









最近拜读了John Wright和Yi Ma2010年在Proceedings of the IEEE上关于稀疏表示的大作 :Sparse Representation for Computer Vision and Pattern Recognition 。下面是对这篇文章的一点总结。
本文地址:http://blog.csdn.net/shanglianlm/article/details/46603823
稀疏表示的核心:
A relatively small sample of computer vision and pattern recognition information in applications such as face recognition is often sufficient to reveal the meaning the user desires.
作者:一票牛人云集
By John Wright (UIUC), Member IEEE, Yi Ma (UIUC), Senior Member IEEE, Julien Mairal, Member IEEE, Guillermo Sapiro, Senior Member IEEE, Thomas S. Huang (UIUC), Life Fellow IEEE, and Shuicheng Yan (NUS), Senior Member IEEE
I .导言( INTRODUCTION)
本文主要从人脸识别,L1-图的构建和字典学习三个方面来对稀疏编码在计算机视觉和模式识别中的应用来做一个简单的总结。
II . 鲁棒人脸识别:理论与实践的融合(ROBUST FACE RECOGNITION: CONFLUENCE OF PRACTICE AND THEORY)
A. 从理论到实践:人脸识别作为稀疏表示(From Theory to Practice: Face Recognition as Sparse Representation)
来自
c
(未知)个类别(
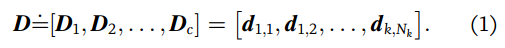
则x可以被表示为:

其中
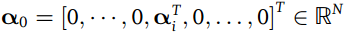
但是实际应用中由于部分腐蚀和遮挡的的存在,使得获得的部分数据产生错误。考虑到这些因素,因此我们修改上面的公式为:
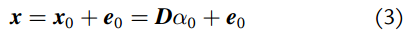
很明显,(3)中的未知数数量多于已知数的数量,因此我们不能直接求解
α0
。但是在自然条件下[2](扯淡条件,很多东西没解的时候,一加个自然或者特定条件就有解了),获得的解
(α0,e0)
不仅是稀疏的而且是(3)的最稀疏解。
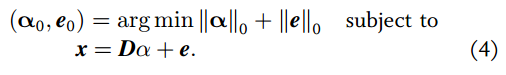
受[5][6]工作中关于L0和L1等价的理论的启发,John Wright 在[4]中提出用下列公式求解
α0
。

图Fig.1显示了稀疏表示将人脸和遮挡和腐蚀区分开来的案例。

B. 从实践到理论:利用L1最小化进行密集误差修正(From Practice to Theory: Dense Error Correction by L1 -Minimization)
尽管前文中的实验结果表明基于稀疏的方法能获得一个较好的结果,但它仍然需要一个与之相适应的理论依据来保证它。但是欠定线性方程系统(3)并不能满足使L1最小化能正确的稀疏恢复的条件。
理论验证:(后补)
C. 基于稀疏的识别的评论(Remarks on Sparsity-Based Recognition)
尽管很多实验结果显示了基于稀疏的人脸识别取得很好的实验结果。但是这些实验要求:
1. 训练数据是精心可控的(即人为有意选择的);
2. 每类的样本数据非常大。
此外,虽然‘’十字架-花束“模型解释了L1最小化的多数的纠错能力,但是稀疏表示的能力仍然缺乏一个严格的数学解释。
III . L1图(L1 - GRAPHS)
前面介绍的人脸识别基于显式的线性光照模型,接下来我们在缺乏一个显式的线性模型的情况下讨论更一般的情况。我们引入L1-图,把通过L1最小化获得的系数解释为一个有向图的权重。
L1图的构建:

接着,作者讨论了L1-图可以应用于机器学习任务中例如谱聚类,子空间聚类,半监督学习上。并给出了一些实验结果。
尽管L1-图在很多实验上去的不错的效果,但是L1-图到底在什么条件下能取得好的结果仍然值得探讨。
IV . 用于图像分析的字典学习(DICTIONARY LEARNING FOR IMAGE ANALYSIS)
本章主要讨论用于不同学习任务的字典的学习。
A. 用于图像重建的稀疏建模(Sparse Modeling for Image Reconstruction)
A是字典
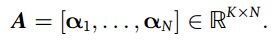
同时优化:
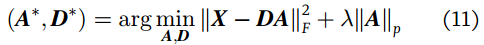
B. 用于图像分类的稀疏建模(Sparse Modeling for Image Classification)
主要参考一下三篇文献:
J. Mairal, F. Bach, J. Ponce, G. Sapiro, and A. Zisserman, “Learning discriminative dictionaries for local image analysis,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit., 2008, DOI: 10.1109/CVPR.2008. 4587652.
J. Mairal, F. Bach, J. Ponce, G. Sapiro, and A. Zisserman, “Supervised dictionary learning,” In Advances in Neural Information Processing Systems, vol. 21, D. Koller, D. Schuurmans, Y. Bengio, and L. Bottou, Eds. Cambridge, MA: MIT Press, 2009.
J. Mairal, M. Leordeanu, F. Bach, M. Hebert, and J. Ponce, “Discriminative sparse image models for class-specific edge detection and image interpretation,” presented at the Eur. Conf. Comput. Vis., Marseille, France, Oct.12–18, 2008.
学习多个字典,并且对应的字典对当前数据提供好的表示,对其他数据提供不好的表示,即同时正负样本学习。
C. 感知学习(Learning to Sense)
[7] 扩展(11),把感知矩阵也加入同时优化:
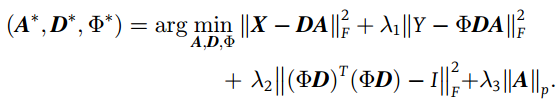
参考及延伸阅读材料:
[1]Sparse Representation for Computer Vision and Pattern Recognition
[2]Optimally sparse representation in general (nonorthogonal) dictionaries via ℓ1 minimization
[3]Dense error correction via L1-minimization
[4]Robust face recognition via sparse representation
[5]Decoding by linear programming
[6]For most large underdetermined systems of linear equations the minimal L1-norm solution is also the sparsest solution
[7]Learning to sense sparse signals: Simultaneous sensing matrix and sparsifying dictionary optimization














 1447
1447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









