







keepalived详解 及 keepalived配置LVS高可用负载均衡集群
在前面《INUX集群--均衡负载 LVS(一) LVS认知》等系列文章中我们全面认识了LVS,并手动进行了LVS的应用配置,我们知道所有用户client端的请求都会经过LVS的负载调度器director处理再转发给后端服务器realserver,这样director在请求并发量大的时候会产生压力,甚至有宕机的可能,所以我们必须为director提供高可用功能。下面将会认识keepalived, 并进行keepalived配置LVS高可用集群的实现。
1、认识keepalived
keepalived的诞生最初是为LVS ipvs(director)提供高可用性的,后来发展一个多功能、通用的轻量级高可用组件,可以为ipvs、nginx、haproxy等诸多服务提供高可用功能,主要应用在负载均衡调度器上,同时也可以检查后端各realserver的健康状态。
1-1、keepalived设计组成
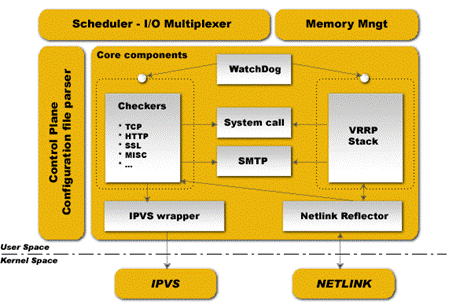
如上图,keepalived主要是模块是VRRP Stack和Cheackers,VRRP主要实现VIP(及MAC)的高可用,下面再详细认识其实现;Cheackers主要实现各服务如ipvs、nginx等的高可用及realserver健康状态检查,其中ipvs和realserver健康状态检查通过配置文件配置就可以实现,而其他服务高可用则需要通过自己编写脚本,然后配置keepalived调用来实现。
Keepalived运行有3个守护进程。父进程主要负责读取配置文件初始化、监控2个子进程等;然后两个子进程,一个负责VRRP,另一个负责Cheackers健康检查。其中父进程监控模块为WacthDog,工作实现:每个子进程打开一个接受unix域套接字,父进程连接到那些unix域套接字并向子进程发送周期性(5s)hello包。
1-2、认识VRRP
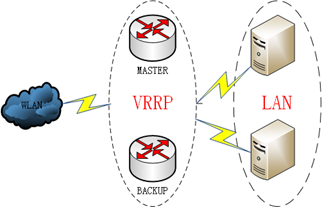
VRRP(Virtual Router Redundancy Protocol,虚拟路由冗余协议)可以认为是实现路由器高可用的协议,简单的说,当一个路由器故障时可以由另一个备份路由器继续提供相同的服务。
即将N台提供相同功能的路由器组成一个路由器组,这个组里面有一个master和多个backup,master上面有一个对外提供服务的网关ip和虚拟mac;master会发送224.0.0.18地址组播报文,当backup收不到vrrp包时就认为master宕掉了,这时就需要根据VRRP的优先级来选举一个backup作为master对外提供服务。这样的话就可以保证路由器的高可用,对于该路由器组所在局域网内其他主机来说还是相当于一台路由器,它们就可设置静态缺省路由网关为该路由器组ip了。
虚拟mac是虚拟路由器根据虚拟路由器ID生成MA地址,格式为:00-00-5E-00-01-{VRID},当虚拟路由器回应ARP请求时,使用虚拟MAC地址,而不是接口的真实MAC地址。
1-2-1、为什么是VRRP
对于局域网中的主机,有多种方法可以实现使其知道它的第一跳路由器地址,其中包括:1、运行某种动态路由协议,比如运行RIP或者OSPF; 2、配置静态缺省路由,即配置网关。
采用动态路由协议,由于管理开销、处理开销、安全原因以及在某些平台上不支持等原因而不现实;在实际应用中, 使用配置静态缺省路由, 即在主机配置网关的方法相当普遍, 这种方法具有最小化的配置和运行开销,并且被所有基于IP的应用所支持。但是,这种方法也有缺点, 即增加了单点故障的可能性。 缺省路由器的不可用将带来灾难性的结果: 当缺省路由器失效时, 所有相连的端主机将由于不能检测到可以替换的其他可用路径而造成网络中断。
综合以上两种方法存在的问题,设计产生了虚拟路由器冗余协议(VRRP),采用了静态缺省路由的方法,并且很好的避免了单点故障。协议定义的选举过程提供了一个当负责转发的主路由器失效时,备份路由器可以接替负责转发的动态容错机制。VRRP协议的这一优点使得每一个端主机不用配置任何动态路由协议或者路由发现协议,就可以获得更高的可靠性。
1-2-2、VRRP工作机制
VRRP根据优先级来确定虚拟路由器中每台路由器的角色(Master路由器或Backup路由器)。VRRP优先级的取值范围为0到255(数值越大表明优先级越高),可配置的范围是1到254,优先级0为系统保留给路由器放弃Master位置时候使用,255则是系统保留给IP地址拥有者使用。优先级越高,则越有可能成为Master路由器。当两台优先级相同的路由器同时竞争Master时,比较接口IP地址大小。接口地址大者当选为Master。
1、初始创建的路由器工作在Initialize状态:
通过VRRP报文的交互获知虚拟路由器中其他成员的优先级(keepalived是通过配置文件配置优先级,所以配置定义为MASTER的主机优化级较高),其中优先级最高的成为Master路由器,其他成为Backup路由器;
2、当路由器处于Master状态时,它将会做下列工作:
定期发送VRRP报文。
以虚拟MAC地址响应对虚拟IP地址的ARP请求。
转发目的MAC地址为虚拟MAC地址的IP报文。
如果它是这个虚拟IP地址的拥有者,则接收目的IP地址为这个虚拟IP地址的IP报文。否则,丢弃这个IP报文。
如果收到比自己优先级大的报文则转为Backup状态。
如果收到优先级和自己相同的报文,并且发送端的主IP地址比自己的主IP地址大,则转为Backup状态。
当接收到接口的Shutdown事件时,转为Initialize。
3、当路由器处于Backup状态时,它将会做下列工作:
接收Master发送的VRRP报文,判断Master的状态是否正常。
对虚拟IP地址的ARP请求,不做响应。
丢弃目的MAC地址为虚拟MAC地址的IP报文。
丢弃目的IP地址为虚拟IP地址的IP报文。
Backup状态下如果收到比自己优先级小的报文时,丢弃报文,不重置定时器;如果收到优先级和自己相同的报文,则重置定时器,不进一步比较IP地址。
当Backup接收到MASTER_DOWN_TIMER定时器超时的事件时,才会转为Master。
当接收到接口的Shutdown事件时,转为Initialize。
1-3、VRRP与keepalived
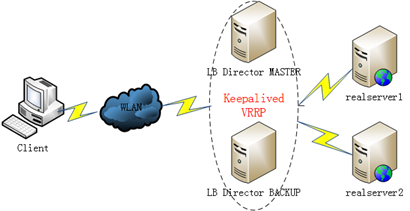
从上面keepalived设计组成可以看到,keepalived实现了VRRP协议,而VRRP实现路由器高可用,keepalived则用VRRP实现在集群中负载均衡调度器director的 VIP(和MAC)资源高可用,以及各keepalived主机的角色选举及其状态问题。
1-4、keepalived脑裂问题
Keepalived的BACKUP主机在收到不MASTER主机报文后就会切换成为master,如果是它们之间的通信线路出现问题,无法接收到彼此的组播通知,但是两个节点实际都处于正常工作状态,这时两个节点均为master强行绑定虚拟IP,导致不可预料的后果,这就是脑裂。
脑裂问题首先是检测,网上有以下几个方案:
1、添加更多的检测手段,比如冗余的心跳线(两块网卡做健康监测),ping对方等等。尽量减少"裂脑"发生机会。(指标不治本,只是提高了检测到的概率);
2、设置仲裁机制。两方都不可靠,那就依赖第三方。比如启用共享磁盘锁,ping网关等。(针对不同的手段还需具体分析);
3、算法保证,比如采用投票机制(keepalived没有实现);
ping网关比较容易实现,主要借助keepalived提供的vrrp_script及track_script实现:在vrrp_script定义一个跟踪脚本,在脚本定义的检测规则是,无法ping通网关则停止keepalived服务,但这还不能完全解决脑裂问题,因为它们报文通信出现问题,但都可以ping的情况还是有的。
总的来说,keepalived是面向网络的,只是确保共享的IP地址将存在于至少一个节点,不能确保像heartbeart、corosyn/pacemaker那样有比较完善的机制,可以保证资源的运行在一台集群节点上,使资源不会被并发访问。
1-5、keepalived双主模型
Keepalived一般的工作模型是一主一备(多备),而双主甚至多主也是可以的,这个双主是指两个VIP分别对应两个VRRP实例(也就是两个主备同时运行),如果两个VIP对应同一个服务,可以在前面再加DNS轮循,对就两条DNS的A记录,这样可以做到scale out 横向扩展,并且充分利用资源。
1-6、keepalived配置文件
keepalived只有一个配置文件keepalived.conf,安装后可以通过"man keepalived.conf"来查看说明,里面主要包括以下几个配置区域,分别是global_defs、vrrp_script、vrrp_rsync_group、vrrp_instance 、virtual_server和 real_server等:
1、global_defs区域为全局配置,主要配置realserver发生故障时的通知对象和组播地址等;
2、vrrp_script是用来配置本机服务(如nginx)健康状态检查脚本的,当检查的服务发生故障时,可以配置降低优先级,配置调用则在vrrp_instance中的track_script段;
3、vrrp_instance用来定义一个VRRP实例,多主模型可以定义多个VRRP实例;其中virtual_ipaddress区域配置对外提供服务的VIP,而本机故障通知则需要在vrrp_instance区域的notify_fault配置脚本中实现,如果vrrp_script检查服务引起的MASTER切换为BACKUP,则在notify_backup脚本定义通知,同时可以在脚本重启或停止该服务(注意,如果重启服务正常,优先级会相应增加,在抢占模式下,会重新变为MASTER);
4、virtual_server区域则主要配置VIP和ipvs规则的,virtual_server中的real_server区域配置realserver康健状态检查的;
5、vrrp_rsync_group用来定义vrrp_intance组,两个vrrp_instance同属于一个vrrp_rsync_group,那么其中一个vrrp_instance发生故障切换时,另一个vrrp_instance也会跟着切换(即使这个instance没有发生故障);这在LVS NAT中VIP、DIP各一个实例用到。
后面具体配置再详细分析,它们在文件中的位置如下:
- global_defs {
- }
- vrrp_script chk_nginx{
- }
- vrrp_instance VI_1 {
- virtual_ipaddress {
- 192.168.18.240/24 dev eth0 label eth0:0
- }
- track_script {
- chk_nginx
- }
- notify_master "/etc/keepalived/notify.sh master"
- notify_backup "/etc/keepalived/notify.sh backup"
- notify_fault "/etc/keepalived/notify.sh fault"
- }
- virtual_server 192.168.18.240 80 {
- real_server 192.168.18.251 80 {
- }
- real_server 192.168.18.252 80 {
- }
- }
2、配置前准备
2-1、具体使用环境资源
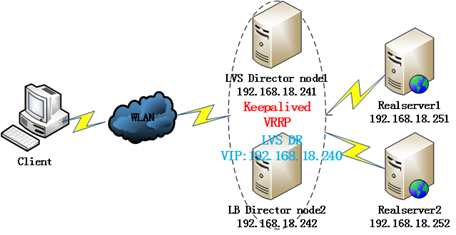
1、各主机系统:CentOS 6.4 x86_64
2、使用LVS DR模型,两台Diretocr:
Node1: IP:192.168.18.241 host name:node1.tjiyu,com;
Node2: IP:192.168.18.242 host name:node2.tjiyu.com;
VIP:192.168.18.240
3、两台realserver:
realserver1: IP:192.168.18.251 host name:realserver1.tjiyu,com;
realserver2: IP:192.168.18.252 host name:realserver2.tjiyu.com;
service:httpd
2-2、配置前所需要的准备
各主机需要做以下准备:
1、配置IP、关闭防火墙/SELINUX;
2、时间同步;
3、配置节点名称和SSH互信(这两点不是必须的,最好配置上,方便操作)
在前面《heartbeat v2 haresource 配置可用集群》说到的高可用集群已有详细介绍,这里就不再给出了。
3、下载安装
CentOS6.4及后版本官方都提供了keepalived的rpm包,如果是低版本可以自己编译,也可以到rpm.pbone.net搜索下载;我们这里是CentOS6.4配置好yum源,分别在两台director节点上都安装keepalived和ipvsadm,我们知道ipvs模块整合在内核,ipvsadm只是用户空间的一个管理工具,keepalived也没有用到ipvsadm,这里只是用它来查看测试而已,如下:
- [root@node1 ~]# yum install -y keepalived ipvsadm

在所有主机上都安装httpd,两台realserver提供httpd服务测试,两台director用httpd提供failover页面,如下:
- [root@node1 ~]# yum install -y httpd
4、配置realserver
4-1、配置httpd测试
在两台realserver上分别提供一个测试页面,然后启动httpd,用浏览器访问下看是否正常,如下:
- [root@realserver1 ~]# echo "realserver1" >> /var/www/html/index.html
- [root@realserver1 ~]# service httpd start
- [root@realserver1 ~]# chkconfig httpd on

4-2、配置LVS DR相关
我们这里使用LVS DR模型,从前面《LINUX集群--均衡负载 LVS(二) NAT和DR的应用配置》文章知道,需要对realserver进行一些配置,这里把相关配置写成脚本,分别在两台realserver上执行,然后查看是否正确配置了,注意脚本需要修改所使用的VIP,脚本如下:
- #!/bin/bash
- #
- # Script to start LVS DR real server.
- # description: LVS DR real server
- #
- . /etc/rc.d/init.d/functions
- VIP=192.168.18.240 #修改为VIP
- host=`/bin/hostname`
- case "$1" in
- start)
- # Start LVS-DR real server on this machine.
- /sbin/ifconfig lo down
- /sbin/ifconfig lo up
- echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore
- echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce
- echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
- echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
- /sbin/ifconfig lo:0 $VIP broadcast $VIP netmask 255.255.255.255 up
- /sbin/route add -host $VIP dev lo:0
- ;;
- stop)
- # Stop LVS-DR real server loopback device(s).
- /sbin/ifconfig lo:0 down
- echo 0 > /proc/sys/net/ipv4/conf/lo/arp_ignore
- echo 0 > /proc/sys/net/ipv4/conf/lo/arp_announce
- echo 0 > /proc/sys/net/ipv4/conf/all/arp_ignore
- echo 0 > /proc/sys/net/ipv4/conf/all/arp_announce
- ;;
- status)
- # Status of LVS-DR real server.
- islothere=`/sbin/ifconfig lo:0 | grep $VIP`
- isrothere=`netstat -rn | grep "lo:0" | grep $VIP`
- if [ ! "$islothere" -o ! "isrothere" ];then
- # Either the route or the lo:0 device
- # not found.
- echo "LVS-DR real server Stopped."
- else
- echo "LVS-DR real server Running."
- fi
- ;;
- *)
- # Invalid entry.
- echo "$0: Usage: $0 {start|status|stop}"
- exit 1
- ;;
- esac
- exit 0
Node1执行如下:
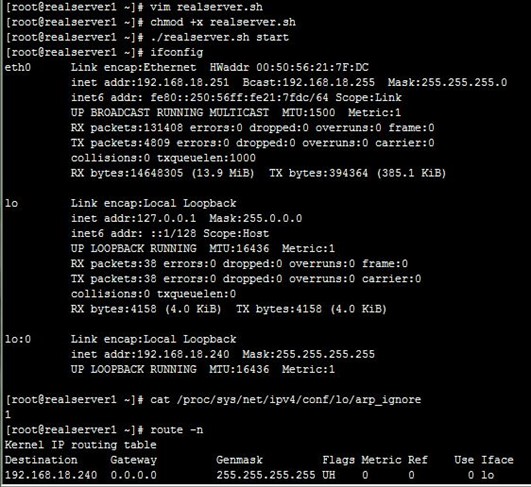
- [root@realserver1 ~]# vim realserver.sh
- [root@realserver1 ~]# chmod +x realserver.sh
- [root@realserver1 ~]# ./realserver.sh start
- [root@realserver1 ~]# ifconfig
- [root@realserver1 ~]# cat /proc/sys/net/ipv4/conf/lo/arp_ignore
- [root@realserver1 ~]# cat /proc/sys/net/ipv4/conf/lo/arp_announce
- [root@realserver1 ~]# cat /proc/sys/net/ipv4/conf/all/arp_ignore
- [root@realserver1 ~]# cat /proc/sys/net/ipv4/conf/all/arp_ignore
- [root@realserver1 ~]# route –n
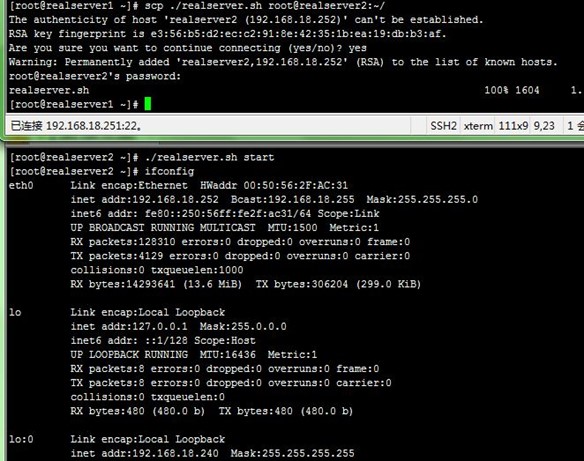
5、director配置功能说明
通过/etc/keepalived/keepalived.conf配置文件和自定义脚本来实现我们的需求,下面先来说明几点实现的功能,后面再给出配置过程和配置文件。
5-1、配置初始启动后node1成为主节点,node2成功备节点
这是通过两个节点上的配置文件配置state和priorty两个配置项差别来实现,这也是两个节点配置文件中仅有的两处差别,所以在node1上配置好后,直接远程复制到node2,再修改这两个地方,如下(左边是node1):

5-2、配置ipvs规则及其高可用,配置后端realserver健康状态检查
这两个功能是keepalived的基本功能,直接通过配置选项就可以实现,无需自定义其他脚本命令,注意,global_defs 段配置的邮件通知是realserver状态发生改变时的通知。
5-3、所有realserver都宕机,定义在director提供维护页面
这个主要通过配置文件中的sorry_server配置项实现,当然两个director节点主机自身要配置对外提供WEB页面服务。
5-4、实现模拟主备切换
一般来说主备切换发生在master上keepalived监测的服务(如nginx)或keepalive服务本身发生故障时,监测服务需要先定义服务状态跟踪脚本/命令,脚本中可以检查高可用服务的状态,返回状态码0表示服务正常,配置调用则在vrrp_instance中的track_script段;但我们这里没有监测其他服务,所以模拟一个,定义配置如下:
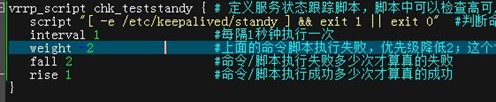
这里的模拟heartbeat的standy,意思是如果在配置文件的目录下有standy这个文件,会在vrrp实例定义的优先级减去下面的weight值,就表示期望这个节点为备用状态。
5-5、主备切换及故障时的状态处理和通知
配置文件中vrrp_instance段有三个配置项:notify_master、notify_backup和notify_fault,分别可以配置转换为master、backup和故障状态时使用的脚本通知,可以自定义脚本命令,来处理这些状态变化。
比如说,如果vrrp_script检查服务引起的MASTER切换为BACKUP,则在notify_backup脚本定义通知,同时可以在脚本重启或停止该服务(注意,如果重启服务正常,优先级会相应增加,在抢占模式下,会重新变为MASTER);
我们这里用一个通用脚本来处理状态变化时发送邮件通知,如下:

6、配置director
上面说明了几点实现的功能,下面再给出配置过程和配置文件。
6-1、配置对外提供维护页面
先分别在node1、node2主机自身配置对外提供WEB页面服务,并用浏览器访问测试,如下:
- [root@node2 ~]# echo "In maintenance, please come back later" >> /var/www/html/index.html
- [root@node2 ~]# chkconfig httpd on
- [root@node2 ~]# service httpd start

6-2、配置keepalived.conf文件
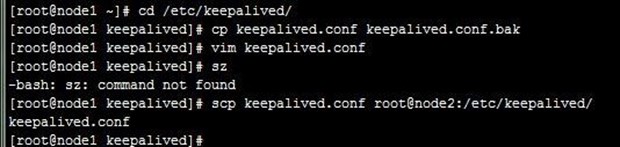
接着在node1上配置keepalived.conf文件,然后远程复制到node1,再到node2修改配置文件中的两个差别配置,注意,配置的发件人用户得是系统用户,不存在发不出邮件,得先在两节点上添加用户,过程如下:
- [root@node1 ~]# cd /etc/keepalived/
- [root@node1 keepalived]# cp keepalived.conf keepalived.conf.bak
- [root@node1 keepalived]# vim keepalived.conf
- [root@node1 keepalived]# scp keepalived.conf root@node2:/etc/keepalived/
- [root@node1 keepalived]# useradd root_keepalived
6-3、配置keepalived状态变化通知脚本
接着在node1自定义notify_master、notify_backup和notify_fault状态变化脚本notify.sh,然后远程复制到node2,如下:
- [root@node1 keepalived]# vim notify.sh
- [root@node1 keepalived]# chmod +x notify.sh
- [root@node1 keepalived]# ll
- [root@node1 keepalived]# scp –p notify.sh root@node2:/etc/keepalived/
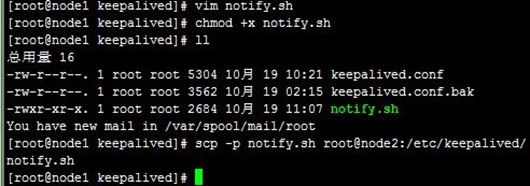
下面是实现上面功能的配置文件,上面说过node2上仅有两处差别,所以只给node1配置文件,如下:
- ! Configuration File for keepalived
- global_defs { #全局配置,这里额外的静态路由并未添加因为它是非必要的,除非我们在当前或特定的主机上生成特殊的静态路由等
- notification_email { #realserver故障时通知邮件的收件人地址,可以多个
- root@localhost
- }
- notification_email_from root_keepalived #发件人信息(可以随意伪装,因为邮件系统不会验证处理发件人信息)
- smtp_server 127.0.0.1 #发邮件的服务器(一定不可为外部地址)
- smtp_connect_timeout 30 #连接超时时间
- router_id LVS_DEVEL #路由器的标识(可以随便改动)
- }
- vrrp_script chk_teststandy { # 定义服务状态跟踪脚本,脚本中可以检查高可用服务的状态,返回状态码0表示服务正常;配置调用则在vrrp_instance中的track_script段;这里chk_teststandy是定义脚本的名称,可随意取
- script "[ -e /etc/keepalived/standy ] && exit 1 || exit 0" #判断命令/自己定义好的脚本路径;#这里的模拟heartbeatstandy,意思是如果在这个文件下有standy这个文件,会在vrrp实例定义的优先级减去下面的weight值,就表示期望这个节点为备用状态。
- interval 1 #每隔1秒钟执行一次
- weight -2 #上面的命令脚本执行失败,优先级降低2;这个值的绝对值必须大于MASTER减BACKUP定义的优先级
- fall 2 #命令/脚本执行失败多少次才算真的失败
- rise 1 #命令/脚本执行成功多少次才算真的成功
- }
- vrrp_instance VI_1 { #配置虚拟路由器的实例,VI_1是自定义的实例名称state MASTER #初始状态,MASTER|BACKUP,当state指定的instance的初始化状态,在两台服务器都启动以后,马上发生竞选,优先级高的成为MASTER,所以这里的MASTER并不是表示此台服务器一直是MASTER
- interface eth0 #通告选举所用端口
- virtual_router_id 51 #虚拟路由的ID号(一般不可大于255)
- priority 101 #优先级信息 #备节点必须更低
- advert_int 1 #VRRP通告间隔,秒
- authentication {
- auth_type PASS #认证机制
- auth_pass 5344 #密码(尽量使用随机)
- }
- virtual_ipaddress { #虚拟地址(VIP地址)
- 192.168.18.240
- }
- track_script { #调用上面定义的服务状态跟踪脚本
- chk_teststandy
- }
- #nopreempt #设置不抢占,这里只能设置在state为BACKUP的节点上,而且这个节点的优先级必须别另外的高
- #preempt delay 300 #抢占延迟,和nopreempt一样只能用在BACKUP上,但不能和nopreempt同时使用
- notify_master "/etc/keepalived/notify.sh -n master -a 192.168.18.240" #转换为master状态时使用此脚本通知
- notify_backup "/etc/keepalived/notify.sh -n backup -a 192.168.18.240" #转换为backup状态时使用此脚本通知
- notify_fault "/etc/keepalived/notify.sh -n fault -a 192.168.18.240" #转换为fault状态时使用此脚本通知,如果脚本带有参数也就是有空格必须使用引号
- }
- virtual_server 192.168.18.240 80 { #设置一个virtual server: VIP:Vport
- delay_loop 6 # service polling的delay时间,即服务轮询的时间间隔
- lb_algo rr #LVS调度算法:rr|wrr|lc|wlc|lblc|sh|dh
- lb_kind DR #LVS集群模式:NAT|DR|TUN
- #persistence_timeout 120 #会话保持时间(持久连接,秒),即以用户在120秒内被分配到同一个后端realserver
- nat_mask 255.255.255.0
- protocol TCP #健康检查用的是TCP还是UDP
- real_server 192.168.18.251 80 { #后端真实节点主机的权重等设置,主要,后端有几台这里就要设置几个
- weight 1 #给每台的权重,rr无效
- #inhibit_on_failure #表示在节点失败后,把他权重设置成0,而不是冲IPVS中删除
- #notify_up <STRING> | <QUOTED-STRING> #检查服务器正常(UP)后,要执行的脚本
- #notify_down <STRING> | <QUOTED-STRING> #检查服务器失败(down)后,要执行的脚本
- HTTP_GET { #健康检查方式,一共HTTP_GET|SSL_GET|TCP_CHECK|SMTP_CHECK|MISC_CHECK:HTTP_GET检查url,SSL_GET检查https url,TCP_CHECK检查tcp连接,可用在mysql检查
- url { #要检查的URL,可以有多个
- path / #具体路径
- status_code 200 #返回成功状态码,也可以用另外一个选项配置返回字符串
- }
- connect_timeout 2 #连接超时时间
- nb_get_retry 3 #重连次数
- delay_before_retry 1 #重连间隔
- }
- }
- real_server 192.168.18.252 80 { #第二台realserver
- weight 1
- HTTP_GET {
- url {
- path /
- status_code 200
- }
- connect_timeout 2
- nb_get_retry 3
- delay_before_retry 1
- }
- }
- sorry_server 127.0.0.1 80 #所有realserver都down机,定义在本机提供维护页面
- }
下面是该notify.sh脚本的实现,如下:
- #!/bin/bash
- # description: An example of notify script
- # Usage: notify.sh -m|--mode {mm|mb} -s|--service SERVICE1,... -a|--address VIP -n|--notify {master|backup|falut} -h|--help
- contact='root@localhost'
- helpflag=0
- serviceflag=0
- modeflag=0
- addressflag=0
- notifyflag=0
- Usage() {
- echo "Usage: notify.sh [-m|--mode {mm|mb}] [-s|--service SERVICE1,...] <-a|--address VIP> <-n|--notify {master|backup|falut}>"
- echo "Usage: notify.sh -h|--help"
- }
- ParseOptions() {
- local I=1;
- if [ $# -gt 0 ]; then
- while [ $I -le $# ]; do
- case $1 in
- -s|--service)
- [ $# -lt 2 ] && return 3
- serviceflag=1
- services=(`echo $2|awk -F"," '{for(i=1;i<=NF;i++) print $i}'`)
- shift 2 ;;
- -h|--help)
- helpflag=1
- return 0
- shift
- ;;
- -a|--address)
- [ $# -lt 2 ] && return 3
- addressflag=1
- vip=$2
- shift 2
- ;;
- -m|--mode)
- [ $# -lt 2 ] && return 3
- mode=$2
- shift 2
- ;;
- -n|--notify)
- [ $# -lt 2 ] && return 3
- notifyflag=1
- notify=$2
- shift 2
- ;;
- *)
- echo "Wrong options..."
- Usage
- return 7
- ;;
- esac
- done
- return 0
- fi
- }
- #workspace=$(dirname $0)
- RestartService() {
- if [ ${#@} -gt 0 ]; then
- for I in $@; do
- if [ -x /etc/rc.d/init.d/$I ]; then
- /etc/rc.d/init.d/$I restart
- else
- echo "$I is not a valid service..."
- fi
- done
- fi
- }
- StopService() {
- if [ ${#@} -gt 0 ]; then
- for I in $@; do
- if [ -x /etc/rc.d/init.d/$I ]; then
- /etc/rc.d/init.d/$I stop
- else
- echo "$I is not a valid service..."
- fi
- done
- fi
- }
- Notify() {
- mailsubject="`hostname` to be $1: $vip floating"
- mailbody="`date '+%F %H:%M:%S'`, vrrp transition, `hostname` changed to be $1."
- echo $mailbody | mail -s "$mailsubject" $contact
- }
- # Main Function
- ParseOptions $@
- [ $? -ne 0 ] && Usage && exit 5
- [ $helpflag -eq 1 ] && Usage && exit 0
- if [ $addressflag -ne 1 -o $notifyflag -ne 1 ]; then
- Usage
- exit 2
- fi
- mode=${mode:-mb}
- case $notify in
- 'master')
- if [ $serviceflag -eq 1 ]; then
- RestartService ${services[*]}
- fi
- Notify master
- ;;
- 'backup')
- if [ $serviceflag -eq 1 ]; then
- if [ "$mode" == 'mb' ]; then
- StopService ${services[*]}
- else
- RestartService ${services[*]}
- fi
- fi
- Notify backup
- ;;
- 'fault')
- Notify fault
- ;;
- *)
- Usage
- exit 4
- ;;
- esac
- exit 0
7、测试
7-1、启动及测试ipvs
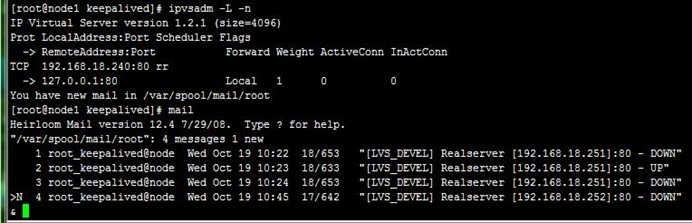
分别在两节点启动keepalived服务,然后查看ipvs规则配置及以node1上的VIP配置(ip addr show查看),接着通过浏览器访问,可以看到ipvs调度到了两台realserver上,如下:
- [root@node1 keepalived]# service keepalived start
- [root@node1 keepalived]# ipvsadm -L -n
- [root@node1 keepalived]# ip addr show
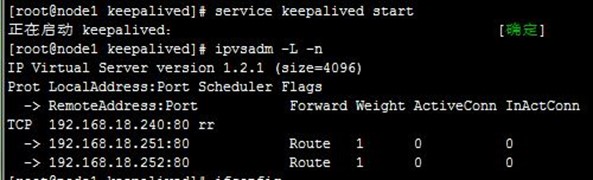
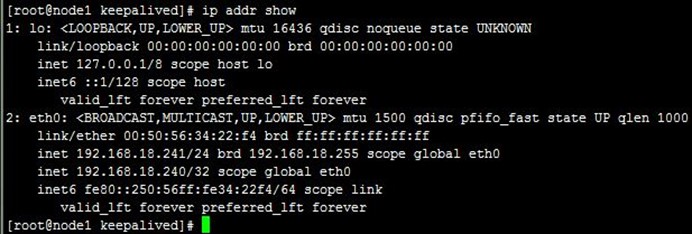
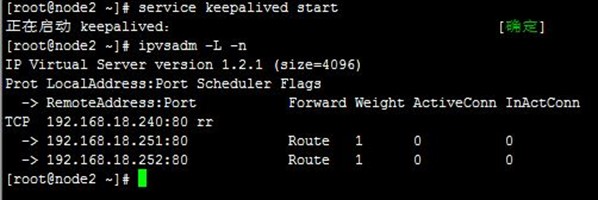
7-2、测试realserver健康状态检查
当有realserver的WEB状态变化时,keepalived会用邮件系统发送通知给global_defs段配置的收件人,但是测试的时候发现在收不到邮件,通过查看/var/log/messages,可以看到keepalived处理正常,而查看/var/log/maillog,发现由于配置qq邮箱,邮件被qq邮箱服务器拒绝了,如下:
- [root@node1 keepalived]# tail /var/log/messages
- [root@node1 keepalived]# tail /var/log/maillog
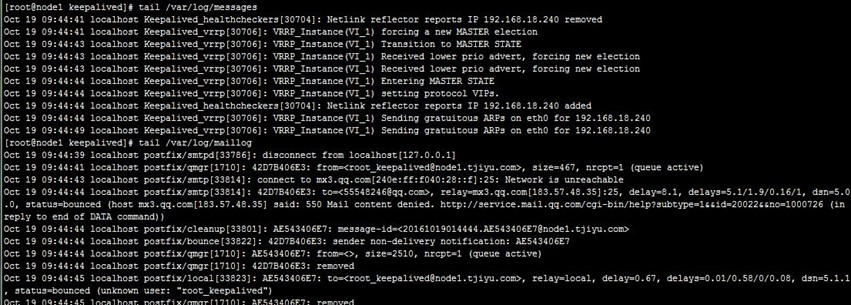
我们直接用本机邮件系统接收好了,分别在两节点修改keepalived.conf和notify.sh中的收件人地址,然后我们再停止realserver1上的httpd服务,可以看到两节点上都发生了相应的ipvs规则改变,以及收到了realserver1 down的邮件,如下:
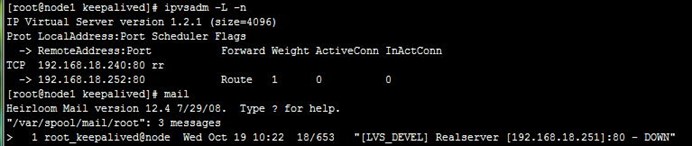
然后我们又进行了realserver1 的httpd上线、下线以及realservier2下线操作,都能正常反应,如下:
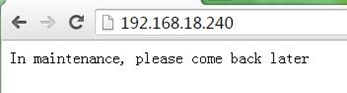
7-3、测试director提供的维护页面
上一步,我们把两台realserver的httpd服务都停止,现在再访问VIP,可以看到访问到director提供的维护页面,如下:
7-4、测试主备切换及其邮件通知
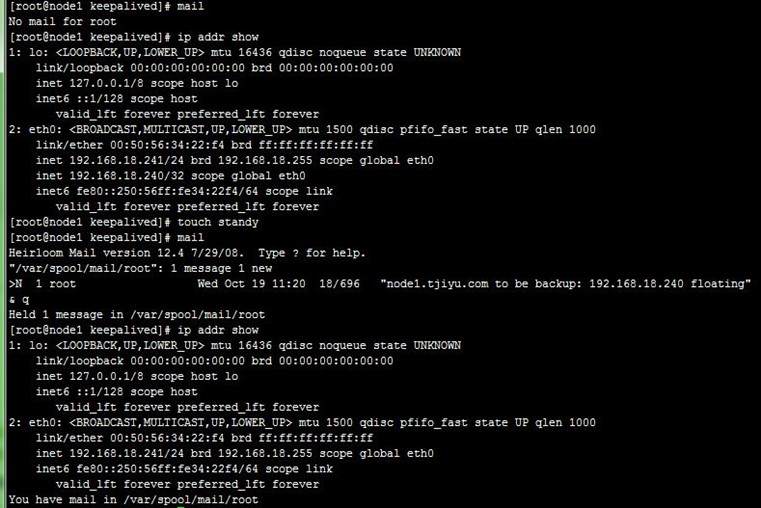
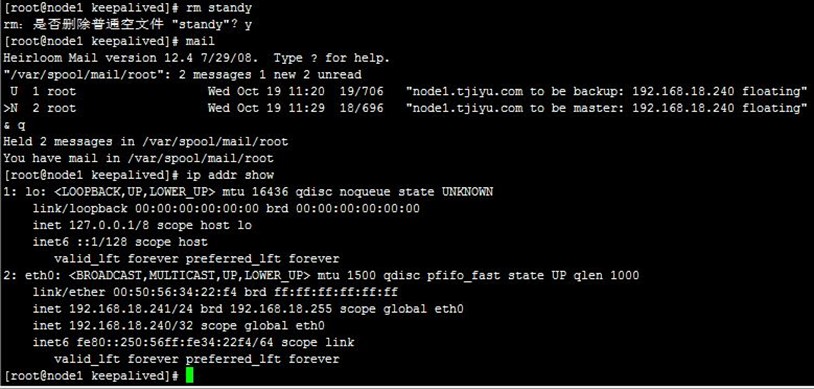
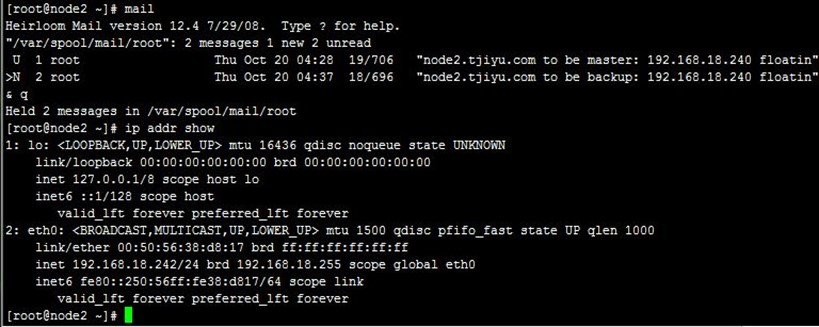
我们先把两台realserver上线,再把前面的邮件删除,然后在MASTER状态的node1上的/etc/keepalived目录创建standy文件,可以看到两节点都收到了通知邮件,并且VIP转移到node2上,即node1变为了备节点,node2变为了主节点,过程如下,
- [root@node1 keepalived]# ip addr show
- [root@node1 keepalived]# touch standy
- [root@node1 keepalived]# mail
- [root@node1 keepalived]# ip addr show
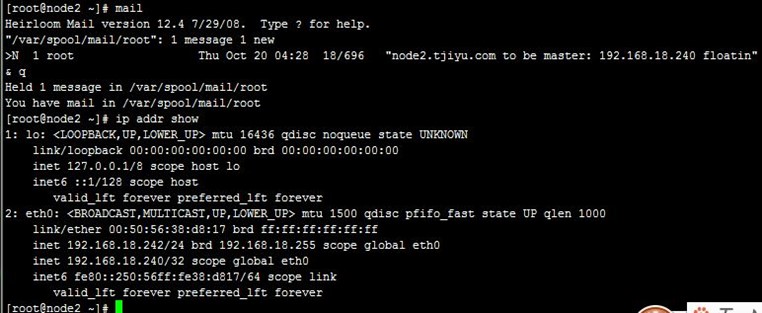
然后再删除node1上刚才创建的standy文件,可以看到VIP回转到node1上,即node2变为了备节点,node1变为了主节点,如果没需要回转,可以设置非抢占模式,具体就不说了;
7-5、测试keepalived故障转移及其邮件通知
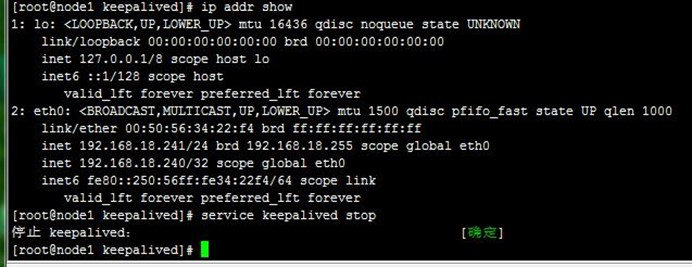
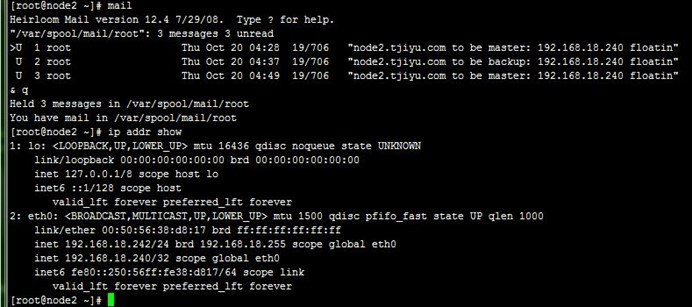
和上一步差不多的,这里直接停止MASTER状态node1的keepalived服务,可以看到node2成为了主节点,从浏览器也能正常访问VIP到realserver,如下:
到这里,keepalived + LVS高可用集群就可以正常运行了,关于前面说的脑裂问题没有解决,待后面解决,后面将在本文件的基础上进行keepalived + nginx高可用集群配置……
【参考资料】
1、keepalived官网文档:http://www.keepalived.org/documentation.html
2、VRRP协议详解:http://wenku.baidu.com/view/6007151f10a6f524ccbf85f1.html
3、LINUX集群--均衡负载 LVS(一) LVS认知:http://blog.csdn.net/tjiyu/article/details/52489343
4、keepalived工作原理和配置说明:http://outofmemory.cn/wiki/keepalived-configuration
5、Linux 高可用(HA)集群之keepalived详解:http://freeloda.blog.51cto.com/2033581/1280962
6、使用keepalived来实现MySQL的failover:https://my.oschina.net/tz8101/blog/653229














 134
134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









