






💥 “还在为千亿模型租天价显卡?清华团队用CPU/GPU协同计算,让4090跑起671B参数全量模型!”
如果你也经历过——
-
💸 看着API调用账单瑟瑟发抖,微调一次模型吃掉半月算力预算
-
🖥️ 盯着OOM报错抓狂,为了跑通模型不得不阉割关键参数
-
⏳ 等着预处理结果打瞌睡,长文本任务动辄消耗咖啡+泡面时间…
今天介绍的 KTransformers 将彻底改写游戏规则!这个由清华大学KVCache.AI团队与趋境科技联合研发的开源框架,通过GPU/CPU异构计算与MoE架构深度优化,实现了:
-
✅ 24GB显存运行671B满血模型 —— 消费级显卡的逆袭
-
✅ 286 tokens/s预处理速度 —— 比传统方案快28倍的闪电响应
-
✅ CUDA Graph+4bit量化 —— 让千亿模型部署进家用电脑
从AI初创团队到高校实验室,开发者们正在用它突破算力围城。接下来我们将深入解析其MoE卸载策略与Marlin算子优化,手把手教你在本地搭建千亿级AI推理引擎!
🚀 快速阅读
KTransformers 是一个开源的大语言模型推理优化框架,旨在通过GPU/CPU异构计算策略和MoE架构的稀疏性,显著提升大模型的推理速度并降低硬件要求。
-
核心功能:支持在仅24GB显存的单张显卡上运行671B参数的满血版大模型,预处理速度最高可达286 tokens/s,推理生成速度达14 tokens/s。
-
技术原理:基于MoE架构的稀疏矩阵卸载、offload策略、高性能算子优化和CUDA Graph优化等技术,大幅降低显存需求并提升推理效率。
KTransformers 是什么
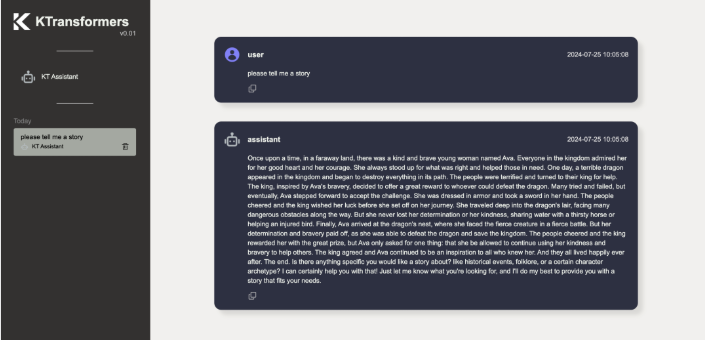
KTransformers 是由清华大学 KVCache.AI 团队联合趋境科技推出的开源项目,旨在优化大语言模型的推理性能,降低硬件门槛。它基于 GPU/CPU 异构计算策略,利用 MoE 架构的稀疏性,支持在仅 24GB 显存的单张显卡上运行 DeepSeek-R1、V3 等 671B 参数的满血版大模型,预处理速度最高可达 286 tokens/s,推理生成速度最高能达到 14 tokens/s。
项目通过基于计算强度的 offload 策略、高性能算子和 CUDA Graph 优化等技术,显著提升了推理速度,使得普通用户和中小团队能够在消费级硬件上运行千亿级参数模型,实现“家庭化”部署。
KTransformers 的主要功能
-
支持超大模型的本地推理:支持在仅 24GB 显存的单张显卡上运行 DeepSeek-R1 等 671B 参数的满血版大模型,打破传统硬件限制。
-
提升推理速度:预处理速度最高可达 286 tokens/s,推理生成速度达 14 tokens/s。
-
兼容多种模型和算子:支持 DeepSeek 系列及其他 MoE 架构模型,提供灵活的模板注入框架,支持用户切换量化策略和内核替换,适应不同优化需求。
-
降低硬件门槛:将大模型的显存需求大幅降低,让普通用户和中小团队能在消费级硬件上运行千亿级参数模型,实现“家庭化”部署。
-
支持长序列任务:整合 Intel AMX 指令集,CPU 预填充速度可达 286 tokens/s,相比传统方案快 28 倍,将长序列任务的处理时间从“分钟级”缩短到“秒级”。
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

KTransformers 的技术原理
-
MoE架构:将稀疏的 MoE 矩阵卸载到 CPU/DRAM 上处理,稠密部分保留在 GPU 上,大幅降低显存需求。
-
offload策略:根据计算强度将任务分配到 GPU 和 CPU:计算强度高的任务(如 MLA 算子)优先分配到 GPU,计算强度低的任务分配到 CPU。
-
高性能算子优化:
-
CPU端:用 llamafile 作为 CPU 内核,结合多线程、任务调度、负载均衡等优化,提升 CPU 推理效率。
-
GPU端:引入 Marlin 算子,专门优化量化矩阵计算,相比传统库(如 Torch)实现 3.87 倍的加速效果。
-
CUDA Graph 优化:基于 CUDA Graph 减少 Python 调用开销,降低 CPU/GPU 通信的断点,实现高效的异构计算协同。每次 decode 仅需一个完整的 CUDA Graph 调用,显著提升推理性能。
-
量化与存储优化:采用 4bit 量化技术,进一步压缩模型存储需求,仅需 24GB 显存即可运行 671B 参数模型。同时优化 KV 缓存大小,减少存储开销。
-
模板注入框架:提供基于 YAML 的模板注入框架,支持用户灵活切换量化策略、内核替换等优化方式,适应不同场景的需求。
如何运行 KTransformers
准备工作
在开始安装和运行 KTransformers 之前,您需要确保系统满足以下依赖项:
1. 安装 CUDA
确保您的系统安装了 CUDA 12.1 或更高版本。如果没有安装,可以从NVIDIA 官方网站下载并安装。安装完成后,添加 CUDA 到系统路径:
- NVIDIA 官方网站:
https://developer.nvidia.com/cuda-downloads
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
export CUDA_PATH=/usr/local/cuda
2. 安装编译工具
确保您的 Linux 系统安装了 GCC、G++ 和 CMake。可以使用以下命令安装:
sudo apt-get update
sudo apt-get install gcc g++ cmake ninja-build
3. 创建 Python 虚拟环境
推荐使用 Conda 创建一个 Python 3.11 的虚拟环境来运行程序。可以通过以下命令创建并激活环境:
conda create --name ktransformers python=3.11
conda activate ktransformers
如果您是首次使用 Conda,可能需要先运行 conda init 并重新打开终端。
4. 安装依赖库
确保安装了 PyTorch、packaging、ninja 等依赖库:
pip install torch packaging ninja cpufeature numpy
安装 KTransformers
1. 下载源代码并编译
首先,克隆 KTransformers 的 GitHub 仓库并初始化子模块:
git clone https://github.com/kvcache-ai/ktransformers.git
cd ktransformers
git submodule init
git submodule update
如果您需要运行带有 Web 界面的版本,请先编译 Web 界面(可选):
# 请参考相关文档进行编译
然后根据您的操作系统选择安装方式:
1.1 Linux 系统
对于普通用户,可以使用简单的安装脚本:
bash install.sh
如果您有双 CPU 和 1TB 内存的服务器,可以启用 NUMA 优化:
export USE_NUMA=1
bash install.sh
1.2 Windows 系统
在 Windows 系统上,使用 install.bat 脚本进行安装:
install.bat
2. 使用 Makefile 编译和格式化代码
如果您是开发者,可以使用 Makefile 来编译和格式化代码。Makefile 的详细用法请参考相关文档。
- 相关文档:
https://github.com/kvcache-ai/ktransformers/doc/en/makefile_usage.html
本地聊天测试
KTransformers 提供了一个简单的命令行本地聊天脚本,用于测试模型。请注意,这是一个非常简单的测试工具,仅支持一轮对话,不保留历史输入。如果您想体验模型的完整功能,建议使用 RESTful API 和 Web UI。
运行示例
- 下载模型权重:
# 在克隆的仓库根目录下执行以下命令
mkdir DeepSeek-V2-Lite-Chat-GGUF
cd DeepSeek-V2-Lite-Chat-GGUF
wget https://huggingface.co/mzwing/DeepSeek-V2-Lite-Chat-GGUF/resolve/main/DeepSeek-V2-Lite-Chat.Q4_K_M.gguf -O DeepSeek-V2-Lite-Chat.Q4_K_M.gguf
cd ..
- 启动本地聊天:
python -m ktransformers.local_chat --model_path deepseek-ai/DeepSeek-V2-Lite-Chat --gguf_path ./DeepSeek-V2-Lite-Chat-GGUF
如果遇到连接 Hugging Face 的问题,可以尝试以下命令:
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/deepseek-ai/DeepSeek-V2-Lite
python -m ktransformers.local_chat --model_path ./DeepSeek-V2-Lite --gguf_path ./DeepSeek-V2-Lite-Chat-GGUF
支持的模型和量化格式
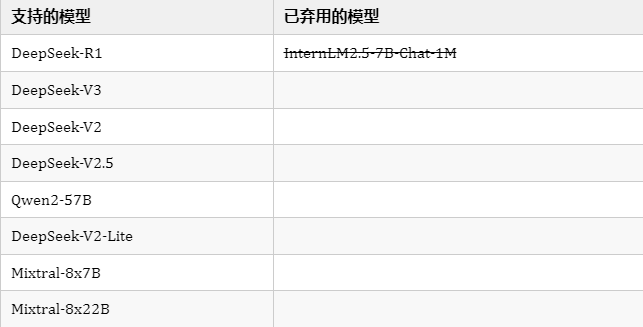
1. 支持的模型
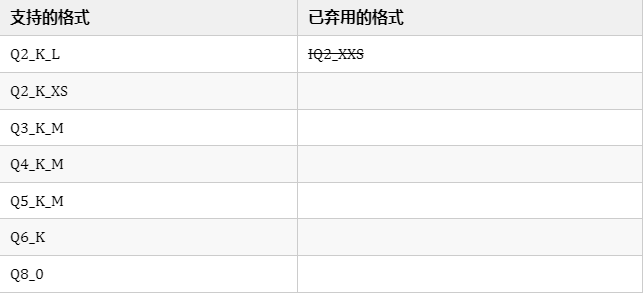
2. 支持的量化格式
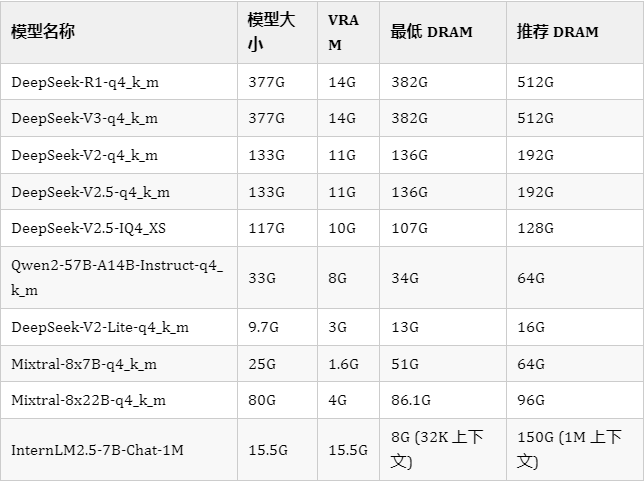
推荐的模型配置
RESTful API 和 Web UI(已弃用)
1. 无 Web 界面启动
ktransformers --model_path deepseek-ai/DeepSeek-V2-Lite-Chat --gguf_path /path/to/DeepSeek-V2-Lite-Chat-GGUF --port 10002
2. 带 Web 界面启动
ktransformers --model_path deepseek-ai/DeepSeek-V2-Lite-Chat --gguf_path /path/to/DeepSeek-V2-Lite-Chat-GGUF --port 10002 --web True
3. 使用 Transformers 启动
如果您想使用 Transformers 启动服务器,model_path 需要包含 .safetensors 文件:
ktransformers --type transformers --model_path /mnt/data/model/Qwen2-0.5B-Instruct --port 10002 --web True
访问 Web 界面的 URL 为:http://localhost:10002/web/index.html#/chat
更多关于 RESTful API 服务器的信息,请参考相关文档。您还可以参考Tabby 集成示例。
-
相关文档:
https://github.com/kvcache-ai/ktransformers/doc/en/api/server/server.html -
Tabby 集成示例:
https://github.com/kvcache-ai/ktransformers/doc/en/api/server/tabby.html
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料。包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程扫描领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程扫描领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程扫描领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程扫描领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程扫描领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓

















 1163
1163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









