






在nlu中,除了intent,某些特殊场景下需要使用同义词、查找表、正则表达式字段,来使实体提取更准确。
同义词字段
具有synonym键表明当前的对象是用来存储同义词信息的。
同义词的作用是,当一个实体有多种叫法的时候,可以将多种叫法转成一个正式的叫法,并替换到实体中,方便后续的action操作。如蟾蜍有很多民间叫法(癞蛤蟆),但是查询数据库时,只能用蟾蜍。
在启动EntitySynonymMapper组件的情况下,推理时会将得到的实体值的同义词替换成它的“标准词”。
注意:同义词映射只发生在实体被提取之后。这意味着您的训练示例应包括同义词示例 (西红柿、洋柿子),以便模型学习将这些识别为实体并将它们替换为 番茄。
下面是同义词配置的完整示例。
- intent: query_vegetables_price
examples: |
- [番茄](vegetables)多少钱一斤
- [番茄](vegetables)怎么卖
- [番茄](vegetables)什么价
- [西红柿](vegetables)多少钱一斤
- [西红柿](vegetables)怎么卖
- [西红柿](vegetables)什么价
- [洋柿子](vegetables)多少钱一斤
- [洋柿子](vegetables)怎么卖
- [洋柿子](vegetables)什么价
- [蕃茄](vegetables)多少钱一斤
- [蕃茄](vegetables)怎么卖
- [蕃茄](vegetables)什么价
- synonym: 番茄
examples: |
- 番茄
- 西红柿
- 洋柿子
- 蕃茄注意,使用同义词,需要在pipline中增加EntitySynonymMapper。
pipeline:
- name: JiebaTokenizer
- name: LanguageModelFeaturizer
model_name: bert
model_weights: bert-base-chinese
- name: "DIETClassifier"
epochs: 100
- name: "EntitySynonymMapper" #当nlu中配置了synonym同义词时,需要增加此配置,否则同义词实体提取不到
# learning_rate: 0.001
# intent_classification: true
# entity_recognition: true
# - name: ResponseSelector
# epochs: 100rasa train nlu
rasa shell nlu
使用以上命令训练并测试语义结果。
在有synonym配置的情况下,“洋柿子怎么卖”的语音结果中,实体从“洋柿子”变成了“番茄”。
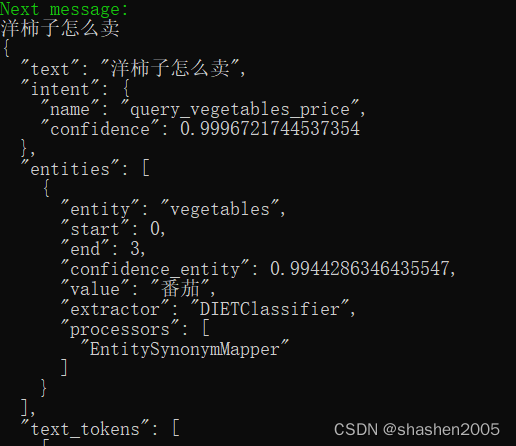
如果将synonym配置注释后,验证结果如下,实体没有被替换。
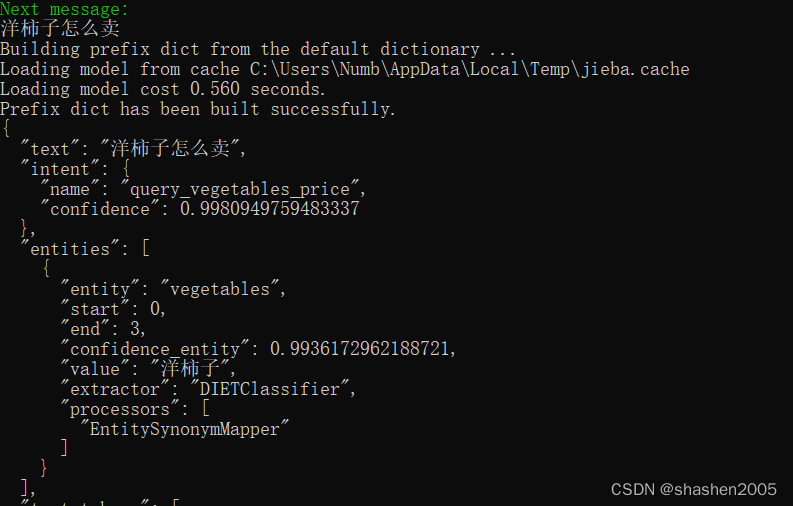
查找表字段
配置nlu.yml
- intent: country_location
examples: |
- [中国](country)在什么位置
- [中国](country)在南半球还是北半球
- [中国](country)地理位置
- [中国](country)在地球哪里
- lookup: country
examples: |
- 中国
- 美国
- 加拿大
- 澳大利亚
- 韩国
- 新加坡
- 墨西哥
- 俄罗斯配置config.yml
pipeline:
- name: JiebaTokenizer
- name: LanguageModelFeaturizer
model_name: bert
model_weights: bert-base-chinese
- name: "DIETClassifier"
epochs: 100
- name: RegexEntityExtractor #当nlu中使用了查找表或者正则字段提取实体时,需要添加RegexEntityExtractor
# 区分大小写
case_sensitive: False
# 是否使用查找表
use_lookup_tables: True
# 是否使用正则匹配
use_regexes: True
# 单词边界,中文没有空格,需要设置为false
use_word_boundaries: False
- name: "EntitySynonymMapper" #当nlu中配置了synonym同义词时,需要增加此配置,否则同义词实体提取不到测试语义,“俄罗斯在什么位置”,结果:
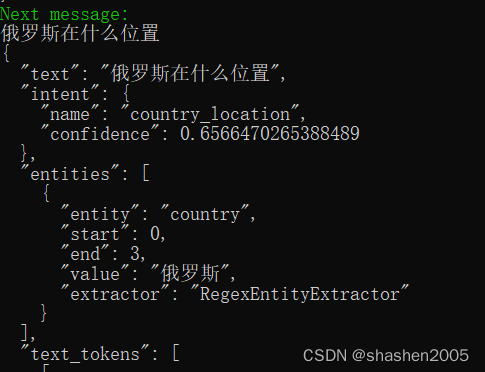
如果,查找表数据很多,可以改成文件方式,方便管理。
注意:下面的方法,测试暂时不通过,总是提示没有对应的查找表数据。
在rasa3中,Rasa 3 会自动在 data 目录中查找 lookup_tables 文件夹和其中的文本文件。因此,您不需要为 LookupTable 组件指定文件的绝对路径或相对路径。
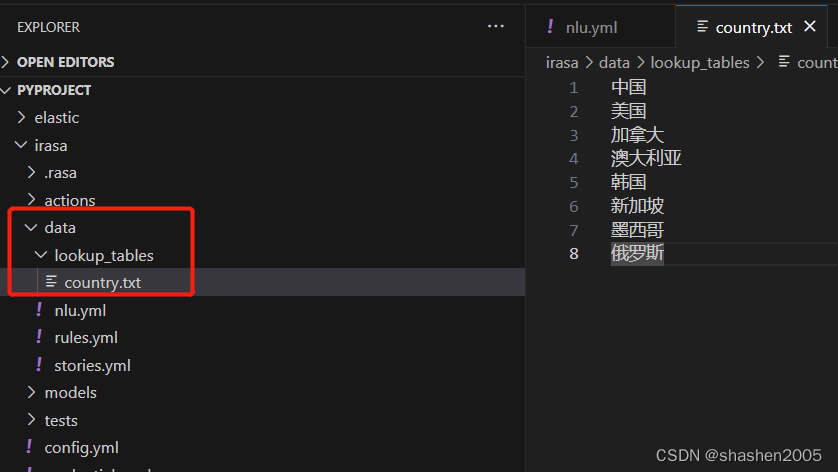
1. 在您的项目data目录下创建一个名为 lookup_tables 的文件夹。
2. 在 lookup_tables 文件夹中创建一个文本文件,并以实体名称命名该文件。例如,如果您要创建一个名为 country 的实体,可以在 lookup_tables 文件夹中创建一个名为 country.txt 的文件。
3. 在 country.txt 文件中添加实体,每行一个。
4. config.yml 和上面一样,使用RegexEntityExtractor并开启查找表。
测试结果和之前的一样。
注意:DIETClassifier和RegexEntityExtractor同时使用,会提取出2个同样的实体,如下图:
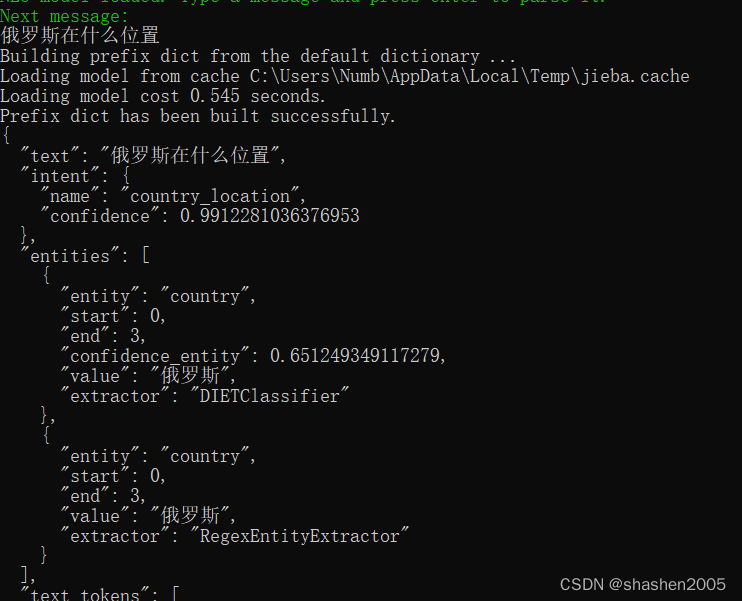
这是因为 RegexEntityExtractor 使用基于规则的方式来匹配实体,而 DIETClassifier 则使用基于机器学习的方式来提取实体,两者之间可能存在冲突。
为了避免重复的实体提取,您可以考虑采取以下措施:
-
只使用
DIETClassifier提取实体。由于DIETClassifier使用基于机器学习的方式来提取实体,因此它通常比RegexEntityExtractor更准确。如果您只使用DIETClassifier来提取实体,就可以避免重复实体的问题。 -
只使用
RegexEntityExtractor提取实体。如果您的实体是基于一些固定的规则或模式定义的,并且可以使用RegexEntityExtractor来准确匹配实体,那么您可以只使用RegexEntityExtractor来提取实体,而不使用DIETClassifier。这样可以避免DIETClassifier和RegexEntityExtractor之间的冲突。 -
调整实体提取的优先级。如果您同时使用
DIETClassifier和RegexEntityExtractor来提取实体,可以尝试调整它们的优先级来避免重复实体的问题。例如,您可以将RegexEntityExtractor的优先级设置为较低,这样在DIETClassifier无法提取实体时才会使用RegexEntityExtractor来提取实体。
# NLU Pipeline
pipeline:
- name: DIETClassifier
# 将 DIETClassifier 的优先级设置为 1
priority: 1
- name: RegexEntityExtractor
# 将 RegexEntityExtractor 的优先级设置为 2
priority: 2优先级方式测试不行,还是出2个实体,在rasa中,pipeline 中的组件是按照顺序执行的,可以调整DIETClassifier和RegexEntityExtractor的上下顺序,看自己的实际效果。
正则表达式
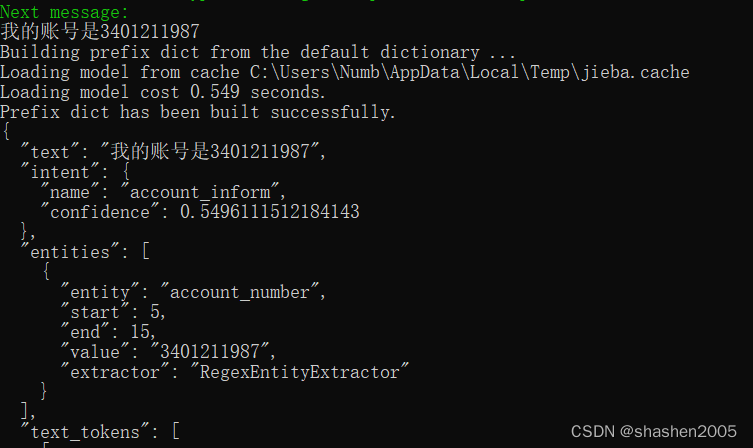
编写nlu.yml
- intent: account_inform
examples: |
- 我的账号是[1234567891](account_number)
- 这是我的账号[1234567891](account_number)
- [1234567891](account_number)
- regex: account_number
examples: |
- \d{10,12}测试结果















 853
853











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









