







一、为什么要有Cache
处理器速度越来越来,但是内存吞吐量较处理器还是很慢,一般来讲,处理器要从内存中直接读取数据都要花大概几百个时钟周期,在这几百个时钟周期内,处理器除了等待什么也不能做。在这种环境下,才提出了Cache的概念,其目的就是为了匹配处理器和内存之间存在的巨大的速度鸿沟。
二、Cache分布及速度
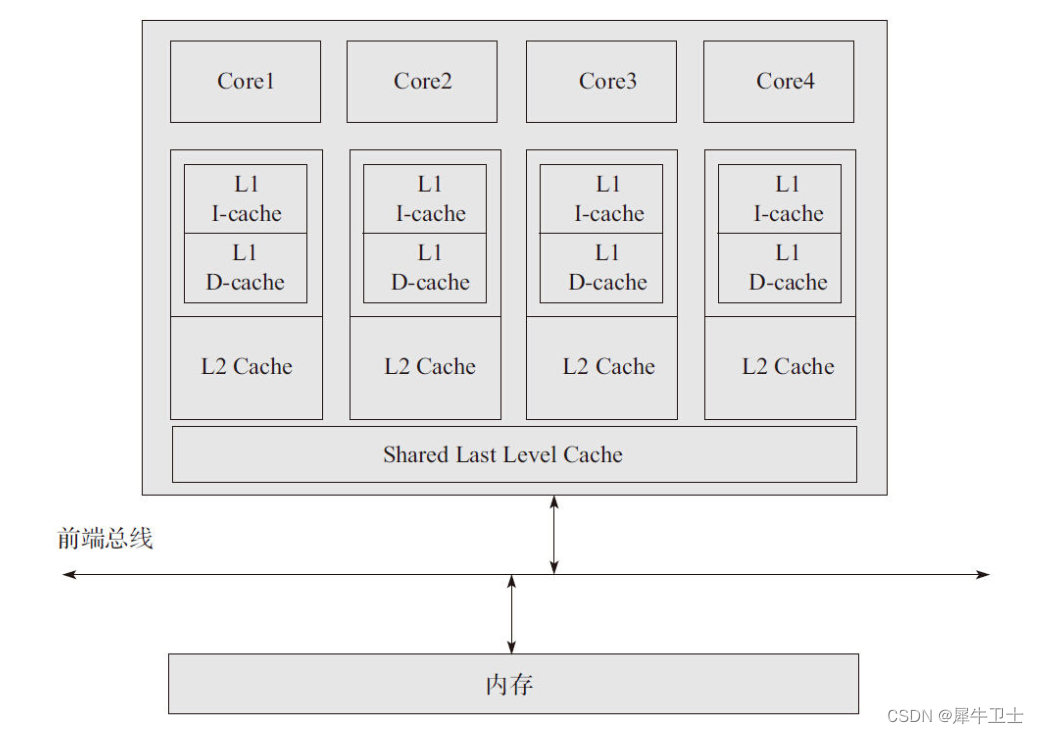
一般每个CPU都独立的有1、2cache,共享第3级cache。一级Cache速度最快,一般处理器只需要3~5个指令周期就能访问到数据,因此成本高,容量小,一般都只有几十KB,二级相比一级Cache慢一些,处理器大约需要十几个处理器周期才能访问到数据,容量也相对来说大一些,一般有几百KB到几MB不等,三级Cache,速度更慢,处理器需要几十个处理器周期才能访问到数据,容量更大,一般都有几MB到几十个MB。在英特尔的处理器上一直都保持着非常稳定,一级Cache访问是4个指令周期,二级Cache是12个指令周期,三级Cache则是26~31个指令周期。这里所谓的稳定,是指在不同频率、不同型号的英特尔处理器上,处理器访问这三级Cache所花费的指令周期数是相同的。
三、内存数据怎么映射到Cache中的
一个映射算法和一个分块机制。
分块机制就是说,Cache和内存以块为单位进行数据交换,块的大小通常以在内存的一个存储周期中能够访问到的数据长度为限。当今主流块的大小都是64字节,因此一个Cache line就是指64个字节大小的数据块。
映射算法是指把内存地址空间映射到Cache地址空间。具体来说,就是把存放在内存中的内容按照某种规则装入到Cache中,并建立内存地址与Cache地址之间的对应关系。当内容已经装入到Cache之后,在实际运行过程中,当处理器需要访问这个数据块内容时,则需要把内存地址转换成Cache地址,从而在Cache中找到该数据块,最终返回给处理器。
四、Cache实现
有直接关联性(确定块到确定cache lline),全关联性(任意内存到任意cache line),组关联性(前两者的组合)
组关联型Cache是目前Cache中用的比较广泛的一种方式,是前两种Cache的折中形式。在这种方式下,内存被分为很多组,一个组的大小为多个Cache line的大小,一个组映射到对应的多个连续的Cache line,也就是一个Cache组,并且该组内的任意一块可以映射到对应Cache组的任意一个。可以看出,在组外,其采用直接关联型Cache的映射方式,而在组内,则采用全关联型Cache的映射方式。
五、Cache写策略
回写系统通过将Cache line的标志位字段添加一个Dirty标志位,当处理器在改写了某个Cache line后,并不是马上把其写回内存,而是将该Cache line的Dirty标志设置为1。当处理器再次修改该Cache line并且写回到Cache中,查表发现该Dirty位已经为1,则先将Cache line内容写回到内存中相应的位置,再将新数据写到Cache中
几种特殊的Cache回写机制
write-combining策略是针对于具体设备内存(如显卡的RAM)的一种优化处理策略,这种策略就是当一个Cache line里的数据一个字一个字地都被改写完了之后,才将该Cache line写回到内存中
uncacheable内存是一部分特殊的内存,比如PCI设备的I/O空间通过MMIO方式被映射成内存来访问。这种内存是不能缓存在Cache中的,因为设备驱动在修改这种内存时,总是期望这种改变能够尽快通过总线写回到设备内部,从而驱动设备做出相应的动作。如果放在Cache中,硬件就无法收到指令。
六、Cache预取
一些体系架构引入了能够对Cache进行预取的指令,从而使一些对程序执行效率有很高要求的程序员能够一定程度上控制Cache,加快程序的执行。比如需要顺序处理的数组。
所谓的Cache预取,也就是预测数据并取入到Cache中,是根据空间局部性和时间局部性,以及当前执行状态、历史执行过程、软件提示等信息,然后以一定的合理方法,在数据/指令被使用前取入Cache。这样,当数据/指令需要被使用时,就能快速从Cache中加载到处理器内部进行运算和执行
什么情况下才会预取
1)读取的数据是回写(Writeback)的内存类型。(非MMIO类型的)
2)预取的请求必须在一个4K物理页的内部。这是因为对于程序员来说,虽然指令和数据的虚拟地址都是连续的,但是分配的物理页很有可能是不连续的。而预取是根据物理地址进行判断的,因此跨界预取的指令和数据很有可能是属于其他进程的,或者没有被分配的物理页。
3)处理器的流水线作业中没有fence或者lock这样的指令。
4)当前读取(Load)指令没有出现很多Cache不命中。
5)前端总线不是很繁忙。
6)没有连续的存储(Store)指令。
软件预取指令
预取指令使软件开发者在性能相关区域,把即将用到的数据从内存中加载到Cache,这样当前数据处理完毕后,即将用到的数据已经在Cache中,大大减小了从内存直接读取的开销,也减少了处理器等待的时间,从而提高了性能。
DPDK I40E 驱动受包函数预取举例
0 uint16_t
1 i40e_recv_pkts(void *rx_queue, struct rte_mbuf **rx_pkts, uint16_t nb_pkts)
2 {
3 struct i40e_rx_queue *rxq;
4 volatile union i40e_rx_desc *rx_ring;
5 volatile union i40e_rx_desc *rxdp;
6 union i40e_rx_desc rxd;
7 struct i40e_rx_entry *sw_ring;
8 struct i40e_rx_entry *rxe;
9 struct rte_mbuf *rxm;
10 struct rte_mbuf *nmb;
11 uint16_t nb_rx;
12 uint32_t rx_status;
13 uint64_t qword1;
14 uint16_t rx_packet_len;
15 uint16_t rx_id, nb_hold;
16 uint64_t dma_addr;
17 uint64_t pkt_flags;
18 nb_rx = 0;
19 nb_hold = 0;
20 rxq = rx_queue;
21 rx_id = rxq->rx_tail;
22 rx_ring = rxq->rx_ring;
23 sw_ring = rxq->sw_ring;
24 while (nb_rx < nb_pkts)
25 {
26 rxdp = &rx_ring[rx_id];
27 qword1 = rte_le_to_cpu_64(rxdp->wb.qword1.status_error_len);
28 rx_status = (qword1 & I40E_RXD_QW1_STATUS_MASK)
29 >> I40E_RXD_QW1_STATUS_SHIFT;
30 /* Check the DD bit first */
31 if (!(rx_status & (1 << I40E_RX_DESC_STATUS_DD_SHIFT)))
32 break;
33 nmb = rte_mbuf_raw_alloc(rxq->mp);
34 if (unlikely(!nmb))
35 break;
36 rxd = *rxdp;
37 nb_hold++;
38 rxe = &sw_ring[rx_id];
39 rx_id++;
40 if (unlikely(rx_id == rxq->nb_rx_desc))
41 rx_id = 0;
42 /* Prefetch next mbuf */
43 rte_prefetch0(sw_ring[rx_id].mbuf);
44 /**
45 * When next RX descriptor is on a cache line boundary,
46 * prefetch the next 4 RX descriptors and next 8 pointers
47 * to mbufs.
48 */
49 if ((rx_id & 0x3) == 0)
50 {
51 rte_prefetch0(&rx_ring[rx_id]);
52 rte_prefetch0(&sw_ring[rx_id]);
53 }
54 rxm = rxe->mbuf;
55 rxe->mbuf = nmb;
56 dma_addr =
57 rte_cpu_to_le_64(rte_mbuf_data_dma_addr_default(nmb));
58 rxdp->read.hdr_addr = 0;
59 rxdp->read.pkt_addr = dma_addr;
60 rx_packet_len = ((qword1 & I40E_RXD_QW1_LENGTH_PBUF_MASK) >>
61 I40E_RXD_QW1_LENGTH_PBUF_SHIFT) - rxq->crc_len;
62 rxm->data_off = RTE_PKTMBUF_HEADROOM;
63 rte_prefetch0(RTE_PTR_ADD(rxm->buf_addr, RTE_PKTMBUF_HEADROOM));
64 rxm->nb_segs = 1;
65 rxm->next = NULL;
66 rxm->pkt_len = rx_packet_len;
67 rxm->data_len = rx_packet_len;
68 rxm->port = rxq->port_id;
69 rxm->ol_flags = 0;
70 i40e_rxd_to_vlan_tci(rxm, &rxd);
71 pkt_flags = i40e_rxd_status_to_pkt_flags(qword1);
72 pkt_flags |= i40e_rxd_error_to_pkt_flags(qword1);
73 rxm->packet_type =
74 i40e_rxd_pkt_type_mapping((uint8_t)((qword1 &
75 I40E_RXD_QW1_PTYPE_MASK) >> I40E_RXD_QW1_PTYPE_SHIFT));
76 if (pkt_flags & PKT_RX_RSS_HASH)
77 rxm->hash.rss =
78 rte_le_to_cpu_32(rxd.wb.qword0.hi_dword.rss);
79 if (pkt_flags & PKT_RX_FDIR)
80 pkt_flags |= i40e_rxd_build_fdir(&rxd, rxm);
81 #ifdef RTE_LIBRTE_IEEE1588
82 pkt_flags |= i40e_get_iee15888_flags(rxm, qword1);
83 #endif
84 rxm->ol_flags |= pkt_flags;
85 rx_pkts[nb_rx++] = rxm;
86 }
87 rxq->rx_tail = rx_id;
88 /**
89 * If the number of free RX descriptors is greater than the RX free
90 * threshold of the queue, advance the receive tail register of queue.
91 * Update that register with the value of the last processed RX
92 * descriptor minus 1.
93 */
94 nb_hold = (uint16_t)(nb_hold + rxq->nb_rx_hold);
95 if (nb_hold > rxq->rx_free_thresh) {
96 rx_id = (uint16_t)((rx_id == 0) ?
97 (rxq->nb_rx_desc - 1) : (rx_id - 1));
98 I40E_PCI_REG_WRITE(rxq->qrx_tail, rx_id);
99 nb_hold = 0;
100 }
101 rxq->nb_rx_hold = nb_hold;
102 return nb_rx;
103}这段代码是DPDK中I40E驱动的接收报文函数。这个函数的目的是从接收队列中接收报文,并将其存储在`rx_pkts`数组中。
18-23 行,初始化了一些变量,包括接收计数器`nb_rx`、保留计数器`nb_hold`、接收队列指针`rxq`、接收队列的尾部索引`rx_id`、接收环形缓冲区指针`rx_ring`和软件环形缓冲区指针`sw_ring`。
24-86 行的while循环中,遍历接收队列中的描述符,直到接收到`nb_pkts`个报文或者没有更多报文可接收为止。在每次循环迭代中,首先获取当前描述符的状态和错误信息,并检查DD位(Done位)是否已设置,表示该描述符中有数据可供接收。
其中43-53行 这段代码是cache预取部分。在每次循环迭代中,使用`rte_prefetch0`函数进行预取操作,以便在未来的循环迭代中更快地访问相关的数据。首先,预取下一个软件环形缓冲区中的`mbuf`指针,以便在下一次循环迭代中更快地访问。接着,检查下一个接收描述符是否位于缓存行边界上(即`rx_id`的低两位是否为0)。如果是的话,还会预取接收环形缓冲区中的下4个接收描述符和下8个`mbuf`指针。这样做是为了利用CPU缓存的局部性原理,预取与当前循环迭代相关的数据,以提高访问效率。
89行后边的部分检查是否需要更新接收队列的尾部索引。如果空闲的接收描述符数量大于接收队列的空闲阈值(`rx_free_thresh`),则更新接收队列的尾部索引为最后处理的接收描述符的索引减1。这样做是为了确保接收队列中始终有足够的空闲描述符可供接收报文。
DPDK 基本所有应用态网卡驱动中都有如上边所贴代码一样的机制, 通过预先加载数据到CPU缓存中,以减少内存访问延迟,从而提高程序的性能。
七、Cache一致性
多核,cache非共享(一级、二级),会存在cache一致性问题
两种情况:
1、数据结构不是Cache line 对齐得,即使数据区域的大小小于Cache Line,那么也需要占用两个Cache entry;并且,假设第一个Cache Line前半部属于另外一个数据结构并且另外一个处理器核正在处理它,这样有两个核在一个cache line上写不同得数据结构
2、数据结构的起始地址是Cache Line对齐的,但是有多个核同时对该段内存进行读写,当同时对内存进行写回操作;
Cache一致性解决方法
DPDK解决一致性问题结合了以下两种思路,1)比如多核接受报文得结构定义时就是cache对齐的; 2)为每一个核单独分配一个结构,避免内存共享。
struct lcore_conf {
uint64_t tsc;
uint64_t tsc_count;
uint32_t tx_mask;
uint16_t n_rx_queue;
uint16_t rx_queue_list_pos;
struct lcore_rx_queue rx_queue_list[MAX_RX_QUEUE_PER_LCORE];
uint16_t tx_queue_id[RTE_MAX_ETHPORTS];
struct mbuf_table rx_mbuf;
uint32_t rx_mbuf_pos;
uint32_t rx_curr_queue;
struct mbuf_table tx_mbufs[RTE_MAX_ETHPORTS];
} __rte_cache_aligned;
struct lcore_conf lcore[RTE_MAX_LCORE] __rte_cache_aligned;以上数据结构lcore_conf 总是以Cache 行对齐,这样就不会出现该数据结构横跨两个Cache行的问题。 定义的lcore[RTE_MAX_LCORE] 结构体数组中RTE_MAX_LCORE是指系统中最大核的数量。DPDK对每一个核进行编号,这样核n就只需要访问lcore[n],核n1只需要访问lcore[n1],这样就避免了对多个核访问同一个结构体。

















 332
332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









