







Hadoop是一个实现了mapreduce 模式的开源的分布式并行编程框架。
mapreduce模式的主要思想是将自动分割要执行的问题拆解成map(映射)和reduce(化简)的方式,流程图如下图所示:
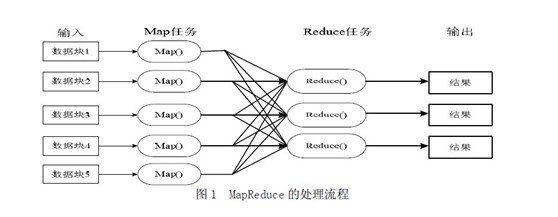
大致可以认为,Hadoop=HDFS(文件系统)+HBase(数据库)+MapReduce(数据处理)。
◆HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanode组成。Namenode是一个中心服务器,负责管理文件系统的namespace和客户端对文件的访问。Datanode在集群中一般是一个节点一个,负责管理节点上它们附带的存储。在内部,一个文件其实分成一个或多个block,这些block存储在Datanode集合里。如下图所示:
◆一个MapReduce作业(job)通常会把输入的数据集切分为若干独立的数据块,由 Map任务(task)以完全并行的方式处理它们。框架会对Map的输出先进行排序,然后把结果输入给Reduce任务。通常作业的输入和输出都会被存储在文件系统中。整个框架负责任务的调度和监控,以及重新执行已经失败的任务。
◆ HBase是一个分布式的、面向列的开源数据库,它不同于一般的关系数据库,是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。HBase使用和 BigTable非常相同的数据模型。用户存储数据行在一个表里。一个数据行拥有一个可选择的键和任意数量的列,一个或多个列组成一个ColumnFamily,一个Fmaily下的列位于一个HFile中,易于缓存数据。表是疏松的存储的,因此用户可以给行定义各种不同的列。在HBase中数据按主键排序,同时表按主键划分为多个HRegion。
案例㈠: 淘宝海量数据产品技术架构
淘宝的海量数据产品技术架构,分为以下五个层次,从上至下来看,它们分别是:数据源,计算层,存储层,查询层和产品层。
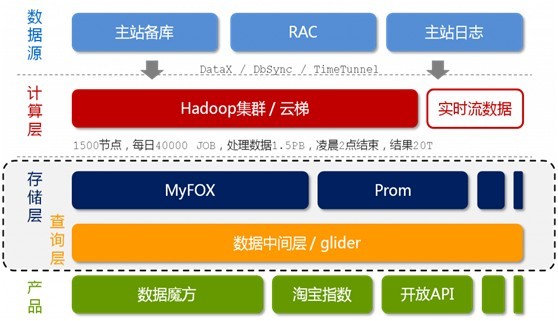
数据源层,存放着淘宝各店的交易数据。在数据源层产生的数据,通过DataX、DbSync和Timetunel准实时的传输到下面第2点所述的“云梯”。
计算层,在这个计算层内,淘宝采用的是hadoop集群,暂称之为云梯,是计算层的主要组成部分。在云梯上,系统每天会对数据产品进行不同的mapreduce计算。
存储层,淘宝采用了两个东东:一个使MyFox,一个是Prom。MyFox是基于MySQL的分布式关系型数据库的集群,Prom是基于hadoop Hbase技术 的一个NoSQL的存储集群。
查询层,有一个叫做glider的东东,它是以HTTP协议对外提供restful方式的接口。数据产品通过一个唯一的URL来获取到它想要的数据。
参考文献:
(1)从hadoop框架与MapReduce模式中谈海量数据处理
















 1877
1877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









