







1. JPEG DCT
JPEG是众多常见的图像编码格式之一,主要分为无损压缩和有损压缩,无损压缩主要利用空域相关性进行预测,主要用于医学、卫星遥感等领域;而有损压缩主要通过DCT变换,然后进行量化来压缩数据。与现有的H264和H265视频编码标准中的整数DCT变换不同,JPEG中的DCT是浮点变换。为了加快DCT运算速度,libjpeg使用了三种DCT算法:分别是浮点DCT变换、整数化的DCT变换、快速整数DCT变换,由于硬件特性浮点DCT变换可能表现出不同的结果,整数化的DCT变换是将浮点值扩大2的幂次方倍(比如2的13次方倍),快速整数DCT变换也是整数化的DCT变换,但精度更小,误差更大。
1.1.JPEG DCT原理
在JPEG中是以8×8大小的图像块作为DCT变换的单位。8×8二维DCT定义如下:
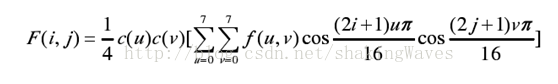
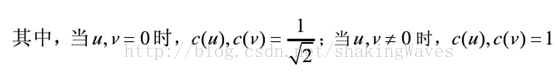
可以将其转换为如下公式,
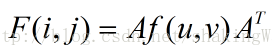
其中,矩阵A的值如下所示:

2. JPEG DCT蝶形变换
由于浮点运算和乘法运算比较耗时,所以libjpeg在做DCT变换的时候,采用了蝶形变换,通过合并同类项等,将乘法转换为加法,大大减少了运算量。
2.1.常规JPEG DCT蝶形变换
Libjpeg中的蝶形变换主要使用了“PRACTICAL FAST 1-D DCTALGORITHMS
WITH 11 MULTIPLICATIONS”文章中的算法。如下图1(a)所示,该图中 应该改为 ,图1(b)中O1写了2次,应该为一个O0一个O1。
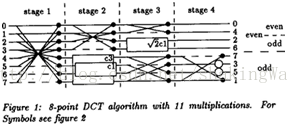
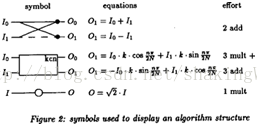
(a)蝶形变换 (b)注释
图1. LLM蝶形变换
将矩阵A和一个8×8的像素块按照矩阵乘法进行展开。可以得到如下的结果。
out[0] = a * ((in[0] + in[7]) + (in[3] + in[4])) + a * ((in[1] + in[6]) + (in[2] + in[5]));
out[4] = a * ((in[0] + in[7]) + (in[3] + in[4])) - a * ((in[2] + in[5]) + (in[1] + in[6]));
out[2] = c * ((in[0] + in[7]) - (in[3] + in[4])) + f * ((in[1] + in[6]) - (in[2] + in[5]))
= sin(6. * M_PI / 16.) * ((in[0] + in[7]) - (in[3] + in[4]))
+ cos(6. * M_PI / 16.) * ((in[1] + in[6]) - (in[2] + in[5]));
out[6] = f * ((in[0] + in[7]) - (in[3] + in[4])) + c * ((in[2] + in[5]) - (in[1] + in[6]))
= cos(6. * M_PI / 16.) * ((in[0] + in[7]) - (in[3] + in[4]))
- sin(6. * M_PI / 16.) * ((in[1] + in[6]) - (in[2] + in[5]));
out[3] = d * (in[0] - in[7]) - g * (in[1] - in[6]) - b * (in[2] - in[5]) - e * (in[3] - in[4])
= cos(3. * M_PI / 16.) * (in[0] - in[7]) - cos(7. * M_PI / 16.) * (in[1] - in[6])
- cos(1. * M_PI / 16.) * (in[2] - in[5]) - cos(5. * M_PI / 16.) * (in[3] - in[4])
= cos(3. * M_PI / 16.) * (in[0] - in[7]) - sin(1. * M_PI / 16.) * (in[1] - in[6])
- cos(1. * M_PI / 16.) * (in[2] - in[5]) - sin(3. * M_PI / 16.) * (in[3] - in[4])
= cos(3. * M_PI / 16.) * (in[0] - in[7]) - sin(3. * M_PI / 16.) * (in[3] - in[4])
- cos(1. * M_PI / 16.) * (in[2] - in[5]) - sin(1. * M_PI / 16.) * (in[1] - in[6]);
out[5] = e * (in[0] - in[7]) - b * (in[1] - in[6]) + g * (in[2] - in[5]) + d * (in[3] - in[4])
= cos(5. * M_PI / 16.) * (in[0] - in[7]) - cos(1. * M_PI / 16.) * (in[1] - in[6])
+ cos(7. * M_PI / 16.) * (in[2] - in[5]) + cos(3. * M_PI / 16.) * (in[3] - in[4])
= sin(3. * M_PI / 16.) * (in[0] - in[7]) - cos(1. * M_PI / 16.) * (in[1] - in[6])
+ sin(1. * M_PI / 16.) * (in[2] - in[5]) + cos(3. * M_PI / 16.) * (in[3] - in[4])
= sin(3. * M_PI / 16.) * (in[0] - in[7]) + cos(3. * M_PI / 16.) * (in[3] - in[4])
+ sin(1. * M_PI / 16.) * (in[2] - in[5]) - cos(1. * M_PI / 16.) * (in[1] - in[6]);
out[1] = b * (in[0] - in[7]) + d * (in[1] - in[6]) + e * (in[2] - in[5]) + g * (in[3] - in[4])
= cos(1. * M_PI / 16.) * (in[0] - in[7]) + cos(3. * M_PI / 16.) * (in[1] - in[6])
+ cos(5. * M_PI / 16.) * (in[2] - in[5]) + cos(7. * M_PI / 16.) * (in[3] - in[4])
= cos(1. * M_PI / 16.) * (in[0] - in[7]) + sin(1. * M_PI / 16.) * (in[3] - in[4])
+ sin(3. * M_PI / 16.) * (in[2] - in[5]) + cos(3. * M_PI / 16.) * (in[1] - in[6]);
= cos((4. - 3.) * M_PI / 16.) * (in[0] - in[7])
+ cos((4. + 3.) * M_PI / 16.) * (in[3] - in[4])
+ cos((4. + 1.) * M_PI / 16.) * (in[2] - in[5])
+ cos((4. - 1.) * M_PI / 16.) * (in[1] - in[6])
= (cos(4. * M_PI / 16.) * cos(3. * M_PI / 16.) + cos(4. * M_PI / 16.) * sin(3. * M_PI / 16.)) * (in[0] - in[7])
+ (cos(4. * M_PI / 16.) * cos(3. * M_PI / 16.) - cos(4. * M_PI / 16.) * sin(3. * M_PI / 16.)) * (in[3] - in[4])
+ (cos(4. * M_PI / 16.) * cos(1. * M_PI / 16.) - cos(4. * M_PI / 16.) * sin(1. * M_PI / 16.)) * (in[2] - in[5])
+ (cos(4. * M_PI / 16.) * cos(1. * M_PI / 16.) + cos(4. * M_PI / 16.) * sin(1. * M_PI / 16.)) * (in[1] - in[6])
= sqrt(1 / 2) * (cos(3. * M_PI / 16.) + sin(3. * M_PI / 16.)) * (in[0] - in[7])
+ sqrt(1 / 2) * (cos(3. * M_PI / 16.) - sin(3. * M_PI / 16.)) * (in[3] - in[4])
+ sqrt(1 / 2) * (cos(1. * M_PI / 16.) - sin(1. * M_PI / 16.)) * (in[2] - in[5])
+ sqrt(1 / 2) * (cos(1. * M_PI / 16.) + sin(1. * M_PI / 16.)) * (in[1] - in[6])
= sqrt(1 / 2) * (cos(3. * M_PI / 16.) * (in[0] - in[7]) - sin(3. * M_PI / 16.) * (in[3] - in[4]))
+ sqrt(1 / 2) * (sin(3. * M_PI / 16.) * (in[0] - in[7]) + cos(3. * M_PI / 16.) * (in[3] - in[4]))
+ sqrt(1 / 2) * (cos(1. * M_PI / 16.) * (in[2] - in[5]) + sin(1. * M_PI / 16.) * (in[1] - in[6]))
+ sqrt(1 / 2) * (-sin(1. * M_PI / 16.) * (in[2] - in[5]) + cos(1. * M_PI / 16.) * (in[1] - in[6]))
out[7] = g * (in[0] - in[7]) - e * (in[1] - in[6]) + d * (in[2] - in[5]) - b * (in[3] - in[4])
= cos(7. * M_PI / 16.) * (in[0] - in[7]) - cos(5. * M_PI / 16.) * (in[1] - in[6])
+ cos(3. * M_PI / 16.) * (in[2] - in[5]) - cos(1. * M_PI / 16.) * (in[3] - in[4])
= cos((4. + 3.) * M_PI / 16.) * (in[0] - in[7]) - cos((4 -3) * M_PI / 16.) * (in[3] - in[4])
- cos((4 + 1) * M_PI / 16.) * (in[1] - in[6]) + cos((4 - 1) * M_PI / 16.) * (in[2] - in[5])
= sqrt(1 / 2) * (cos(3. * M_PI / 16.) - sin(3. * M_PI / 16.)) * (in[0] - in[7])
- sqrt(1 / 2) * (cos(3. * M_PI / 16.) + sin(3. * M_PI / 16.)) * (in[3] - in[4])
- sqrt(1 / 2) * (cos(1. * M_PI / 16.) - sin(1. * M_PI / 16.)) * (in[1] - in[6])
+ sqrt(1 / 2) * (cos(1. * M_PI / 16.) + sin(1. * M_PI / 16.)) * (in[2] - in[5])
= sqrt(1 / 2) * (cos(3. * M_PI / 16.) * (in[0] - in[7]) - sin(3. * M_PI / 16.) * (in[3] - in[4]))
- sqrt(1 / 2) * (sin(3. * M_PI / 16.) * (in[0] - in[7]) + cos(3. * M_PI / 16.) * (in[3] - in[4]))
- sqrt(1 / 2) * (cos(1. * M_PI / 16.) * (in[1] - in[6]) - sin(1. * M_PI / 16.) * (in[2] - in[5]))
+ sqrt(1 / 2) * (sin(1. * M_PI / 16.) * (in[1] - in[6]) + cos(1. * M_PI / 16.) * (in[2] - in[5]))所以,图1(a)的具体实现如下:
// Naive implementation of LLM DCT.
// Easier to read, but uses more multiplications for rotation.
void llm_dct(const double in[8], double out[8]) {
// After stage 1:
const double s1_0 = in[0] + in[7];
const double s1_1 = in[1] + in[6];
const double s1_2 = in[2] + in[5];
const double s1_3 = in[3] + in[4];
const double s1_4 = -in[4] + in[3];
const double s1_5 = -in[5] + in[2];
const double s1_6 = -in[6] + in[1];
const double s1_7 = -in[7] + in[0];
// After stage 2:
const double s2_0 = s1_0 + s1_3;
const double s2_1 = s1_1 + s1_2;
const double s2_2 = -s1_2 + s1_1;
const double s2_3 = -s1_3 + s1_0;
const double s2_4 = s1_4 * cos(3. * M_PI / 16.) + s1_7 * sin(3. * M_PI / 16.);
const double s2_7 = -s1_4 * sin(3. * M_PI / 16.) + s1_7 * cos(3. * M_PI / 16.);
const double s2_5 = s1_5 * cos(1. * M_PI / 16.) + s1_6 * sin(1. * M_PI / 16.);
const double s2_6 = -s1_5 * sin(1. * M_PI / 16.) + s1_6 * cos(1. * M_PI / 16.);
// After stage 3:
const double s3_0 = s2_0 + s2_1;
const double s3_1 = -s2_1 + s2_0;
const double s3_2 = sqrt(2.) * ( s2_2 * cos(6. * M_PI / 16.) + s2_3 * sin(6. * M_PI / 16.));
const double s3_3 = sqrt(2.) * (-s2_2 * sin(6. * M_PI / 16.) + s2_3 * cos(6. * M_PI / 16.));
const double s3_4 = s2_4 + s2_6;
const double s3_5 = -s2_5 + s2_7;
const double s3_6 = -s2_6 + s2_4;
const double s3_7 = s2_7 + s2_5;
// After stage 4:
const double s4_4 = -s3_4 + s3_7;
const double s4_5 = s3_5 * sqrt(2.);
const double s4_6 = s3_6 * sqrt(2.);
const double s4_7 = s3_7 + s3_4;
// Shuffle and scaling:
out[0] = s3_0 / sqrt(8.);
out[4] = s3_1 / sqrt(8.);
out[2] = s3_2 / sqrt(8.);
out[6] = s3_3 / sqrt(8.);
out[7] = s4_4 / sqrt(8.);
out[3] = s4_5 / sqrt(8.);
out[5] = s4_6 / sqrt(8.);
out[1] = s4_7 / sqrt(8.);
}2.2.旋转操作
在LLM蝶形变换的stage2和stage3阶段用到的乘法和加法操作较多,可以通过旋转操作的方法,减少运算,如图2所示。
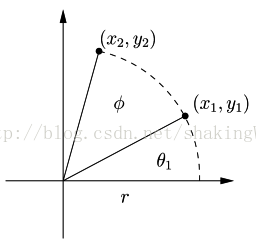
图2. 旋转操作
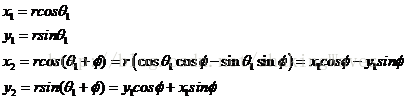
旋转操作的基本算法如下:
void rot1(const double x1, const double y1, const double theta,
double* x2, double* y2) {
const double s = sin(theta);
const double c = cos(theta);
*x2 = x1 * c - y1 * s;
*y2 = y1 * c + x1 * s;
}该操作需要4个乘法,1个加法,1个减法。
对基本的操作进行一些变形可以得到如下所示的算法:
void rot2(const double x1, const double y1, const double theta,
double* x2, double* y2) {
const double s = sin(theta);
const double c = cos(theta);
const double z = x1 * (s + c);
*x2 = z - (x1 + y1) * s;
*y2 = z + (y1 - x1) * c;
}该操作需要3个乘法,3个加法,2个减法
如果旋转的角度是个常量,可以优化成下面所示的算法:
void rot3(const double x1, const double y1,
double* x2, double* y2) {
const double s = sin(1. * M_PI / 16.);
const double c = cos(1. * M_PI / 16.);
const double z = c * (x1 + y1);
*x2 = (-s-c) * y1 + z;
*y2 = ( s-c) * x1 + z;
}该操作需要3个乘法3个加法,因为(-s-c)和(s-c)是常量,可以提前计算他们的值。
经过旋转优化后的蝶形变换算法如下所示:
// Implementation of LLM DCT.
void llm_dct(const double in[8], double out[8]) {
// Constants:
const double s1 = sin(1. * M_PI / 16.);
const double c1 = cos(1. * M_PI / 16.);
const double s3 = sin(3. * M_PI / 16.);
const double c3 = cos(3. * M_PI / 16.);
const double r2s6 = sqrt(2.) * sin(6. * M_PI / 16.);
const double r2c6 = sqrt(2.) * cos(6. * M_PI / 16.);
// After stage 1:
const double s1_0 = in[0] + in[7];
const double s1_1 = in[1] + in[6];
const double s1_2 = in[2] + in[5];
const double s1_3 = in[3] + in[4];
const double s1_4 = -in[4] + in[3];
const double s1_5 = -in[5] + in[2];
const double s1_6 = -in[6] + in[1];
const double s1_7 = -in[7] + in[0];
// After stage 2:
const double s2_0 = s1_0 + s1_3;
const double s2_1 = s1_1 + s1_2;
const double s2_2 = -s1_2 + s1_1;
const double s2_3 = -s1_3 + s1_0;
const double z1 = c3 * (s1_7 + s1_4);
const double s2_4 = ( s3-c3) * s1_7 + z1;
const double s2_7 = (-s3-c3) * s1_4 + z1;
const double z2 = c1 * (s1_6 + s1_5);
const double s2_5 = ( s1-c1) * s1_6 + z2;
const double s2_6 = (-s1-c1) * s1_5 + z2;
// After stage 3:
const double s3_0 = s2_0 + s2_1;
const double s3_1 = -s2_1 + s2_0;
const double z3 = r2c6 * (s2_3 + s2_2);
const double s3_2 = ( r2s6-r2c6) * s2_3 + z3;
const double s3_3 = (-r2s6-r2c6) * s2_2 + z3;
const double s3_4 = s2_4 + s2_6;
const double s3_5 = -s2_5 + s2_7;
const double s3_6 = -s2_6 + s2_4;
const double s3_7 = s2_7 + s2_5;
// After stage 4:
const double s4_4 = -s3_4 + s3_7;
const double s4_5 = s3_5 * sqrt(2.);
const double s4_6 = s3_6 * sqrt(2.);
const double s4_7 = s3_7 + s3_4;
// Shuffle and scaling:
out[0] = s3_0 / sqrt(8.);
out[4] = s3_1 / sqrt(8.);
out[2] = s3_2 / sqrt(8.);
out[6] = s3_3 / sqrt(8.);
out[7] = s4_4 / sqrt(8.);
out[3] = s4_5 / sqrt(8.); // Alternative: s3_5 / 2
out[5] = s4_6 / sqrt(8.);
out[1] = s4_7 / sqrt(8.);
}2.3.JPEG DCT奇数部分优化
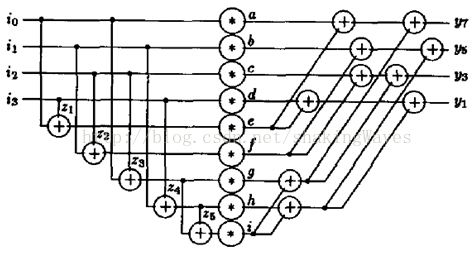
上图中的奇数部分算法最多的时候需要2个乘法操作,仍然不够优化,所以论文中对奇数部分的y1、y3、y5和y7使用了新的算法,如图3所示。图3(a)中,i0、i1、i2和i3是图1(a)中stage2部分的输入,例如:y7=-c1*i0+c3*i1-c5*i2+c7*i3。
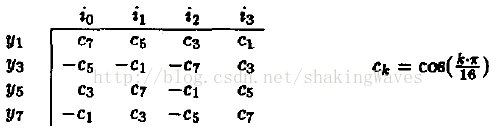
(a)
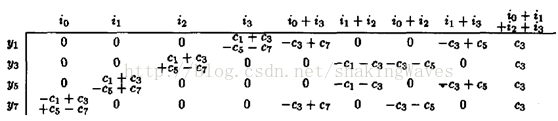
(b)

(c)
(d)
图3. 奇数部分优化
图3(b)和3(c)是根据3(a)进行的扩展优化,最终得到图(d)所示的蝶形变换图。














 1457
1457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









