







Label Propagation(简称LPA)
算法的优点
是一个简单容易理解的算法,主要用于community detection,它不用我们预先给定community的数量,可以控制迭代的次数去将图中节点去分类。
LPA的另一个极大的优点在于scalability,非常适合用来处理large graph,因为算法的实质是 vertex-centric model,所以其实是可以在Map-Reduce上实现它。
算法的大致思想描述如下:
1. 构造图graph。为graph中的每个顶点,分配一个唯一的label。一般可以考虑用node的id当成它的label id;
2. 开始计算每个node新的label。规则是,统计node周围所有邻居的label,出现次数最多的label将被设置成这个node的新label;
3. 如果邻居中出现次数最多的label有多个,那么随机的选择其中的一个label (例如在起始计算中,因为每个node的label都是唯一的,所以每个node周围所有的label出现次数都是1,这时候相当于随机的选择一个邻居的label作为自己的label);
4. 计算所有node之后,判断是否达到了终止条件,如果没有,回到第2步继续计算;
5. 经过几次迭代,到达终止条件,算法完成。现在图中,具有相同label的node属于同一个community。
算法终止条件:它要求所有的node都满足:
node的label一定是它的邻居label中出现次数最多的(或最多的之一),这意味着,每个node的邻居中,和它处于同一个community的数量一定大于等于处于其它community的数量。
以上是LPA算法的原理
spark的graphx实现版本如下:
本人也实现一个版本,但是相对与这个版本来说实在惭愧,所以打算用好的例子去分析。
这个算法可能会出现在下个版本的GraphX的Lib中。
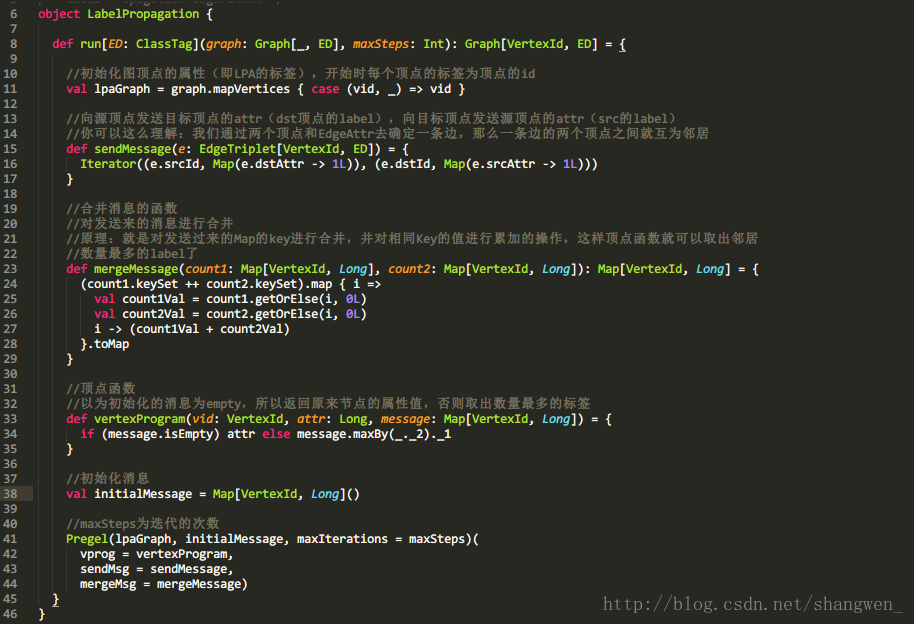
代码相对于GN来说还是比较简洁的,原理我在注释写了,需要注意的是由于该实现的算法没有控制发送消息的条件,是要控制迭代的次数的,如果迭代的次数过多,就容易所有都打上一样的标签,这个还是要自己按要求去控制吧。
最后,由于算法原理不是我看论文翻译出来的,所以标记个算法原理的出处:
http://greatpowerlaw.wordpress.com/2013/02/08/community-detection-lpa/















 9695
9695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









