






间隔与支持向量
给定训练样本集
D
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
,
,
,
(
x
m
,
y
m
)
}
,
y
i
∈
)
{
−
1
,
+
1
}
D=\{(x_1,y_1),(x_2,y_2),,,,(x_m,y_m)\}, y_i\in)\{-1,+1\}
D={(x1,y1),(x2,y2),,,,(xm,ym)},yi∈){−1,+1},分类学习最基本的想法就是基于训练集D在样本空间中找到一个划分超平面,将不同类别的样本分开.
在样本空间中,划分超平面可通过如下线性方程来描述:
w
T
x
+
b
=
0
(1)
w^Tx+b=0 \tag{1}
wTx+b=0(1)
其中
w
=
(
w
1
;
w
2
;
.
.
.
;
w
d
)
w=(w_1;w_2;...;w_d)
w=(w1;w2;...;wd)为法向量,决定了超平面的方向;b为位移项,决定了超平面与原点之间的距离.
法向量定义:垂直于平面的直线所表示的向量为该平面的法向量.
证明如下:
设点
x
1
,
x
2
x_1,x_2
x1,x2在超平面中,则有
w
T
x
1
+
b
=
0
w
T
x
2
+
b
=
0
\begin{aligned} w^Tx_1+b&=0 \\ w^Tx_2+b&=0 \end{aligned}
wTx1+bwTx2+b=0=0
上面两式相减,有:
w
T
(
x
1
−
x
2
)
=
0
w_T(x_1-x_2)=0
wT(x1−x2)=0
上式标明
w
⊥
(
x
1
−
x
2
)
w\perp(x_1-x_2)
w⊥(x1−x2),差矢量
x
1
−
x
2
x_1-x_2
x1−x2在超平面中,由于
x
1
,
x
2
x_1,x_2
x1,x2是超平面中任意两点,所以w垂直于超平面,即为超平面的法向量.
样本空间中任意点x到超平面(w,b)的距离可写为
r
=
w
T
x
+
b
∣
∣
w
∣
∣
(2)
r=\frac{w^Tx+b}{||w||} \tag{2}
r=∣∣w∣∣wTx+b(2)
证明:
设p为超平面中任意一点,则点x到超平面的距离为差矢量(x-p)在超平面法向量的投影的绝对值.
r
=
∣
w
T
∣
∣
w
T
∣
∣
(
x
−
p
)
∣
=
1
∣
∣
w
T
∣
∣
⋅
∣
w
T
x
−
w
T
p
∣
=
1
∣
∣
w
T
∣
∣
⋅
∣
w
T
x
+
b
∣
=
∣
w
T
x
+
b
∣
∣
∣
w
∣
∣
\begin{aligned} r &= |\frac{w^T}{||w^T||}(x-p)| \\ &= \frac{1}{||w^T||}\cdot |w^Tx-w^Tp| \\ &= \frac{1}{||w^T||}\cdot |w^Tx+b| \\ &= \frac{|w^Tx+b|}{||w||} \end{aligned}
r=∣∣∣wT∣∣wT(x−p)∣=∣∣wT∣∣1⋅∣wTx−wTp∣=∣∣wT∣∣1⋅∣wTx+b∣=∣∣w∣∣∣wTx+b∣
假设超平面(w,b)能将训练样本正确分类,即对于
(
x
i
,
y
i
)
∈
D
(x_i,y_i)\in D
(xi,yi)∈D,若
y
i
=
+
1
y_i=+1
yi=+1,则有
w
T
x
+
b
>
0
w^Tx+b>0
wTx+b>0;若
y
i
=
−
1
y_i=-1
yi=−1,则有
w
T
x
+
b
<
0
w^Tx+b<0
wTx+b<0. 令
w
T
x
i
+
b
>
=
+
1
,
y
i
=
+
1
w
T
x
i
+
b
<
=
−
1
,
y
i
=
−
1
(3)
\begin{aligned} w^Tx_i+b&>= +1, y_i=+1 \\ w^Tx_i+b&<= -1, y_i=-1 \tag{3} \end{aligned}
wTxi+bwTxi+b>=+1,yi=+1<=−1,yi=−1(3)
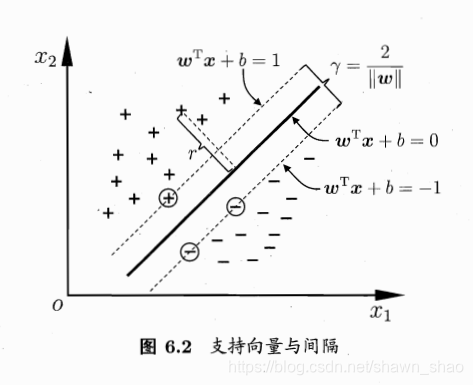
如上图所示,距离超平面最近的几个训练样本使得式(3)的等号成立,它们被称为"支持向量".两个异类支持向量到超平面的距离之和为
γ
=
2
∣
∣
w
∣
∣
(4)
\gamma = \frac{2}{||w||} \tag{4}
γ=∣∣w∣∣2(4)
它被称为"间隔".
欲找到具有最大间隔的划分超平面,也就是要找到能满足式(3)种约束的参数w和b,使得
γ
\gamma
γ最大,即
w
,
b
m
a
x
2
∣
∣
w
∣
∣
(5)
_{w,b}^{max} \frac{2}{||w||} \tag{5}
w,bmax∣∣w∣∣2(5)
y
i
(
w
T
x
i
+
b
)
>
=
1
y_i(w^Tx_i+b) >= 1
yi(wTxi+b)>=1
显然,为了最大化间隔,仅需最小化||w||.于是,式(5)可重写为
w
,
b
m
i
n
1
2
∣
∣
w
∣
∣
2
(6)
_{w,b}^{min} \frac{1}{2}||w||^2 \tag{6}
w,bmin21∣∣w∣∣2(6)
y
i
(
w
T
x
i
+
b
)
>
=
1
y_i(w^Tx_i+b) >= 1
yi(wTxi+b)>=1
这就是支持向量机(Supported Vector Machine)的基本型.
对偶问题
我们希望求解式(6)来得到大间隔划分超平面对应的模型
f
(
x
)
=
w
T
x
+
b
(7)
f(x)=w^Tx+b \tag{7}
f(x)=wTx+b(7)
其中w和b是模型参数.
对式(6)使用拉格朗日乘子法可得到其"对偶问题".具体来说,对式(6)的每条约束添加拉格朗日乘子
α
i
≥
0
\alpha_i\ge0
αi≥0,则该问题的拉格朗日函数可写为
L
(
w
,
b
,
α
)
=
1
2
∣
∣
w
∣
∣
2
+
∑
i
=
1
m
α
i
(
1
−
y
i
(
w
T
x
i
+
b
)
)
(8)
L(w,b,\alpha) = \frac{1}{2}||w||^2+\sum_{i=1}^m\alpha_i(1-y_i(w^Tx_i+b)) \tag{8}
L(w,b,α)=21∣∣w∣∣2+i=1∑mαi(1−yi(wTxi+b))(8)
其中
α
=
(
α
1
;
α
2
;
.
.
.
;
α
m
)
\alpha = (\alpha_1;\alpha_2;...;\alpha_m)
α=(α1;α2;...;αm).令
L
(
w
,
b
,
α
)
L(w,b,\alpha)
L(w,b,α)对w和b的偏导为零可得:
∂
L
∂
w
=
w
−
∑
i
=
1
m
α
i
y
i
x
i
=
0
(9)
\frac{\partial L}{\partial w} = w - \sum_{i=1}^m \alpha_iy_ix_i = 0 \tag{9}
∂w∂L=w−i=1∑mαiyixi=0(9)
∂
L
∂
b
=
∑
i
=
1
m
α
i
y
i
=
0
(10)
\frac{\partial L}{\partial b} = \sum_{i=1}^m \alpha_iy_i = 0 \tag{10}
∂b∂L=i=1∑mαiyi=0(10)
将式(9)(10)带入式(8),有:
L
(
w
,
b
,
α
)
=
1
2
∣
∣
w
∣
∣
2
+
∑
i
=
1
m
α
i
(
1
−
y
i
(
w
T
x
i
+
b
)
)
=
1
2
(
∑
i
=
1
m
α
i
y
i
x
i
)
2
+
∑
i
=
1
m
α
i
(
1
−
y
i
(
∑
i
=
1
m
α
i
y
i
x
i
T
x
i
+
b
)
)
=
1
2
∑
i
=
1
m
∑
j
=
1
m
α
i
α
j
y
i
y
j
x
i
T
x
j
+
∑
i
=
1
m
α
i
−
∑
i
=
1
m
α
i
y
i
∑
i
=
1
m
α
i
y
i
x
i
T
x
i
−
∑
i
=
1
m
α
i
y
i
b
=
∑
i
=
1
m
α
i
−
1
2
∑
i
=
1
m
∑
j
=
1
m
α
i
α
j
y
i
y
j
x
i
T
x
j
\begin{aligned} L(w,b,\alpha) &= \frac{1}{2}||w||^2+\sum_{i=1}^m\alpha_i(1-y_i(w^Tx_i+b)) \\ &= \frac{1}{2}(\sum_{i=1}^m \alpha_iy_ix_i)^2 + \sum_{i=1}^m\alpha_i(1-y_i(\sum_{i=1}^m \alpha_iy_ix_i^Tx_i+b)) \\ &= \frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m \alpha_i \alpha_j y_i y_j x_i^T x_j +\sum_{i=1}^m\alpha_i - \sum_{i=1}^m \alpha_i y_i \sum_{i=1}^m \alpha_iy_ix_i^Tx_i -\sum_{i=1}^m \alpha_i y_i b \\ &= \sum_{i=1}^m \alpha_i - \frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m \alpha_i \alpha_j y_i y_j x_i^T x_j \end{aligned}
L(w,b,α)=21∣∣w∣∣2+i=1∑mαi(1−yi(wTxi+b))=21(i=1∑mαiyixi)2+i=1∑mαi(1−yi(i=1∑mαiyixiTxi+b))=21i=1∑mj=1∑mαiαjyiyjxiTxj+i=1∑mαi−i=1∑mαiyii=1∑mαiyixiTxi−i=1∑mαiyib=i=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxj
则将问题转换为式(6)的对偶问题:
α
m
a
x
∑
i
=
1
m
α
i
−
1
2
∑
i
=
1
m
∑
j
=
1
m
α
i
α
j
y
i
y
j
x
i
T
x
j
(11)
_\alpha^{max} \sum_{i=1}^m \alpha_i - \frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m \alpha_i \alpha_j y_i y_j x_i^T x_j \tag{11}
αmaxi=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxj(11)
s
.
t
.
∑
i
=
1
m
α
i
y
i
=
0
,
α
i
≥
0
s.t. \sum_{i=1}^m \alpha_i y_i =0 , \quad \alpha_i \ge 0
s.t.i=1∑mαiyi=0,αi≥0
解出
α
\alpha
α后,求出w和b即可得到模型:
f
(
x
)
=
w
T
x
+
b
=
∑
i
=
1
m
α
i
y
i
x
i
T
x
+
b
(12)
f(x)=w^Tx_+b=\sum_{i=1}^m\alpha_i y_i x_i^Tx+b \tag{12}
f(x)=wTx+b=i=1∑mαiyixiTx+b(12)
从对偶问题解除的
α
\alpha
α是式(8)中的拉格朗日乘子,它对应着训练样本
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi).注意到式(6)中有不等式约束,因此上述过程需满足KKT要求,即:
{
α
i
≥
0
y
i
f
(
x
i
)
−
1
≥
0
α
i
(
y
i
f
(
x
i
)
−
1
)
=
0
(13)
\begin{cases} \alpha_i \ge 0 \\ y_if(x_i)-1 \ge 0 \\ \alpha_i (y_if(x_i)-1) = 0 \tag{13} \end{cases}
⎩⎪⎨⎪⎧αi≥0yif(xi)−1≥0αi(yif(xi)−1)=0(13)
于是,对任意训练样本
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi),总有
α
i
=
0
\alpha_i=0
αi=0或
y
i
f
(
x
i
)
=
1
y_if(x_i)=1
yif(xi)=1.
若
α
i
=
0
\alpha_i=0
αi=0,则该样本不会在式(12)的求和中出现,也就不会对f(x)有任何影响;若
α
i
>
0
\alpha_i>0
αi>0,则必有
y
i
f
(
x
i
)
=
1
y_if(x_i)=1
yif(xi)=1,所对应的样本点位于最大间隔边界上.
这显示出支持向量机的一个重要性质:训练完成后,大部分的训练样本都不需保留,最终模型仅与支持向量有关.
SMO算法
如果求解式(11), SMO(Sequential Minimal Optimization)是其中一个著名高效算法.
SMO的基本思路是先固定
α
i
\alpha_i
αi之外的所有参数,然后求
α
i
\alpha_i
αi上的极值.由于存在约束
∑
i
=
1
m
α
i
y
i
=
0
\sum_{i=1}^m\alpha_i y_i =0
∑i=1mαiyi=0,若固定
α
i
\alpha_i
αi之外的其它变量,则
α
i
\alpha_i
αi可由其它变量导出.
于是,SMO每次选择两个变量
α
i
\alpha_i
αi和
α
j
\alpha_j
αj,并固定其它参数.这样,在参数初始化后,SMO不断执行如下两个步骤直至收敛:
- 选取一对需更新的变量 α i \alpha_i αi和 α j \alpha_j αj
- 固定 α i \alpha_i αi和 α j \alpha_j αj以外的参数,求解式(11)获得更新后的 α i \alpha_i αi和 α j \alpha_j αj
SMO算法之所以高效,恰由于在固定其它参数后,仅优化两个参数的过程能做到非常高效.具体来说,仅考虑
α
i
\alpha_i
αi和
α
j
\alpha_j
αj时,式(11)的约束可重写为
α
i
+
α
j
=
c
,
α
i
≥
0
,
α
j
≥
0
(14)
\alpha_i+\alpha_j =c , \quad \alpha_i \ge 0, \quad \alpha_j \ge 0 \tag{14}
αi+αj=c,αi≥0,αj≥0(14)
其中
c
=
−
∑
k
≠
i
,
j
α
k
y
k
(15)
c = -\sum_{k\neq i,j}\alpha_ky_k \tag{15}
c=−k=i,j∑αkyk(15)
是使
∑
i
=
1
m
α
i
y
i
=
0
\sum_{i=1}^m\alpha_iy_i=0
∑i=1mαiyi=0成立的常数.用式(14)消除式子(11)中的变量
α
j
\alpha_j
αj,则得到一个关于
α
i
\alpha_i
αi的单变量二次规划问题,仅有的约束是
α
i
≥
0
\alpha_i \ge 0
αi≥0.可高效的计算出更新后的
α
i
\alpha_i
αi和
α
j
\alpha_j
αj.
**如何确定偏移项b?**注意到对任意支持向量
(
x
s
,
y
s
)
(x_s,y_s)
(xs,ys)都有
y
s
f
(
x
s
)
=
1
y_sf(x_s)=1
ysf(xs)=1,即:
y
s
(
∑
i
∈
S
α
i
y
i
x
i
T
x
s
+
b
)
=
1
y_s(\sum_{i\in S}\alpha_iy_ix_i^Tx_s+b)=1
ys(i∈S∑αiyixiTxs+b)=1
其中S为所有支持向量的下标集.b的求解通常使用所有支持向量求解的平均值:
b
=
1
∣
S
∣
∑
s
∈
S
(
1
y
s
−
∑
i
∈
S
α
i
y
i
x
i
T
x
s
)
b =\frac{1}{|S|}\sum_{s\in S}(\frac{1}{y_s}-\sum_{i\in S}\alpha_iy_ix_i^Tx_s)
b=∣S∣1s∈S∑(ys1−i∈S∑αiyixiTxs)
核函数
在前面的讨论中,我们假设样本是线性可分的,即存在一个划分超平面能将训练样本正确分类.然而在现实任务中,原始样本空间内也许并不存在一个能正确划分两类样本的超平面.
对于这样的问题,可将样本从原始空间映射到一个更高维的特征空间,是的样本在这个特征空间内线性可分.
令
ϕ
(
x
)
\phi(x)
ϕ(x)表示将x映射后的特征向量,于是,在特征空间中划分超平面所对应的模型可表示为
f
(
x
)
=
w
T
ϕ
(
x
)
+
b
(19)
f(x)=w^T\phi(x)+b \tag{19}
f(x)=wTϕ(x)+b(19)
其中w和b是模型参数,类似于式(6),有:
w
,
b
m
i
n
1
2
∣
∣
w
∣
∣
2
(20)
_{w,b}^{min} \frac{1}{2}||w||^2 \tag{20}
w,bmin21∣∣w∣∣2(20)
y
i
(
w
T
ϕ
(
x
i
)
+
b
)
>
=
1
y_i(w^T\phi(x_i)+b) >= 1
yi(wTϕ(xi)+b)>=1
其对偶问题是:
α
m
a
x
∑
i
=
1
m
α
i
−
1
2
∑
i
=
1
m
∑
j
=
1
m
α
i
α
j
y
i
y
j
ϕ
(
x
i
)
T
ϕ
(
x
j
)
(21)
_\alpha^{max} \sum_{i=1}^m \alpha_i - \frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m \alpha_i \alpha_j y_i y_j \phi(x_i)^T \phi(x_j) \tag{21}
αmaxi=1∑mαi−21i=1∑mj=1∑mαiαjyiyjϕ(xi)Tϕ(xj)(21)
s
.
t
.
∑
i
=
1
m
α
i
y
i
=
0
,
α
i
≥
0
s.t. \sum_{i=1}^m \alpha_i y_i =0 , \quad \alpha_i \ge 0
s.t.i=1∑mαiyi=0,αi≥0
求解式(21)涉及到计算
ϕ
(
x
i
)
T
ϕ
(
x
j
)
\phi(x_i)^T \phi(x_j)
ϕ(xi)Tϕ(xj),这是样本
x
i
x_i
xi与
x
j
x_j
xj映射到特征空间之后的内积.由于特征空间维数可能很高,甚至可能是无穷维,因此直接计算
ϕ
(
x
i
)
T
ϕ
(
x
j
)
\phi(x_i)^T \phi(x_j)
ϕ(xi)Tϕ(xj)通常是苦难的.为了避开这个障碍,可以设想这样一个函数:
β
(
x
i
,
x
j
)
=
<
ϕ
(
x
i
)
,
ϕ
(
x
j
)
>
=
ϕ
(
x
i
)
T
ϕ
(
x
j
)
(22)
\beta(x_i,x_j)=<\phi(x_i),\phi(x_j)>=\phi(x_i)^T\phi(x_j) \tag{22}
β(xi,xj)=<ϕ(xi),ϕ(xj)>=ϕ(xi)Tϕ(xj)(22)
即
x
i
x_i
xi与
x
j
x_j
xj在特征空间的内积等于它们在原始样本空间通过函数
β
(
.
,
.
)
\beta(.,.)
β(.,.)计算的结果.有了这样的函数,我们就不必直接去计算高维甚至无穷维特征空间中的内积,于是式(21)可重写为:
α
m
a
x
∑
i
=
1
m
α
i
−
1
2
∑
i
=
1
m
∑
j
=
1
m
α
i
α
j
y
i
y
j
β
(
x
i
,
x
j
)
(23)
_\alpha^{max} \sum_{i=1}^m \alpha_i - \frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m \alpha_i \alpha_j y_i y_j \beta(x_i,x_j) \tag{23}
αmaxi=1∑mαi−21i=1∑mj=1∑mαiαjyiyjβ(xi,xj)(23)
s
.
t
.
∑
i
=
1
m
α
i
y
i
=
0
,
α
i
≥
0
s.t. \sum_{i=1}^m \alpha_i y_i =0 , \quad \alpha_i \ge 0
s.t.i=1∑mαiyi=0,αi≥0
求解后即可得到:
f
(
x
)
=
w
T
ϕ
(
x
)
+
b
=
∑
i
=
1
m
α
i
y
i
ϕ
(
x
i
)
T
ϕ
(
x
)
+
b
=
∑
i
=
1
m
α
i
y
i
β
(
x
,
x
i
)
+
b
(24)
\begin{aligned} f(x)&= w^T\phi(x)+b \\ &= \sum_{i=1}^m\alpha_i y_i \phi(x_i)^T\phi(x)+b \\ &= \sum_{i=1}^m\alpha_i y_i \beta(x,x_i)+b \tag{24} \end{aligned}
f(x)=wTϕ(x)+b=i=1∑mαiyiϕ(xi)Tϕ(x)+b=i=1∑mαiyiβ(x,xi)+b(24)
这里的函数
β
(
.
,
.
)
\beta(.,.)
β(.,.)就是"核函数".














 418
418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









