






 本文展示了一段CUDAFortran代码,用于演示如何利用线程块、流进行并行计算和内存异步传输。程序中包含一个名为kernel的全局子程序,用于执行数学运算。在主程序中,分配了固定内存并创建了多个流,通过异步版本1和版本2对比,展示了如何通过分离数据传输和计算来提高性能,其中版本2可能提供更好的并行效率。
本文展示了一段CUDAFortran代码,用于演示如何利用线程块、流进行并行计算和内存异步传输。程序中包含一个名为kernel的全局子程序,用于执行数学运算。在主程序中,分配了固定内存并创建了多个流,通过异步版本1和版本2对比,展示了如何通过分离数据传输和计算来提高性能,其中版本2可能提供更好的并行效率。
module kernels_m
contains
attributes(global) subroutine kernel(a, offset)
implicit none
real :: a(*)
integer, value :: offset
integer :: i
real :: c, s, x
i = offset + threadIdx%x + (blockIdx%x-1)*blockDim%x
x = threadIdx%x + (blockIdx%x-1)*blockDim%x
s = sin(x); c = cos(x)
a(i) = a(i) + sqrt(s**2+c**2)
end subroutine kernel
end module kernels_m首先命名了名为kernel_m的模块,子程序(subroutine)kernel有两个参数,且被定义为全局(global)函数,这意味着可以调用GPU进行并行计算。
定义了一个实值型数组a,整数变量i,实数参数csx,还声明了一个整型offset,并用value关键字表示此参数只读不可修改,offset指的是偏移量。
对i进行赋值,threadIdx%x表示当前线程在x维度上的索引,blockIdx%x表示当前线程块在x维度上的索引,blockDim%x表示线程块的大小(在x维度上的线程数)。至于线程、线程块、线程数的概念:(CUDA Fortran for Scientists and Engineers Best Practices for Efficient CUDA Fortran Programming)P11
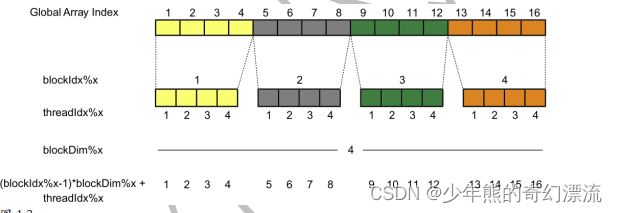
x是当前变量的索引值,但是i对于x来说多了一个偏移量,暂时未知作用是什么,cy一下。
program testAsync
use cudafor
use kernels_m
implicit none
integer, parameter :: blockSize = 256, nStreams = 8
integer, parameter :: n = 16*1024*blockSize*nStreams
real, pinned, allocatable :: a(:)
real, device :: a_d(n)
integer(kind=cuda_Stream_Kind) :: stream(nStreams)
type (cudaEvent) :: startEvent, stopEvent, dummyEvent
real :: time
integer :: i, istat, offset, streamSize = n/nStreams
logical :: pinnedFlag
type (cudaDeviceProp) :: prop
istat = cudaGetDeviceProperties(prop, 0)
write(*,"(' Device: ', a,/)") trim(prop%name)
! allocate pinned host memory
allocate(a(n), STAT=istat, PINNED=pinnedFlag)
if (istat /= 0) then
write(*,*) 'Allocation of a failed'
stop
else
if (.not. pinnedFlag) write(*,*) 'Pinned allocation failed'
end if blockSize 表示每个线程块中的线程数,nStreams 表示流的数量,n代表总的计算数量,a和a_d分别表示可扩展的、固定内存锁定(pinned)的数组和一个设备(GPU)上的数组。
stream 是一个整数数组,其元素数量为 nStreams。kind=cuda_Stream_Kind 表示使用 CUDA 库中定义的特定整数类型。
startEvent、stopEvent 和 dummyEvent 都是 cudaEvent 类型的变量。这些变量用于记录 CUDA 事件,以便测量程序执行时间或同步操作。
实数变量time用于存放程序执行时间,整数变量istat存储函数调用的状态或者错误码,streamSize 定义了每个流 (stream) 处理的元素数量
pinnedFlag是一个逻辑值,用于指示是否成功分配固定内存;prop是一个cudaDeviceProp类型,利用cudaGetDeviceProperties 函数获取当前设备的属性并存在prop中;trim(prop%name) 用于获取设备名称,并通过 write 语句打印出来。
使用 allocate 函数分配固定内存锁定的主机内存空间,即分配大小为 n 的数组 a。STAT 参数用于返回分配状态,PINNED 参数用于指示是否成功分配了固定内存。
istat = cudaEventCreate(startEvent)
istat = cudaEventCreate(stopEvent)
istat = cudaEventCreate(dummyEvent)
do i = 1, nStreams
istat = cudaStreamCreate(stream(i))
enddo
! baseline case - sequential transfer and execute
a = 0
istat = cudaEventRecord(startEvent,0)
a_d = a
call kernel<<<n/blockSize, blockSize>>>(a_d, 0)
a = a_d
istat = cudaEventRecord(stopEvent, 0)
istat = cudaEventSynchronize(stopEvent)
istat = cudaEventElapsedTime(time, startEvent, stopEvent)
write(*,*) 'Time for sequential transfer and execute (ms): ', time
write(*,*) ' max error: ', maxval(abs(a-1.0))
! asynchronous version 1: loop over {copy, kernel, copy}
a = 0
istat = cudaEventRecord(startEvent,0)
do i = 1, nStreams
offset = (i-1)*streamSize
istat = cudaMemcpyAsync(a_d(offset+1),a(offset+1),streamSize,stream(i))
call kernel<<<streamSize/blockSize, blockSize, &
0, stream(i)>>>(a_d,offset)
istat = cudaMemcpyAsync(a(offset+1),a_d(offset+1),streamSize,stream(i))
enddo
istat = cudaEventRecord(stopEvent, 0)
istat = cudaEventSynchronize(stopEvent)
istat = cudaEventElapsedTime(time, startEvent, stopEvent)
write(*,*) 'Time for asynchronous V1 transfer and execute (ms): ', time
write(*,*) ' max error: ', maxval(abs(a-1.0)) 使用 cudaEventCreate 函数创建三个 CUDA 事件:startEvent、stopEvent 和 dummyEvent;使用 cudaStreamCreate 函数创建 nStreams 个流,分别保存在 stream(i) 中(1 到 nStreams)。
cudaEventRecord函数用于记录事件开始时间并传递到参数startEvent。将变量 a 的值赋给 a_d,即将主机内存中的 a 数据复制到设备端的 a_d。调用名为 kernel 的函数,并传递参数 a_d 和 0 进行计算。使用 n/blockSize 个线程块和 blockSize 大小的线程块来执行该内核函数。
使用 cudaEventRecord 函数记录一个事件,并将其保存在 stopEvent 中。该事件用于测量结束时间。使用 cudaEventElapsedTime 函数计算 startEvent 和 stopEvent 之间的时间间隔,并将结果保存到变量 time 中。
对于每个流(共 nStreams 次循环迭代),进行以下操作:计算偏移量 offset,用于指定数据传输的起始位置。使用 cudaMemcpyAsync 函数异步地将主机内存中的部分数据从 a 复制到设备端的 a_d,传输大小为 streamSize,使用对应的流 stream(i)。调用名为 kernel 的函数,通过 CUDA 启动配置语法指定使用 streamSize/blockSize 个线程块和 blockSize 大小的线程块来执行该内核函数,传递参数 a_d 和 offset。用 cudaMemcpyAsync 函数异步地将设备端的部分数据从 a_d 复制回主机内存的 a,传输大小为 streamSize,使用对应的流 stream(i)。
! asynchronous version 2:
! loop over copy, loop over kernel, loop over copy
a = 0
istat = cudaEventRecord(startEvent,0)
do i = 1, nStreams
offset = (i-1)*streamSize
istat = cudaMemcpyAsync(a_d(offset+1),a(offset+1),streamSize,stream(i))
enddo
do i = 1, nStreams
offset = (i-1)*streamSize
call kernel<<<streamSize/blockSize, blockSize, &
0, stream(i)>>>(a_d,offset)
enddo
do i = 1, nStreams
offset = (i-1)*streamSize
istat = cudaMemcpyAsync(a(offset+1),a_d(offset+1),streamSize,stream(i))
enddo
istat = cudaEventRecord(stopEvent, 0)
istat = cudaEventSynchronize(stopEvent)
istat = cudaEventElapsedTime(time, startEvent, stopEvent)
write(*,*) 'Time for asynchronous V2 transfer and execute (ms): ', time
write(*,*) ' max error: ', maxval(abs(a-1.0))
! cleanup
istat = cudaEventDestroy(startEvent)
istat = cudaEventDestroy(stopEvent)
istat = cudaEventDestroy(dummyEvent)
do i = 1, nStreams
istat = cudaStreamDestroy(stream(i))
enddo
deallocate(a)
end program testAsync与上一段代码大同小异,这里就不再解释,可以看出来,整段代码主要可以分为三个部分,第一部分是正常使用核函数进行并行计算;第二部分是使用cuda流先将数据从主机内存复制到设备端内存,然后执行核函数,最后将结果从设备端内存复制回主机内存;第三部分是对于每个流,将数据从主机内存复制到设备端内存。接下来,在另一个循环中,对于每个流,执行核函数。最后,在第三个循环中,对于每个流,将结果从设备端内存复制回主机内存。版本1每个流的操作是顺序执行的(复制数据 - 执行核函数 - 复制数据),而版本2每个流的操作被分开成了三个循环,每个循环只处理一个操作(复制数据、执行核函数、复制数据)。两个版本的目标相同,都是通过利用异步传输和执行来提高程序的性能,但是版本2可能会有更好的并行性能,因为每个操作都在单独的循环中执行,可能会更好地利用系统资源。

















 651
651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









