









在分布式系统中,达成共识意味着什么
目前,我们已经知道分布式系统有以下特性:
- 进程的并发性
- 全局时钟缺失
- 组件可能出错
- 消息需时传递
接下来我们会聚焦分布式系统中,“达成共识”究竟是什么意思。首先有一件很重要的事情得重申一下,“分布式计算有数百种软硬件架构”;而最常见的形式称为复制状态机。
复制状态机
复制状态机是一种确定性状态机,它在许多计算机上存有副本,但整个系统就像单个状态机那样运行。任何一台计算机都有出错的可能,但状态机依然能正常运行。

-作者制图-
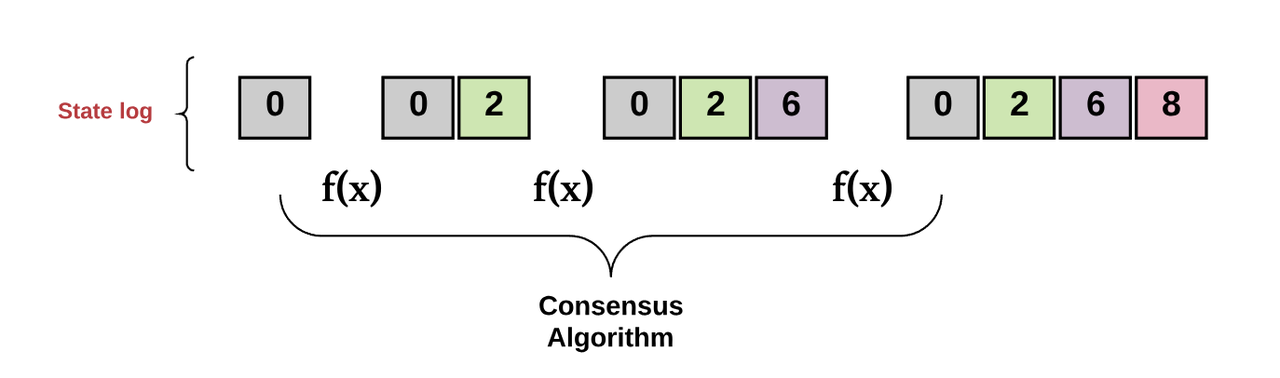
在复制状态机中,如果出现一个有效事务(transaction),则事务的输入集会使得系统的状态转变为下一个状态。事务对数据库进行原子性的操作,这意味着操作要么整个完成,要么等于完全没发生。在复制状态机内维护的事务集合又称为“事务日志”;从一个有效状态转变为下一个有效状态的逻辑,称为“状态转变逻辑”。

-作者制图-
换言之,复制状态机是一个分布式计算机的集合,这些计算机都有相同初值。每一次状态的转变方式、下个状态是什么,都由相关的进程决定。所谓“达成共识”,意思是全体计算机都同意某个输出的值。
反过来说,“达成共识”也意味着让系统中每一台计算机的事务日志保持一致(也就是它们“达成了共同目标”)。合格的复制状态机,即使发生以下情况,仍必须不断将新的事务接收进日志(即“提供有效服务”):
- 有些计算机发生故障。
- 网络不可靠,消息可能出现延迟、传送失败,或排序混乱。
- 没有全局时钟来确定事务顺序。
朋友们,这就是所有共识算法的基本目标。
-作者制图-
共识问题的定义
只要能满足以下条件,我们就说某算法可以实现分布式共识:
- Agreement(一致性) :所有非故障节点,都会选择相同的输出值。
- Termination(可终止性):所有非故障节点,最终都选定了某些输出值,不再反悔。
注意:不同的算法会满足上述条件的不同变体。举例来说,某些算法会将 Agreement 拆分为一致性和总体性;一些算法还加入了有效性(validity)、完整性(integrity),或效率的概念。这些细微的区别不在本文讨论范围。
广义来说,共识算法一般会假设系统中有三种角色:
- 提案者(Proposers):常被称为领导者或协调者。
- 接收者(Acceptors):进程,监听提案者的请求并给出响应值。
- 学习者(Learners):系统里的其他进程,接收最终决定的值。
因此,正常情况下,我们能通过三个步骤定义来共识算法:
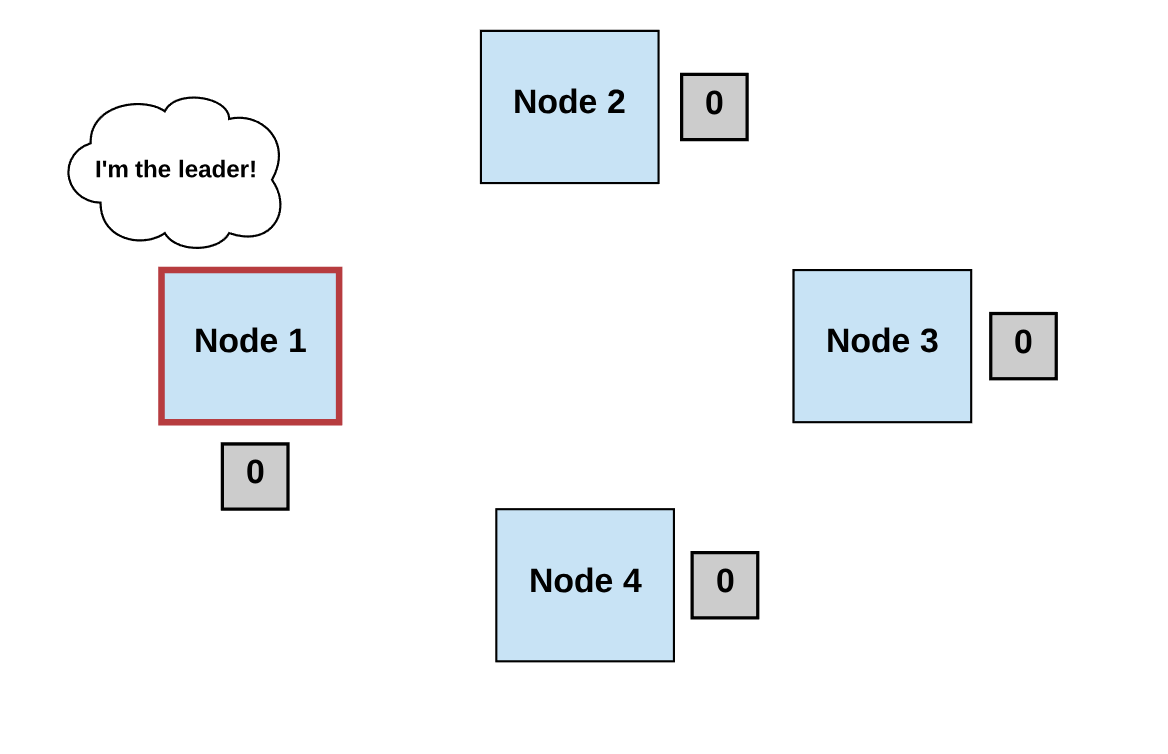
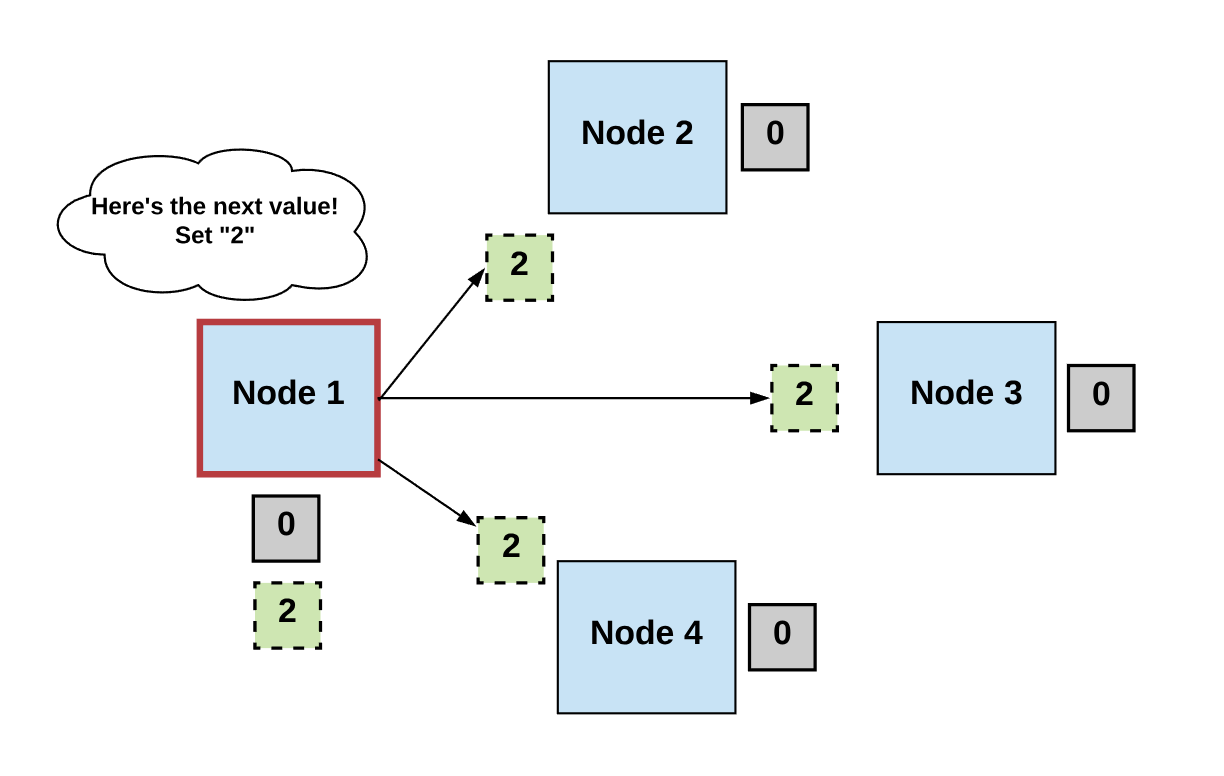
第一步:选举 Elect
- 所有进程推举出某个进程(领导者)来做决策。
- 领导者提出下一个有效的输出值。
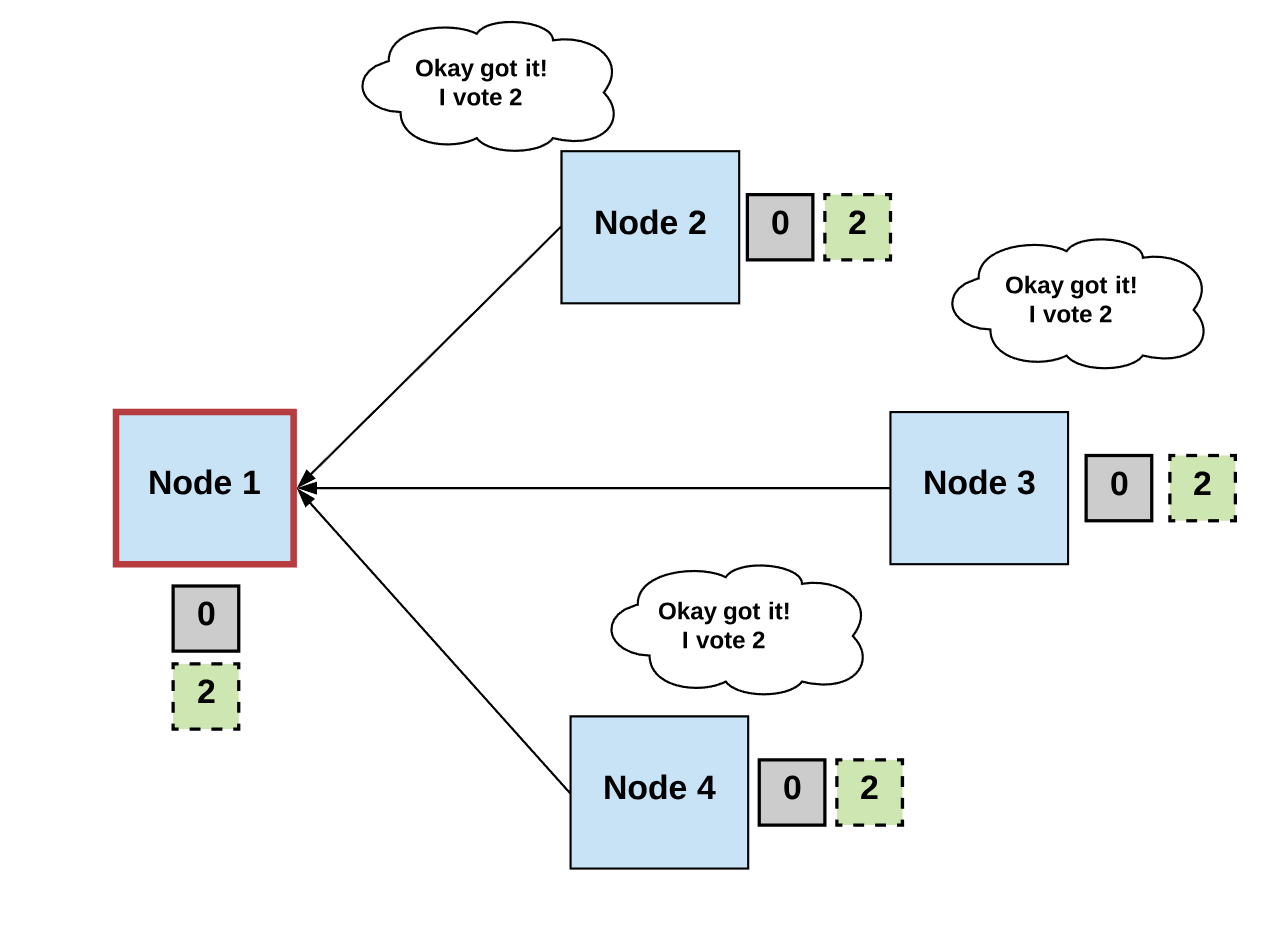
第二步:投票 Vote
- 非故障进程会监听领导者进程提出的值,并验证这个值。然后将它作为下一个有效值提出。
第三步:决定 Decide
- 非故障节点必须就单个正确的值达成共识。如果这个值收到满足某个阈值条件的投票数,那么全体进程就会同意这个值为最终共识值。
- 如果没有达到条件,则重新进行上面步骤。
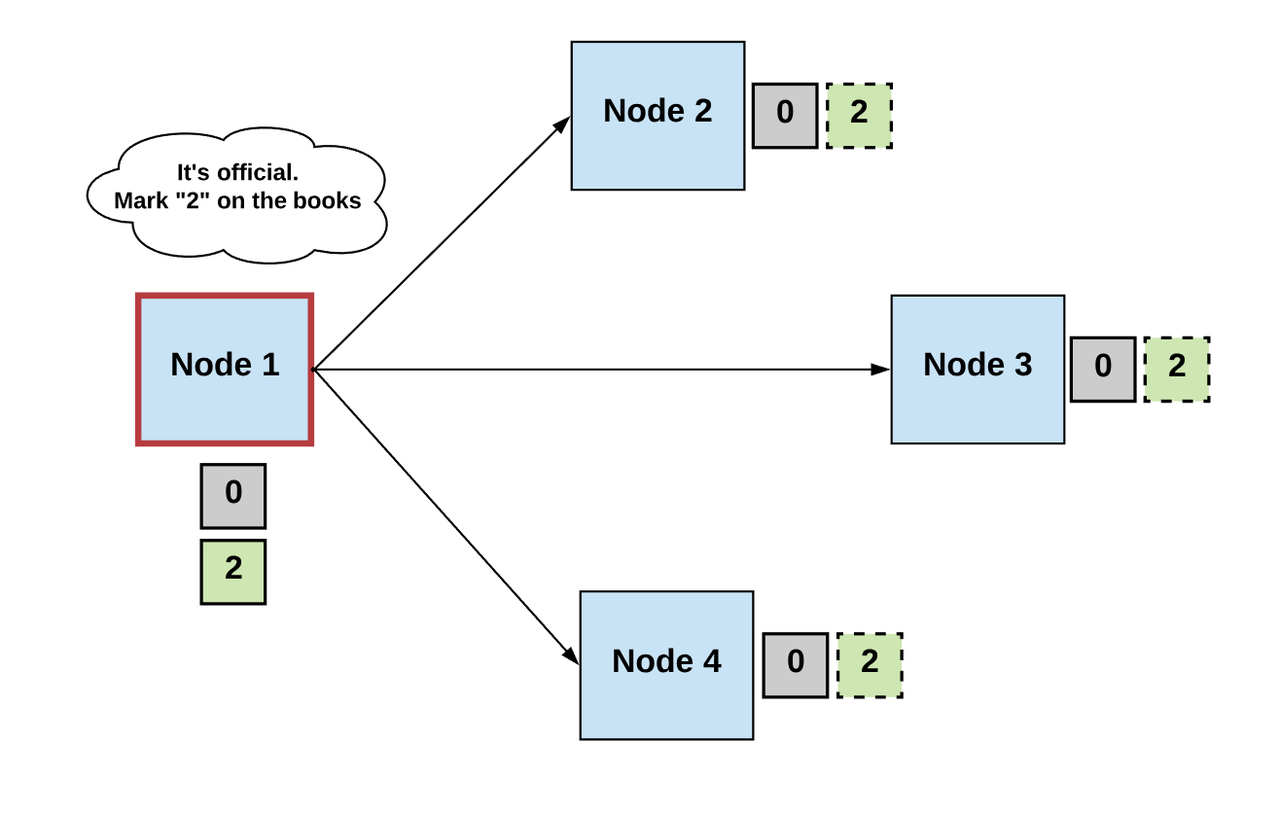
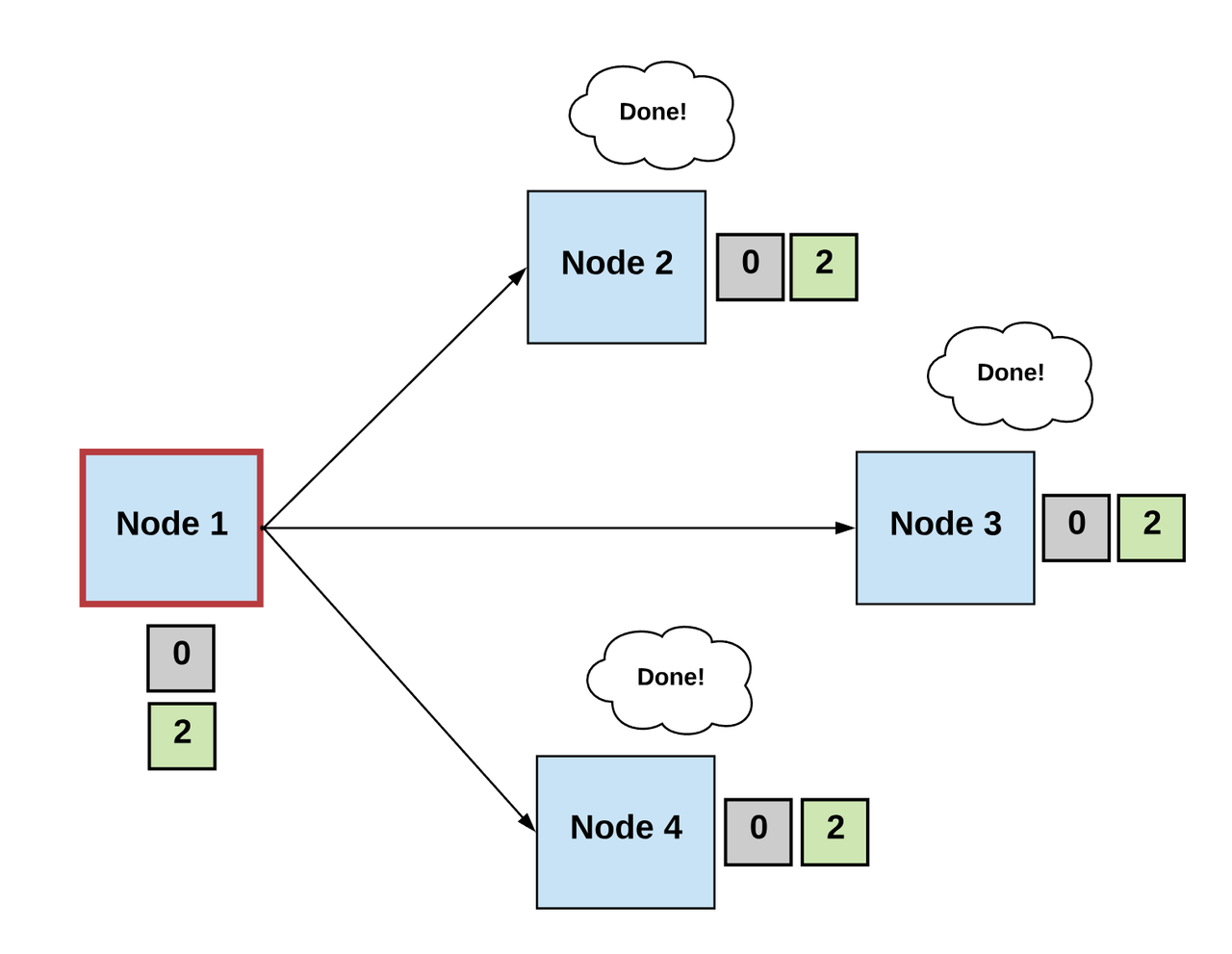
-作者制图-
值得注意的是,每个共识算法都会有些许不同,比如:
- 术语(如,轮次(round)、阶段(phase))
- 投票如何进行的,以及
- 决定最终值的标准(例如:验证条件)。
尽管如此,如果我们能以通用的过程构造共识算法,并保证满足上述的基本条件,那我们就有了一个能够达成共识的分布式系统。
你以为非常简单,对吧?
FLP 不可能定理
......并非如此,说不定你已经预见到了!
回想一下,我们是如何描述同步系统和异步系统之间的区别的:
- 同步通信情况下,消息会在固定时间范围内发送。
- 异步通信情况下,无法保证消息的传递。
这个差异非常重要。
在同步通信环境下有可能达成共识,因为我们能够假设消息传递需要的最长时间。因此在同步消息系统,我们允许不同的节点轮流成为提案者、进行多数投票,并跳过那些没有在最长等待时间内提交提案的节点。
但正如我们前面提到的,跳脱出可控(即消息延时可以预测)的环境(比如,具有同步原子钟的数据中心之类的可控环境),假设操作发生在同步通信环境里是不切实际的。
事实上,多数时候我们无法假设同步通信,所以我们的设计必须面向异步通信环境。
在异步通信环境中,因为我们无法假设一个最大的消息传递时间,想要达成 termination 条件是非常困难的。回忆下,要达成共识的其中一项条件是“可终止性”,也就是说每个非故障节点最终都必须选定某组相同的输出值,而不能永远迟疑不决。
这也就是大家熟知的“ FLP 不可能性 ”。它是怎么得到这个名字的?我很高兴你这么问了。
1985年,研究员 Fischer、Lynch 和 Paterson (FLP)在他们的论文《Impossibility of Distributed Consensus with One Faulty Process》中描述了为什么在异步通信环境下,单个进程故障也会导致共识无法达成。
简单来说,因为进程可能在任何时间出错,所以也有可能发生在正好会影响共识达成的时间点。

-亮点自寻-
这个结果对分布式计算领域带来重大打击,但即使如此,科学家仍在不断尝试避开 FLP 不可能性问题的方法。
抽象一点来说,有两个方法能够避开 FLP 不可能性问题:
- 使用同步性假设
- 使用非确定性机制
(未完)
Part-3:使用同步假设的共识算法
Part-4:非确定性共识算法
原文链接: https://medium.com/s/story/lets-take-a-crack-at-understanding-distributed-consensus-dad23d0dc95
作者: Preethi Kasireddy
















 675
675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











