







- 下载Hbase和Redis
Hbase下载地址:Apache HBase – Apache HBase Downloads(使用hbase1.3.5版本)
Redis下载地址:http://www.redis.cn/download.html(使用redis5.0.5版本)
- 通过工具上传Hbase和Redis压缩包
- 解压Hbase和Redis
[hadoop@master software]$ tar zxvf hbase-1.3.5-bin.tar.gz -C /opt/module/
[hadoop@master software]$ tar zxvf redis-5.0.5.tar.gz -C /opt/module/
- 配置Hbase
1.配置 hbase‐env.sh文件
[hadoop@master software]$ cd /opt/module/hbase‐1.3.5/conf/
[hadoop@master conf]$ vim hbase‐env.sh
按i进入编辑模式
添加(根据自己安装的路径来写)
export JAVA_HOME=/opt/module/jdk1.8.0_144
export HBASE_MANAGES_ZK=fales
2.修改hbase-site.xml配置文件
[hadoop@master conf]$ vim hbase‐site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!‐‐ 0.98后的新变动,之前版本没有.port,默认端口为60000 ‐‐>
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/module/zookeeper‐3.4.14/zkData</value>
</property>
</configuration>
3.修改regionserver配置文件
master
slave1
slave2
4.复制hbase到slave中
[hadoop@master module]$ scp -r hbase-1.3.5/ slave1:/opt/module/
[hadoop@master module]$ scp -r hbase-1.3.5/ slave2:/opt/module/
5.启动Hbase
[hadoop@master module]$ cd /opt/module/hbase‐1.3.5/
[hadoop@master module]$ bin/start‐hbase.sh
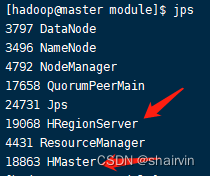
6.Jps查看
[hadoop@master module]$ jps
- Hbase客户端命令
5.1基本操作
1.进入HBase客户端命令行
bin/hbase shell
2.查看帮助
help
3.查看当前数据库中有哪些表
list
4.查看HBase状态
status
5.查看HBase版本
version
5.2表的操作
- 创建表
create 'tech','bigdata'
- 创建表,列族版本号为5
create 'tech',{NAME=>'bigdata',VERSION=>’5’}
“=>”表示赋值,字符串使用单引号括起来;如果指定的列族有特点的属性,需
要使用花括号括起来
- 创建表,3个列族分别为bigdata、database、ai
create 'tech',{NAME=>'bigdata'},{NAME=>'database'},{NAME=>'ai'}
或者create 'tech','bigdata','database','ai'
- 创建表,指定切分点
create 't1','bigdata',SPLITS=>['10','20','30','40']
- 插入数据到表
put 'tech','student1','bigdata:hadoop',"HDFS"
put 'tech','student1','bigdata:hadoop',"Yarn"
put 'tech','student2','bigdata:spark',"Spark‐SQL"
put 'tech','student3','bigdata',"Flink"
put 'tech','student4','bigdata:DataMining',"SVM"
put 'tech','student4','bigdata:hadoop',"MapReduce"
参数分别为:“表名”,“行名”,“列族:列”,“值”
时间戳由系统自动生成
- 扫描查看表数据
scan ‘tech’

- 浏览表、列上面的数据
scan 'tech',{COLUMN=>'bigdata:hadoop'}
- 浏览表、列、时间范围内的数据
scan 'tech',{COLUMN=>'bigdata:hadoop',TIMERANCE=>[1591431217536,1591431217537]}
- 查看表结构
describe 'tech'

- 更新指定字段的数据
put 'tech','student1','bigdata:hadoop',"MapReduce"
- 查看“指定行”的数据
get 'tech','student1'
- 查看“指定列族:列”的数据
get 'tech','student1','bigdata:hadoop'
- 通过指定表名、行、列、时间戳、时间范围和版本号来获得相应单元格的值
get 'tech','student1',{COLUMN=>'c1',TIMERANGE=>[ts1,ts2],VERSIONS=>4}
- 向表添加列族
alter 'tech',NAME=>'info'
- 删除表中的列族
alter 'tech',NAME=>'ai',METHOD=>'delete'
- 设置列族的最大容量
alter 'tech',NAME=>'bigdata',MAX_FILESIZE=>'134217728'
- 统计表数据行数
count 'tech'
- 删除某rowkey的全部数据
deleteall 'tech','student1'
- 删除某rowkey的某一列数据
delete 'tech','student4','bigdata:hadoop'
- 清空表数据
truncate 'tech'
清空表的操作顺序为先disable,然后再truncate
- 删除表
首先需要先让该表为disable状态
disable 'tech'
然后才能drop这个表
drop 'tech'
5.3 HBase的常用
create:创建表
truncate:清空表,相当于重新创建指定表
describe:先死表相关的详细信息
alter:修改列族模式
put:向指定的表单元中添加值
incr:增加指定表、行或列的值
get:获取行或单元(cell)的值
delete:删除指定的对象值(可以为表、行、列对应的值)
count:统计表中的行数
exists:测试表是否存在
list:列出HBase中存在的所有表
scan:通过对表的扫描来获取对应的值
disable:使表无效
drop:删除表
enable:使表无效
status:返回HBase集群的状态信息
shutdown:关闭HBase集群
exit:退出HBase shell
tools:列出HBase所支持的工具
version:返回HBase版本信息
whoami:查看用户身份
hbck:文件检测修复工具
hfile:文件查看工具
hlog:日志查看工具
export:数据导出工具
import:数据导入工具
- Redis安装与客户端使用
6.1安装Redis
- 进入redis解压目录
[hadoop@master bin]$ cd /opt/module/redis-5.0.5/
- 在redis-5.0.5目录下执行make命令
[hadoop@master redis-5.0.5]$ make
- 执行完make后,进入src文件继续执行make install
[hadoop@master redis-5.0.5]$ cd src/
[hadoop@master src]$ sudo make install
- 查看默认安装目录
[hadoop@master src]$ cd /usr/local/bin/
[hadoop@master bin]$ ll
redis-benchmark:性能测试工具,可以在自己本子运行,看看自己本子性能如 何(服务启动起来后执行)
redis-check-aof:修复有问题的AOF文件,rdb和aof后面讲
redis-check-dump:修复有问题的dump.rdb文件
redis-sentinel:Redis集群使用
redis-server:Redis服务器启动命令 redis-cli:客户端,操作入口
- 备份redis.conf:拷贝一份redis.conf到其他目录
[hadoop@master bin]$ cd /opt/module/redis-5.0.5/
[hadoop@master redis-5.0.5]$ cp /opt/module/redis-5.0.5/redis.conf /opt/software/
- 修改redis.conf文件将里面的daemonize no 改成 yes,让服务在后台启动—— 136行
[hadoop@master redis-5.0.5]$ vim redis.conf
daemonize yes
- 启动命令:在/opt和/usr下启动都是一样的
[hadoop@master redis-5.0.5]$ cd /opt/module/redis-5.0.5/src
执行如下命令,启动redis 使用的是默认配置:
[hadoop@master src]$ ./redis-server
启动后会停在启动界面,可以退出也可以保留,建议保留此界面
执行如下命令,通过启动参数告诉redis使用指定配置文件使用下面命令启动:
[hadoop@master src]$ ./redis-server ../redis.conf
6.2Redis客户端使用
- 客户端访问
[hadoop@master src]$ ./redis‐cli
多个端口可以:
[hadoop@master src]$ ./redis-cli -p 6379
- 测试验证
ping
- 单节点关闭Redis
redis‐cli shutdown
也可以进入终端后再关闭
Shutdown
查看是否还存在redis进程
ps ‐ef | grep redis
端口号6379从何而来:Alessia Merz 默认16个数据库,下标从0开始,初始默认使用0号库 使用命令select [dbid]来切换数据库:
select 8
统一密码管理,所有库都是同样密码,要么都OK要么一个也连接不上
Redis:单线程+多路IO复用 多路复用是指使用一个线程来检查多个文件描述符(Socket)的就绪状态,比如 调用select和poll函数,传入多个文件描述符,如果有一个文件描述符就绪,则返回,否则 阻塞直到超时。得到就绪状态后进行真正的操作可以在同一个线程里执行,也可以启动线程 执行(比如使用线程池) Memcached:多线程+锁
更多内容请关注公众号“测试小号等闲之辈”~















 1632
1632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









