







今天在爬数据的时候,遇到一个很奇怪的问题。
例如,我爬取的是如下页面:
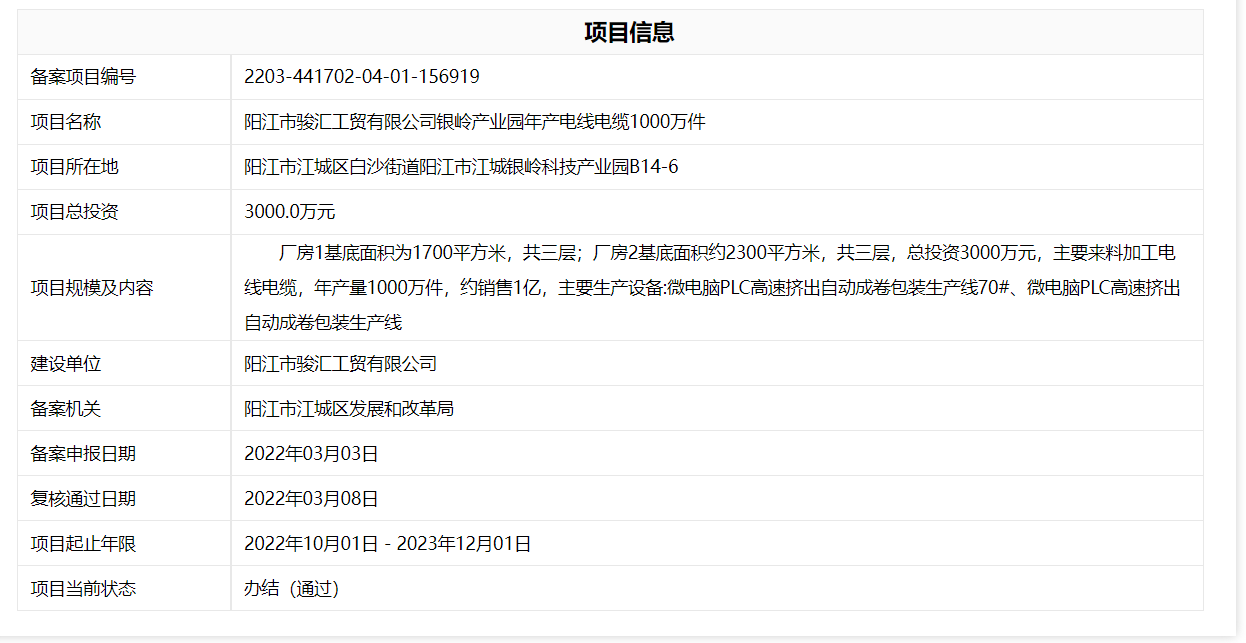
页面 url:https://www.gdtz.gov.cn/tybm/apply3!applyView.action?id=ff80808147c3b2270147d88a2fa3069d
用的采集工具是 requests,但是在采集备案申报日期和复核通过日期这两个字段时,却遇到了些问题。
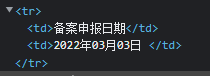
在网页源代码中,备案申报日期对应 html 标签中的文本如下:
但是采集到网页源代码却是如下:
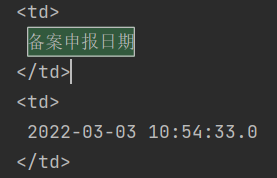
这就很奇怪,目前也不清楚原因。
在这里,获取到的网页源代码经过了 bs4 解析,对应代码如下:
soup = BeautifulSoup(r.text, "html.parser")
还以为是因为 bs4 把这些日期文本进行了自动转化,结果查看 requests 获取到的原始 text 中,日期格式也是这样:

不知道发生了什么。















 801
801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









