOException {
/**
*
*/
FileReader fileReader = new FileReader("src\\test\\b.txt");
int ch;
while((ch = fileReader.read()) != -1){
System.out.print((char) ch);
}
fileReader.close();
}
}代码结构和字节流没啥区别,无非是创建的对象不同。但是底层读取细节不一样,字符流遇英文读一个字节,遇中文读两个,还有一些乱七八糟的,不研究了,会用就行,以后工作遇到了再说。

对照字节流,字符流也可以应字符数组char[]作为read的参数去接收和读取:
此时有参数的字符输入流,将读字节,解码,强转三步合并了
public class FileReaderTest1 {
public static void main(String[] args) throws IOException {
FileReader fileReader = new FileReader("src\\test\\b.txt");
char[] chars = new char[2];//char是字符类型,创建char数组接收读取的数据
int len;
while((len = fileReader.read(chars)) != -1) {
System.out.print(new String(chars, 0, len));
}
fileReader.close();
}
}细节描述: 字符流读出字符放入字符数组char[]中,利用String对象输出字符,无需强转
8.FileWriter-------->文件字符输出流


字符输出流FileWriter()代码:
public class FileWriterTest {
public static void main(String[] args) throws IOException {
FileWriter fileReader = new FileWriter("src\\test\\b.txt",true);
String str = "我好快乐";
fileReader.write(str);
fileReader.close();
}
}没什么好解释的,new个对象,写个路径,填个参数,就可以用了
9.缓冲流(高效的,快速读取的流)
字节缓冲流:BufferedInputStream,BufferedOutputStream
底层:自带8192个字节的缓冲区,一次读取8192个字节

简单来说,就是把基本流的对象当作参数放到缓冲流里,使用方法和基本流基本一样,只不过字符缓冲流包含了两个特有方法。
1.字节缓冲流
package BufferedStream;
import java.io.*;
/**
* 利用字节缓冲流进行文件拷贝,一次读取一个字节数组
*/
public class BufferedStreamTest1 {
public static void main(String[] args) throws IOException {
/**
* 1.定义字节缓冲输入流和输出流
*/
BufferedInputStream bufferedInputStream1 = new BufferedInputStream(new FileInputStream("src\\test\\a.txt"));
BufferedOutputStream bufferedOutputStream1 = new BufferedOutputStream(new FileOutputStream("src\\test\\c.txt",true));
/**
* 2.拷贝文件
*/
byte[] bytes = new byte[1024];
int len;
while((len = bufferedInputStream1.read(bytes)) != -1){
bufferedOutputStream1.write(bytes,0,len);
}
/**
* 3.关流
*/
bufferedOutputStream1.close();
bufferedInputStream1.close();
}
}
2.字符缓冲流
(1)字符缓冲输入流 特有方法:readline()一次读取一行
package BUfferedReaderWriter;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
/**
* 字符缓冲流
* 同有方法reader()
* 特有方法readLine()方法:一次只读取一行文本
*/
public class BufferedReaderTest {
public static void main(String[] args) throws IOException {
BufferedReader bufferedReader = new BufferedReader(new FileReader("src\\test\\a.txt"));
/** 基本读取
* String line = bufferedReader.readLine();
* System.out.println(line);
*/
//2.循环读取
String line;
while((line = bufferedReader.readLine()) != null){
System.out.println(line);
}
bufferedReader.close();
}
}
(2)字符缓冲输出流 特有方法newLine() 打印换行,可以跨平台,不同平台的换行字符不一样
package BUfferedReaderWriter;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
/**
* 缓冲字符输出流
* 特有方法:newLine()跨平台打印换行
*/
public class BufferedWriterTest {
public static void main(String[] args) throws IOException {
//1.创建对象
BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter("src\\test\\c.txt",true));
//2.写入数据
bufferedWriter.write("123");
bufferedWriter.newLine();
bufferedWriter.write("456");
bufferedWriter.newLine();
//3.关流
bufferedWriter.close();
}
}
备注:学好基本流,高级流思路同理,一看就会了。
















 4952
4952











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









