







详情可查阅《深入浅出dpdk》里关于 cache的内容
一、cpu cache 系统
cache 都是SRAM。
cpu访问内存大概需要几百个时钟周期,而cpu访问cache却只有几个或最多几十个指令周期。cache的存在目的就是为了匹配处理器和内存之间存在的巨大速度鸿沟。
一个指令周期由若干个cpu周期(机器周期)组成,一个cpu周期由若干个时钟周期组成,访问cache最坏的情况也就和访问内存差不多,但大多数访问cache肯定是快的。
D-cahe:数据cache
I-cahe:指令cache
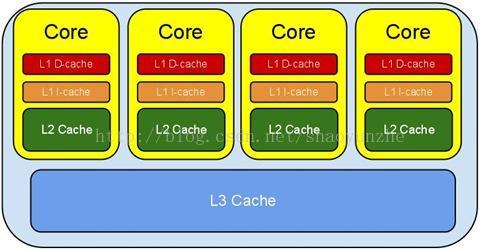
cache 系统示意图
| 成本 | 容量 | 访问周期 | 速度 | |
| 一级cache | 最高 | 几十KB | 3~5个指令周期 | 最快 |
| 二级级cache | 高 | 几百kB-几MB | 十几个指令周期 | 快 |
| 三级cache | 低 | 几MB-几十MB | 几十个指令周期 | 慢 |
cache和内存以块为单位进行数据交换,块的大小通常是以在内存的一个存储周期中能访问到的数据长度,当今主流块大小是64字节
(处理器位长),因此一个cache line就是指64字节大小的数据块。
二、cache和内存的关系
参考点击打开链接
黄色代表了内存块在cacheline大小的内存块中的位置
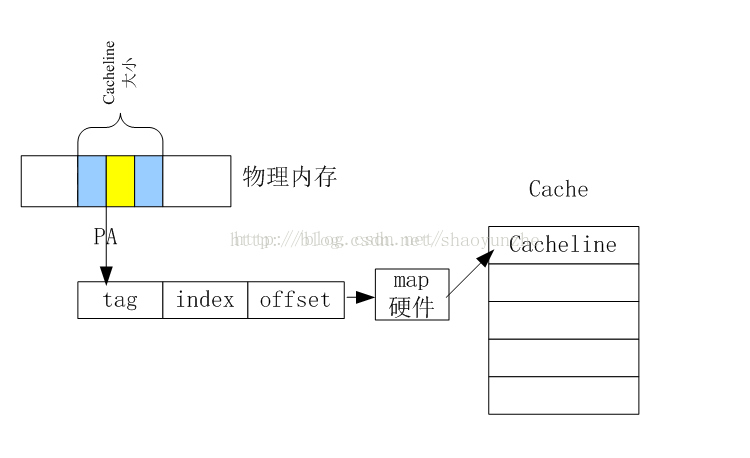
物理内存又是通过物理地址PA(physical address)标识的,内存块用PA+SIZE表示。
在读取内存的时候,CPU会将内存块load到cache中,但是并不是按照SIZE的大小load内存块,而是按照cacheline的大小load一个内存块,指定的物理内存块将被包含在这段被load的内存中。
所以在编程的时候,尽量将结构设计为cacheline对其的,cpu一次指令周期可以加载完成,访问下个结构体的时候,就可以直接访问另一个cacheline,而不发生冲突。
物理地址又被分为三个部分,tag+index+offset。
index就是物理地址在cache这个大数组中的位置,相当于数组索引;
offset说明了PA所在的内存在cacheline中的偏移量;
tag作用请看下面解释;
这样看来,就会发现很可能两个物理地址中见的index很有可能发生重复,这就是cacheline冲突。这样的情况下,就要先废除cacheline上前一个的内容后重新加载新的内存才会有效。这样的冲突会大大降低内存的访问效率,所以intel有提出了一种更新的架构,如下图所示
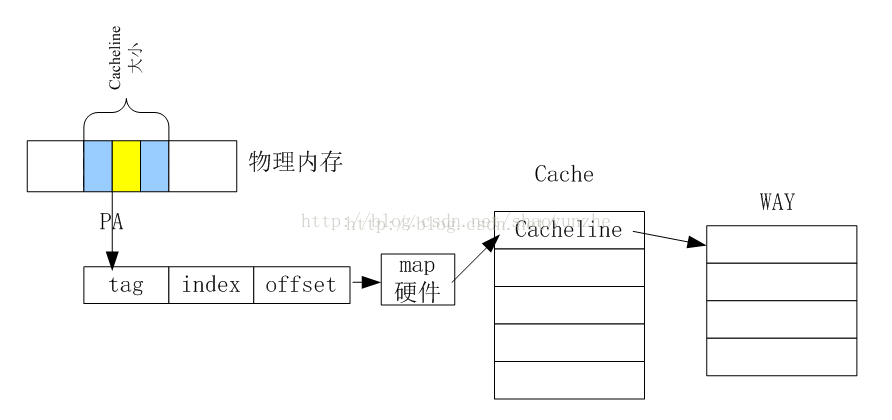
内存和cache的映射
在每个cacheline的下一级又多了way的概念,每个cacheline的下一级又被分为4WAY或8WAY,每个way都相当于一个cacheline。这样即使index冲突,也可以将内存内容放到不同的way中减少冲突。tag就是用来表示是哪个way。上面的结构就是所谓的4路组相连或8路组相连的概念。
三、cache 预取
硬件预取:硬件根据局部性原理,自动预测将要处理的数据并取入到cache中,减少cache不命中,提高cpu效率。具体原理查阅相关资料。
软件预取:通过预取指令,开发者根据需要,自主的把即将用到的数据从内存加载到cache中,减少cpu访问内存,提高cpu效率。
四、cache 一致性
主要有两个问题
1:cache line是否对齐,内存的数据结构或是数据缓冲区的起始地址和cache line的起始位置怎么保证对齐。如果对齐,当映射到cache line的数据小于cache line的大小时,不必要访问2个cache line(eg,假如cache line大小是64B,内存映射数据大小48B,但数据的起始位置映射到一个cache line的20B开始处,第一个cache line只剩44个字节空间,剩下的4字节必定会映射到第二个cache line的前4字节,当cpu处理这个数据结构时,必定会花取2个cache line的时间,如果对齐,cpu只会花一个)。
2:cache line和内存同步,当多个核同时对某段内存进行读写,当同时对内存进行回写时,如何解决冲突。
业界解决方案
1 cache line对齐:
使用伪指令#pragma pack (n),C编译器将按照n个字节对齐。
使用伪指令#pragma pack (),取消自定义字节对齐方式。
__attribute__ ((aligned (n))) 变量或者结构体成员使用n字节对齐,如果结构中有成员的长度大于n,则按照最大成员的长度来对齐;
__attribute__((packed)) 变量或者结构体成员使用最小的对齐方式,即对变量是一字节对齐;
要cache line对齐,肯定是设置n的的大小为cache line的大小
2 一致性协议:使用MESI协议解决一致性问题,这不是我关注的重点。
五、 DPDK 优化cache
1 dpdk预取数据
while (nb_rx < nb_pkts) {
rxdp = &rx_ring[rx_id];
staterr = rxdp->wb.upper.status_error;
/* 检查是否有报文收到*/
if (!(staterr & rte_cpu_to_le_32(IXGBE_RXDADV_STAT_DD)))
break;
rxd = *rxdp;
/* 分配数据缓冲区*/
nmb = rte_mbuf_raw_alloc(rxq->mb_pool);
if (nmb == NULL) {
PMD_RX_LOG(DEBUG, "RX mbuf alloc failed port_id=%u "
"queue_id=%u", (unsigned) rxq->port_id,
(unsigned) rxq->queue_id);
rte_eth_devices[rxq->port_id].data->rx_mbuf_alloc_failed++;
break;
}
nb_hold++;
/* 读取控制报文结构体 */
rxe = &sw_ring[rx_id];
rx_id++;
if (rx_id == rxq->nb_rx_desc)
rx_id = 0;
/* 预取下一个控制结构体mbuf */
rte_ixgbe_prefetch(sw_ring[rx_id].mbuf);
/* 预取接收描述符和控制结构体指针 */
if ((rx_id & 0x3) == 0){
rte_ixgbe_prefetch(&rx_ring[rx_id]);
rte_ixgbe_prefetch(&sw_ring[rx_id]);
}
rxm = rxe->mbuf;
rxe->mbuf = nmb;
dma_addr =rte_cpu_to_le_64(rte_mbuf_data_dma_addr_default(nmb));
rxdp->read.hdr_addr = 0;
rxdp->read.pkt_addr = dma_addr;
pkt_len = (uint16_t) (rte_le_to_cpu_16(rxd.wb.upper.length) - rxq->crc_len);
rxm->data_off = RTE_PKTMBUF_HEADROOM;
/* 预取报文 */
rte_packet_prefetch((char *)rxm->buf_addr + rxm->data_off);
/* 把接收到描述符读取的信息存储在控制结构体mbuf中 */
rxm->nb_segs = 1;
rxm->next = NULL;
rxm->pkt_len = pkt_len;
rxm->data_len = pkt_len;
rxm->port = rxq->port_id;
......
rx_pkts[nb_rx++] = rxm;
}
#define RTE_CACHE_LINE_SIZE 64
#define __rte_cache_aligned __attribute__ ((__aligned (RTE_CACHE_LINE_SIZE )))
struct rte_mempool_debug_stats {
uint64_t put_bulk; /**< Number of puts. */
uint64_t put_objs; /**< Number of objects successfully put. */
uint64_t get_success_bulk; /**< Successful allocation number. */
uint64_t get_success_objs; /**< Objects successfully allocated. */
uint64_t get_fail_bulk; /**< Failed allocation number. */
uint64_t get_fail_objs; /**< Objects that failed to be allocated. */
} __rte_cache_aligned;3 一致性问题:
dpdk的解决方案就是避免多个核访问同一个内存地址或是数据结构
eg:数据结构的定义是每个核单独一份, 网卡接收发送队列的分配,也是每个核单独操作某个或某几个接收和发送队列。















 607
607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









