






例子:最喜欢的编程语言(Example: Favorite Languages)
DataSciencester网站用户调查结果出来了,我们发现在许多大城市里人们所喜欢的编程语言如下:
# each entry is ([longitude, latitude], favorite_language)
cities = [([-122.3 , 47.53], "Python"), # Seattle
([ -96.85, 32.85], "Java"), # Austin
([ -89.33, 43.13], "R"), # Madison
]公司副总裁想要知道,在没有参加调查的地方,是否我们能使用这些结果预测最喜欢的编程语言。
像往常一样,第一个步骤是把数据画出来:
# key is language, value is pair (longitudes, latitudes)
plots = { "Java" : ([], []), "Python" : ([], []), "R" : ([], []) }
# we want each language to have a different marker and color
markers = { "Java" : "o", "Python" : "s", "R" : "^" }
colors = { "Java" : "r", "Python" : "b", "R" : "g" }
for (longitude, latitude), language in cities:
plots[language][0].append(longitude)
plots[language][1].append(latitude)
# create a scatter series for each language
for language, (x, y) in plots.iteritems():
plt.scatter(x, y, color=colors[language],
marker=markers[language],
label=language, zorder=10)
plot_state_borders(plt) # pretend we have a function that does this
plt.legend(loc=0) # let matplotlib choose the location
plt.axis([-130,-60,20,55]) # set the axes
plt.title("Favorite Programming Languages")
plt.show()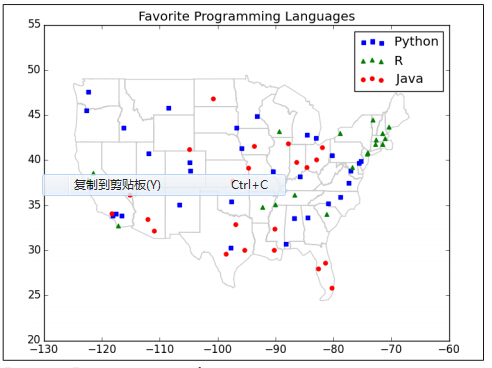
由于相近的地方趋向同一种编程语言,KNN似乎是一种合理的预测语言模型。
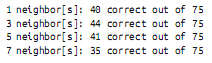
如果我们试着使用相邻城市而不是本身来预测每个城市所喜爱的语言,会发生什么呢:
# try several different values for k
for k in [1, 3, 5, 7]:
num_correct = 0
for city in cities:
location, actual_language = city
other_cities = [other_city
for other_city in cities
if other_city != city]
predicted_language = knn_classify(k, other_cities, location)
if predicted_language == actual_language:
num_correct += 1
print k, "neighbor[s]:", num_correct, "correct out of", len(cities)看起来3NN执行的效果最好,大约59%的正确率:
现在我们能看出在最近邻方案中什么区域被分类成哪种语言,我们能画图如下:
plots = { "Java" : ([], []), "Python" : ([], []), "R" : ([], []) }
k = 1 # or 3, or 5, or ...
for longitude in range(-130, -60):
for latitude in range(20, 55):
predicted_language = knn_classify(k, cities, [longitude, latitude])
plots[predicted_language][0].append(longitude)
plots[predicted_language][1].append(latitude)在下图,展示的是k=1情况:
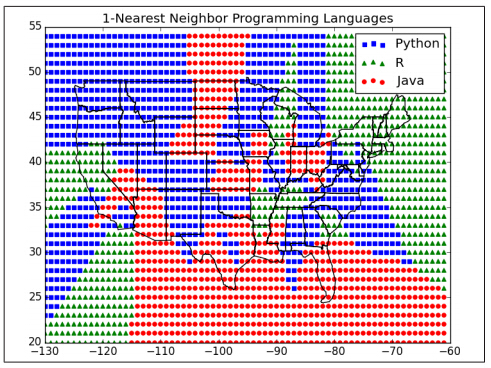
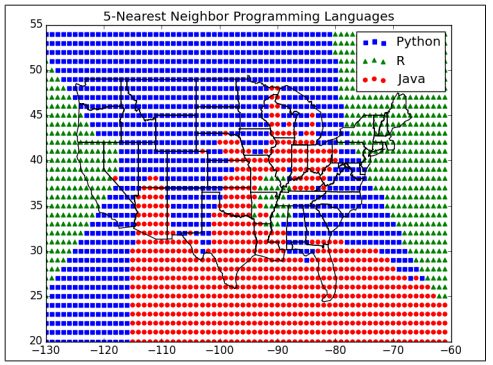
当k增加到5时,边界变得更加光滑:
这里是我们粗略的进行比较,如果它们有单位,你可能想要先进行尺度变换操作。接下来我们将要介绍不同维度距离的变化。















 317
317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









