







# 1 概述 ## 1.1 强化学习 v.s. 监督学习 强化学习,与监督学习、无监督学习并列,作为机器学习的三大类。强化学习,研究的是 agent 从与 environment 交互过程进行学习,学习如何作用于 environment,从而可以从 environment 得到最优的激励。这个过程可以描述如下:  即,agent 从 environment 处观察到 state,从而基于某种 policy 做出 action,environment 继而对这种 action 做出反馈 reward 并转移到新的 state,agent 面对新的 state 和之前 policy 得到的 reward,再次给出 action,周而复始,目标就是 reward 某种长期指标最大化。
可见,强化学习的理论框架和监督学习有一定相似性,学习改进的过程,都有一种评价指标,监督学习中是 label,强化学习中是 reward,用来指引 model 的学习,也都有训练样本。 但区别也是巨大的,基本可以概括为:
- SL 中样本 x 通常要求 IID,而 RL 中显然序列交互过程产生的样本 (s,a) 不满足 IID
- SL 中 label 是随 x 一起准备好的,而 RL 中的“标签” reward 的产生是滞后于(s,a)的。这就使得 RL 的学习必然是一个序列多步决策问题,同时 action 会影响下一步的 state 和 reward,从而表明目标应是长期激励,这都显著区别于 SL。此外,这个 reward 不像 label 一样能直接指导选择什么样的 action。
- SL 中样本的产生和训练是个open-loop,准备好样本,完成训练。RL 中样本的产生和训练是个 closed-loop,样本产生,用于训练,应用模型,得到新的样本,继续训练。这就使得 RL 的训练对样本准备要求低了很多。
1.2 强化学习 v.s. 深度学习
前面提到 SL 的缺陷:
- 样本服从 IID,而很多问题要处理的序列交互过程并不满足 IID 假设
- 强监督需要的标注样本,是昂贵而稀缺的
RL 恰恰能处理这些缺陷,但也要考虑到 DL 强大的表征能力,因此,DRL 的提出即融合 RL 和 DL 的优势:
- DL learns the representation
- RL learns the model
1.3 强化学习
RL 本身也有一些监督学习、无监督学习所没有的特点:
- exploration-exploitation dilemma,为获得长期激励,要选用已知的好的 action,还要尝试未知的也许更好的 action,这种博弈在其他 ML 方法中未涉及
- 直接尝试解决目标明确的 agent 与未知的 environment 交互的这个“大”问题,而不是分解为多个子问题
一个 RL 系统可以由四个基本元素描述:a policy, a reward signal, a value function, and, optionally, a model of the environment。
RL 研究的是序列多步决策问题,通常形式建模为 MDP(当然早期也有 multi-bandit)。但凡适合解决 MDP 的算法,都可以称为 RL 算法。了解 Finite MDP 的理论,可以理解现代 RL 的90%。下面主要介绍 MDP 模型,及其几类求解方法。
2 MDP
2.1 Formulation
markov 模型家族有不少熟知角色,可以概括如下:

MDP 建立在 markov chain 之上,自然 state transition 仅与上一个 state(可包含 action)有关。
MDP 模型形式化为五元组(T,S,A,P,R),即 epoch,state,action,transition probability, reward。当然,有些教材会把 T 省略,但考虑到 MDP 建模的序列多步决策,而且 T 的不同选择对 S 的定义也有影响,所以习惯上,这里加上 T。
此外,还有基于五元组,衍生的几个概念:
(1)Policy,π,建模了 agent 的 behavior,可分为两类
- stochastic policy,π:p(a|s) = π(s,a)
- deterministic policy,π:a = π(s)
(2) Return,g,一个 reward 序列的函数,用来衡量从当前到未来的长期激励。

这里有些概念需进一步阐述:
(1)state 信号通常由预处理系统给出,其构建、学习不在 MDP 算法讨论范围内。其次,不能期望 state 告知 agent 关于 environment 的一切信息,甚至可以做出 action-decision 的一切信息。
(2)environment 的 Markov 性,即 state 的 Markov 性,表示联合概率分布
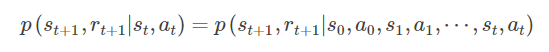
(3) 有些材料如 [2] 认为 rt+1和 st、at 有关,亦可和 st+1有关,但不可和 at+1at+1 有关,一些其他材料也持这种观点。但 [1] 建模 rt+1 仅与 st、at 有关,通常交互序列为 s0,a0,r1,s1,a1,r2,⋯,rt,st,at这种描述方式更简单。下面不刻意区分 r(s,a,s′)与r(s,a)。
(4)policy 是由每个 epoch 上的 decision rule 组成,每个 decision rule 决定了该 epoch 时 ss 到 aa 的映射。decision rule 的 stochastic 还是 deterministic 决定了 policy 的性质。当所有 epoch 上都选用同一个 decision rule 时也称 policy 为 stationary 的,即通常接触的 MDP (infinite horizon MDP)的研究对象。通常称 stationary deterministic policy 为 pure policy,属于最特殊的 policy 。
(5)定理表明,在追求期望 return 最大化情况下,最优的 policy 一定是 deterministic 的,因此不必考虑 stochastic policy。
(6)下面基本假设 S 和 A 是有限的,即 finite MDP,以避免积分表示。
2.2 Value function
为了期望 return 最大化,这里构造了值函数,用来评估(预测)在当前 state(以及 action)情况下遵循该 π,能获得的期望 return 是多少。即值函数中 policy 确定,J(π) 则以 policy π为变量。以折扣总回报形式的 return 为例,值函数形式化为:

显然两者存在简单的转化关系:
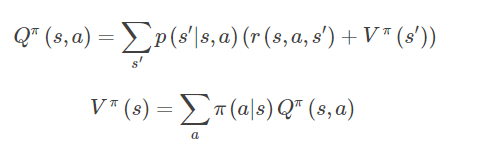
值函数可以利用 experiences 进行估计,也可以利用参数化的方式来进行参数估计。后面会具体介绍。
利用值函数内含的迭代关系,可以构造为下列形式,即 Bellman 方程组:

2.3 Optimal policy
值函数定义了各种 policy 的偏序,即 π≥π′当且仅当对于任意 state 有 Vπ(s)≥Vπ′(s)。因此,最优 policy 即对应让该 policy 的值函数最大的 policy。
利用上面 Bellman 方程组,很容易得到 optimal value func:
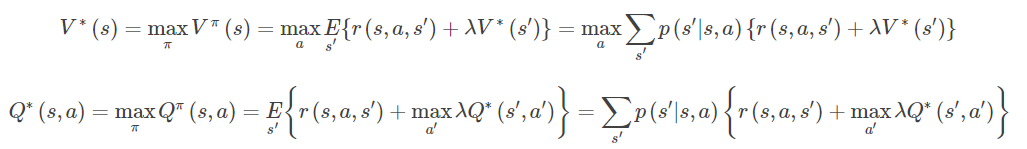
下面是一个比较直观的示意图

一旦有了最优值函数,就很简单确定 optimal policy 了,即对于任意 state,选使得值函数最大的 action 即可。任何关于最优值函数的贪心 policy 都算最优 policy。
貌似,只要显式解决了 Bellman Optimality Equation 就找到了 optimal policy。但这个方法仅仅是理论,基本行不通,除非至少满足以下假设:
- 能对 environment 精确建模
- 足够的巨大计算资源
- 满足 Markov 性
显然,实际中,这三个假设很难满足,通常不可能直接解上述 Bellman Optimality Equation 来得到 optimal policy,都是用一些近似方法来求解 Bellman Optimality Equation。
2.4 MDP 优化方法
利用 MDP 对问题建完模,求解 J(π)的最优化,直观思路是直接从 J(π)下手,将其看成普通的参数优化问题,利用 SGD 类方法求解;或者从上面引导出的 Bellman Optimality Equation 入手,不停迭代逼近最优值函数。根据这两种不同思路,可以将解决方法归类为三种:
- critic-only 类,学习 value func,不涉及参数化的 policy
- actor-only 类,学习参数化的 policy,不涉及 value func
- actor-critic 类,将 value func 与参数化 policy 结合
where ‘actor’ is a reference to the learned policy, and ‘critic’ refers to the learned value function, usually a state value function.
3 Critic-only 类方法
该类方法的思路基本都是,先想办法评估当前值函数,然后针对当前值函数遍历 action 得到当前最优 policy,然后继续估计采用该最优 policy 的值函数,循环往复。
该类方法还可以分为 model-based 类和 model-free 类:
- 前一种利用 model 的 P 和 R 来计算值函数,以 DP-based 类方法,RMax 方法为主
- 后一种处理现实中往往 P 和 R 未知的情况,并不对 model 进行建模学习,包括 MC-based 方法和 TD-based 方法
prediction v.s. control
Prediction or evaluation problem, is that of estimating the value function for a given policy π.
Control problem , is that of finding an optimal policy.
无论是否基于 model,critic-only 类方法都可以看作以下范式:先进行 Prediction,然后进行 Control。
主要区别在于处理 prediction problem 的方法。而 Control problem 都是采用 greedy-search 方法。
3.1 DP-based methods
该类方法属于 model-based 类,即已知 P 和 R 可以用来计算 value func,主要依靠 Bellman optimality equations。
policy iteration
第一种思路是,首先根据当前 policy,计算 value func 来对当前 policy 进行评估,然后基于这个 value func 来 greedy search 最好的 action 从而更新 policy,循环往复。总结为两步:

value iteration
第二种思路是,上面 policy evaluation 过程由于迭代计算值函数,每次都要扫描 S,迭代过程理论上趋于无穷才收敛,如果等到 policy evaluation 收敛才进行 policy improvement,显然是很耗时的。事实上,policy iteration 中的 policy evaluation 进行裁剪(减少迭代计算次数)并不会影响算法的收敛性,极端情况就是 policy evaluation 时仅进行一次迭代计算,就进行 policy improvement,这种方式称为 value iteration 算法:

generalized policy iteration
对比上面两种算法,可见 Policy iteration 多次迭代 Bellman equation 直到收敛,而 Value iteration 仅仅迭代一次 Bellman equation(实际上利用的 Bellman optimality equation 作为更新规则)区别主要在于 policy evaluation 和 policy improvement 两个环节的交织方式。
两者本质上的区别是数值分析中的 explicit method 和 implicit method 的区别,explicit 方法收敛慢、稳定性差,但 implicit method 要解方程。如果方程没有解析解,解这个方程本身又要用数值迭代方式。
介于两者之间的就是 generalized policy iteration,即多次迭代来进行 policy evaluation 然后 policy improvement。这种阐述方式基本是大多 RL 算法的范式。
有趣的是,policy evaluation 然后 policy improvement 两个环节可以看做既竞争又合作。竞争说的是,它们引导的方向相反。policy improvement 中的 greedy-search 会让 value func 偏离新的 policy,而 policy evaluation 中追求 value func 与 policy 一致会使得 policy 对于 value func 不再 greedy。但从长期来看,这两个环节会交错合作来找到那个唯一的联合解,即最优 policy 和最优 value func。
维度灾难
该类方法很大一个局限就是算法的复杂度,寻找到最优 policy 的复杂度是 O(|S||A|)O(|S||A|),看着只是 S 和 A 个数的线性关系,但通常我们谈论的算法复杂度不是用状态空间的中值的个数而是状态空间的维数,那么上面的复杂度实际应该是状态空间和动作空间的指数阶,这就是 Bellman 提出的维度灾难。
但 DP-based methods 要比穷搜和线性规划好上不少,在当前计算力下,解决拥有百万状态的 MDP,DP-based methods 也是没问题的。
3.2 RMax method
针对无模型情况,有两种思路,一种是想办法还原出 P 和 R 即还原出 MDP model,然后再在这个 model 上进行策略优化,这还是属于 model-based 思路;另一种是不还原直接优化,即 model-free 思路。
RMax 即属于前一种思路,MC-based 和 TD-based 属于后一种。
RMax 方法,利用随机游走,通过计数这个简单的回归模型来还原 MDP。但仅还原 MDP 的抽样复杂度就是 O(|S|2|A|)O(|S|2|A|) 级别,所以人们通常关注 model-free 类方法。这里就不介绍 RMax 了。
3.3 MC-based method
model-free 类方法,整体流程和前面 DP-based 类似,也是先进行 predict,然后利用 greedy-search 来解决 control。
MC-based 方法不需要前面 DP-based 类方法中 P 和 R 的先验,仅需要 experiences —— agent 与 env 的交互序列(s,a,r),即不需知道 model 的真实分布,只需要 model 的真实分布的采样。
算法思路也很简单,利用采样平均值来替代 value func 中的期望值,实质就是使用统计学的方法来取代 Bellman 方法。计算方法还是分两步:
- predict:从初始 state-action 出发,以某种 policy 进行采样,执行该 policy 进行 T 步得到对应轨迹,针对轨迹中每一对 (st,at)(st,at),记录其后的总回报作为对应 state-action 的一次采样值,多次采样得到多条轨迹后将每对 (st,at)(st,at) 的所有 value func 进行 mean 即为该 (st,at)(st,at) 值函数的估计值。
- control:仍用 greedy-search 法。

注意上面 Q 和 V 不再像 DP-based methods 中那样通用。在有 model 时,即使只有 V 也可以利用下一个状态的信息得到 Q 从而决定 policy,但当没有 model 时,仅 V 不足够得到 Q 从而没法指导 policy 更新。因此,MC-based 中 predict 的是 Q 而非 V。
MC-based 方法中 (st,at)的估计是独立于其他 (st,at) 的,因此有一个好处就是可以仅关注感兴趣的 (st,at) ,即仅产生从 (st,at)出发的轨迹。
Incremental mean 原理


exploration-exploitation dilemma
有个问题需要思考下,可能很多(s,a)都不会出现在轨迹中从而没法估计其值函数,尤其当 greedy-search 得到了 deterministic policy,那么岂不是每次轨迹都是一样的?
这就涉及一个经典问题,exploration-exploitation dilemma。常用的处理方法是采用 ε-greedy search,即在 control/探索 时,以 1-ε 选择当下最好的 policy 实现 exploitation,以 ε 进行随机选择实现 exploration。
on/off policy
引入一个概念,在探索和学习阶段,如果采用同一个 policy,即为 on policy,不同则为 off policy。
上面 MC-based method 就是为了探索所以 behave π-ε,但在学习时也使用 π-ε,而实际上我们要学习的应是不带探索的 π,即探索用 π-ε,学习用 π,即 off policy。
通常把 off policy 中用来探索空间(生成轨迹)的 policy 称为 behavior policy,把用来学习(evaluation & improvement)为了达到最优的 policy 称为 target policy。事实上,这种思路不仅用在 MC-based method 中。
由于 behaviour policy 和 target policy 不相关,这种方法方差也较大,比较不容易收敛。但是 off-policy 更强大,更通用。比如,可以使用 off-policy 从人类专家或者传统的控制算法来学习一个增强学习模型。
Importance Sampling
回到 MC-based method 的 off policy 机制,这里面临一个问题,从 π-ε 中采样和 π 是有区别的,一个需要满足的基本假设是 coverage assumption,即 every action taken under π is also taken, at least occasionally, under π-ε。
几乎所有的 off policy 都使用 Importance Sampling 技术,从而可以根据某分布(behaviour policy)的样本来估计另一分布(target policy)的某个期望值(Q)。


具体到 MC-based method,π 对应分布 p,π-ε 对应分布 q,因此在计算 R 时每个来自 π-ε 的样本都要乘上一个 importance weight,其构造方式多样,通常为轨迹在 target policy 和 behavior policy 下的相对概率。算法流程如下 :

3.4 TD-based methods
TD-based methods 结合了 DP-based 方法和 MC-based 方法的思想,即像 MC-based 一样不需要建模可以从 experiences 中直接学习,也像 DP-based 一样基于其他已经学习到的估计来更新估计( 即 bootstrap)。通常认为,TD-based methods 是 RL 的精华与核心。
MC-based method 好理解,但有个严重缺陷,就是一定要跑完所有 epoches 得到整个轨迹以后,才能更新模型,效率很低。即在 MC-based 的 evaluation 过程中,

由于每个 epoch 即可更新一次,所以 TD-based 方法很大一个好处就是可以 on-line 执行。
虽然目前没有理论证明,但实践表明 TD-based 相较 MC-based 收敛的更快一些。
SARSA v.s. Q-learning
把上面 TD-based 的估计方式应用起来,就能得到具体的 RL 算法,下面介绍的 SARSA 就是 on-policy TD-based method,Q-learning 就是 off-policy TD-based method。


仔细观察,可以发现 Q-learning 中 evaluation 的更新也可以写作:
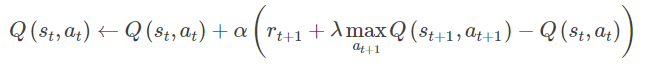
,即相当于把 policy iteration 改为 value iteration。
n-step return
之前列出的算法称为 one-step TD-based method。也可以取 TD-based method 和 MC-based method 两者之间,即利用 n epoches 信息来更新对值函数的估计,对于 n-step return 有
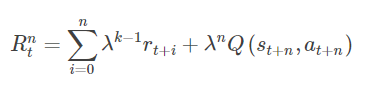
很简单,有 n-step TD-based methods:
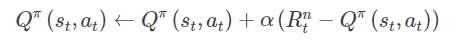
eligibility trace
几乎所有 TD-based methods 都可以结合 eligibility trace 机制,从而更高效地实现。
(该节待补充)
虽然利用 n-step return,也统一了 TD-based 和 MC-based,但相对原始。当 TD-based 结合了 eligibility trace,相当于将原来的方法拓展到一个频谱上,一端是 one-step TD-based(λ=0),一端是 MC-based(λ=1),更完美的统一了 TD-based 和 MC-based。
3.5 Value function approximation
上面所有提到的算法都属于 tabular representation,即值函数是通过一个 lookup table 来表示的,如每个 state 都有对应的 V(s),每个 state-action 都有对应的 Q(s,a)。这种表示自然有难以回避的问题:对于大规模问题(state 空间巨大,state-action 空间巨大)的内存耗费难以接受,学习所有的值函数速度也难以接受。
在有限计算资源情况下,处理大规模 MDP 问题,就需要这里要讲的 approximation solution。准确来说,就是使用监督学习的思想,构建一个函数逼近模型,在已经见过的那部分 state or state-action 空间上构建一个函数逼近的值函数,然后泛化到未知的数据。 可以表达为:
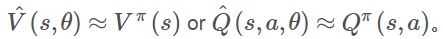

总结下利用函数逼近的大致流程就是:
- 先随机初始化一个 policy,然后使用MC-based or TD-based 的方法来调整 θ 得到 approximation 的值函数;
- 基于该 approximation 的 值函数,进行 policy improvement;
- 然后循环迭代。
即,value function approximation 只做 policy evaluation(predict) 部分,policy improvement(control) 部分还需要单独的策略,比如 ε-greedy,而且 policy evaluation 部分也是在其他 critic-only 算法基础上进行改造,并非完全新算法。
4 Actor-only 类方法
前面介绍到的 Critic-only 类方法,从 DP/MC/TD 到 Value function approximation,关注的是 state 空间的 scaling 问题,那么 action 空间 如何 scaling 呢?面对高维或者连续的 action 空间,critic-only 以来的 greedy-search 方法自然是难以应付了。
此外,基于值函数的方法,存在 policy degradation 现象,这就表明对于次优的 policy 来说,更好的值函数并不对应更好的 policy,因此,前面这种利用优化值函数间接优化 policy 的思路并不完美。

4.2 Likelihood ratio methods
显然上面的方法并不常用,这里介绍 Likelihood ratio methods,也称为 REINFORCE 算法。
stochastic policy gradient theorem
主要是很重要的一个公式,stochastic policy gradient,后面会提到 deterministic policy gradient 公式:
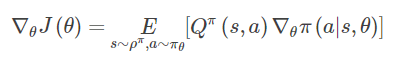
这里加个 logarithm trick,即可将 SPG 公式变为:

deterministic policy gradient theorem

可见期望中去除了 action,这不仅极大提高了在连续空间中梯度的估计效率,也可以处理连续 action 空间了。
此外,这篇文章还证明了它 DPG 是 SPG 当 policy 的 variance 趋向于0时的极限,这意味着 compatible FA,natural gradients 等一众理论都可以应用到 DPG场景。
值得注意的是,deterministic policy 又会导致 exploration 不足。实际中,通常选择动作时用 stochastic behavior policy,学习目标时用 deterministic target policy,即 off-policy。
baseline
再来看下上面用到的 SPG 公式,其表征当值函数越大的 action 越努力提高它出现的概率。但有时某个 state 对应的每个 action 的值函数都为正,即所有的 PG 都为正,此时每个 action 出现的概率都会提高,这会大幅减缓学习速度,并增大 PG 的方差,因此需要对 SPG 公式中的值函数进行某种标准化来降低方差。

此时,更新参数时,值函数超过 baseline 的 action 对应的概率才会提高,理论证明这可以降低 PG 的方差。
实践中,通常选取值函数的一个期望估计作为 baseline。
实际上,这种思路已经类似 Actor-Critic 体系了。
5 Actor-Critic 类方法
首先来回顾下前面介绍到的 Critic-only 类方法、Actor-only 类方法:
- critic-only 低方差,但基于 greedy-search action 无法处理连续 A 域(借助 value function approximation 可以处理连续 S 域)
- actor-only 通过参数化,可以处理连续 A 域,但高方差
AC 类方法,旨在结合两者优点,使用参数化的 actor 来产生 action 并能处理连续 A 域,使用 critic 的低方差的值函数估计来支撑 actor 更新梯度。
简答来说,actor 负责 policy 网络,进行 action-selection,critic 负责 value 网络,通过计算值函数来评价 actor 网络所选动作的好坏

如此以来,critic 利用值函数方法来更好地评估策略,能给 actor 一个更好的梯度估计值,能改善局部优化的问题。 actor 则避免了值函数中低效的值估计过程,同时也能应对连续 A 域。
bootstrap
这里用到的 bootstrap, 指 DP-based、TD-based 中,用某个估计值来更新估计值的思想。DP-based 中,用下一个状态的值函数估计值来估计这个状态的值函数。TD-based 中,部分基于其他状态的估计来更新估计值。而 MC-based 关于各个值函数的估计是独立的,换言之,该状态的值函数估计并不依赖于其他状态的估计,因此,没有利用 bootstrap。
通过 bootstrap,可以引入偏差,以及对函数逼近效果的渐进依赖。这可以降低方差、加快学习速度。
那么就可以看出,虽然 REINFORCE + baseline 方法通过 policy 和值函数来一起学习,但并不能称为 AC 类,因为值函数只在那里用作 baseline 来更新状态,而非用作 bootstrap。如此以来,REINFORCE + baseline 是无偏的,并将渐进收敛于局部最小值,但又会像所有的 MC-based method 那样,由于高方差而学习很慢,且难以在线运行。
所以 AC 架构中,critic 通常选用 TD-based methods。
5.1 Standard Actor-Critic Algorithms

算法流程如下所示:

更多案例请关注“思享会Club”公众号或者关注思享会博客:http://gkhelp.cn/
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









